12 Best ETL Tools Reviewed for 2026

Best ETL Tools Shortlist
Here’s my shortlist of the best ETL tools:


The best ETL tools help teams automatically extract data from multiple sources, clean and format it, and load it into data warehouses or analytics systems for real-time insights. They make it easier to maintain consistent, accurate datasets while cutting down on manual data wrangling and repetitive pipeline maintenance.
Teams usually start searching for ETL solutions when they’re spending too much time fixing broken pipelines, dealing with mismatched data formats, or waiting hours for reports to update. Manual processes and legacy scripts often can’t keep up with modern data volume or frequency, leading to delays, errors, and unreliable dashboards.
I’ve worked with data engineering and analytics teams to implement and optimize ETL workflows across cloud and on-prem environments, testing tools for scalability, transformation flexibility, and ease of integration with modern data stacks.
In this guide, you’ll learn which ETL platforms actually make your data operations faster, more reliable, and easier to maintain without adding unnecessary complexity.
Why Trust Our Software Reviews
We’ve been testing and reviewing software since 2023. As tech leaders ourselves, we know how critical and difficult it is to make the right decision when selecting software.
We invest in deep research to help our audience make better software purchasing decisions. We’ve tested more than 2,000 tools for different tech use cases and written over 1,000 comprehensive software reviews. Learn how we stay transparent & our software review methodology.
Best ETL Tools Shortlist Summary
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | Best for multi-source data extraction | Free demo available | Pricing upon request | Website | |
| 2 | Best for integrating spreadsheets with data sources | Free plan available | From $49/month (billed annually) | Website | |
| 3 | Best for reliable enterprise data pipelines | 14-day free trial + Free demo available | From $239/month (billed annually) | Website | |
| 4 | Best for extensive data transformations | free demo available | From $1,999/month | Website | |
| 5 | Best drag-and-drop console | Free plan available | From $0.60/month (for low-frequency activities) | Website | |
| 6 | Best serverless ETL tool | Free plan available | From $0.44/DPU-hour | Website | |
| 7 | Best for batch data extractions | Free trial + free demo available | Pricing upon request | Website | |
| 8 | Best for large data storage | Not available | Free to use | Website | |
| 9 | Best for integrations | Free demo available | Pricing upon request | Website | |
| 10 | Best for combining data | No free trial | $1.913/hour (Enterprise) | Website | |
| 11 | Best for large enterprises | Free demo available | Pricing upon request | Website | |
| 12 | Best data connectivity | Free plan available | Pricing upon request | Website |
-

Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8 -
Docker
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.6


Best ETL Tools Reviews
Below are my detailed summaries of the best ETL tools that made it onto my shortlist. My reviews offer a detailed look at the key features, pros & cons, integrations, and ideal use cases of each tool to help you find the best one for you.

Adverity is a data platform designed to help teams manage and make sense of their data. It offers tools to collect, process, and distribute data, aiming to make it easier for users to work with their information.
Why I picked Adverity: I picked Adverity because it lets you extract data from multiple sources, transform it based on your own rules, and load it into your preferred destinations. Its connect feature helps bring all your data together, giving you a complete view of what you're working with. The transform feature is useful for cleaning and standardizing data before analysis, which is key to any ETL workflow. You can also automate these steps to keep data pipelines running smoothly. These capabilities make it a solid fit for teams looking to manage ETL processes more efficiently.
Adverity Standout Features and Integrations:
Features include monitoring, which helps users keep track of their data's status and quality. This can assist in identifying any issues or inconsistencies in the data. Additionally, the share feature allows teams to distribute their data to various destinations, facilitating collaboration and further analysis.
Integrations include Google, Meta, TikTok, Google BigQuery, Looker Studio, Facebook Ads, Amazon Advertising, Hubspot, Salesforce, Amazon S3, Snowflake, and Microsoft Azure.
Pros and Cons
Pros:
- Provides the ability to create personalized dashboards
- Can harmonize data from various sources
- Automated data quality monitoring
Cons:
- The initial setup can be time-consuming
- Certain configurations may require technical knowledge
New Product Updates from Adverity
Adverity Enables Smart Scheduling in API
Adverity's Management API now includes smart schedule functionality, enhancing automation for data fetching. For more information, visit Adverity's official site.
 .
.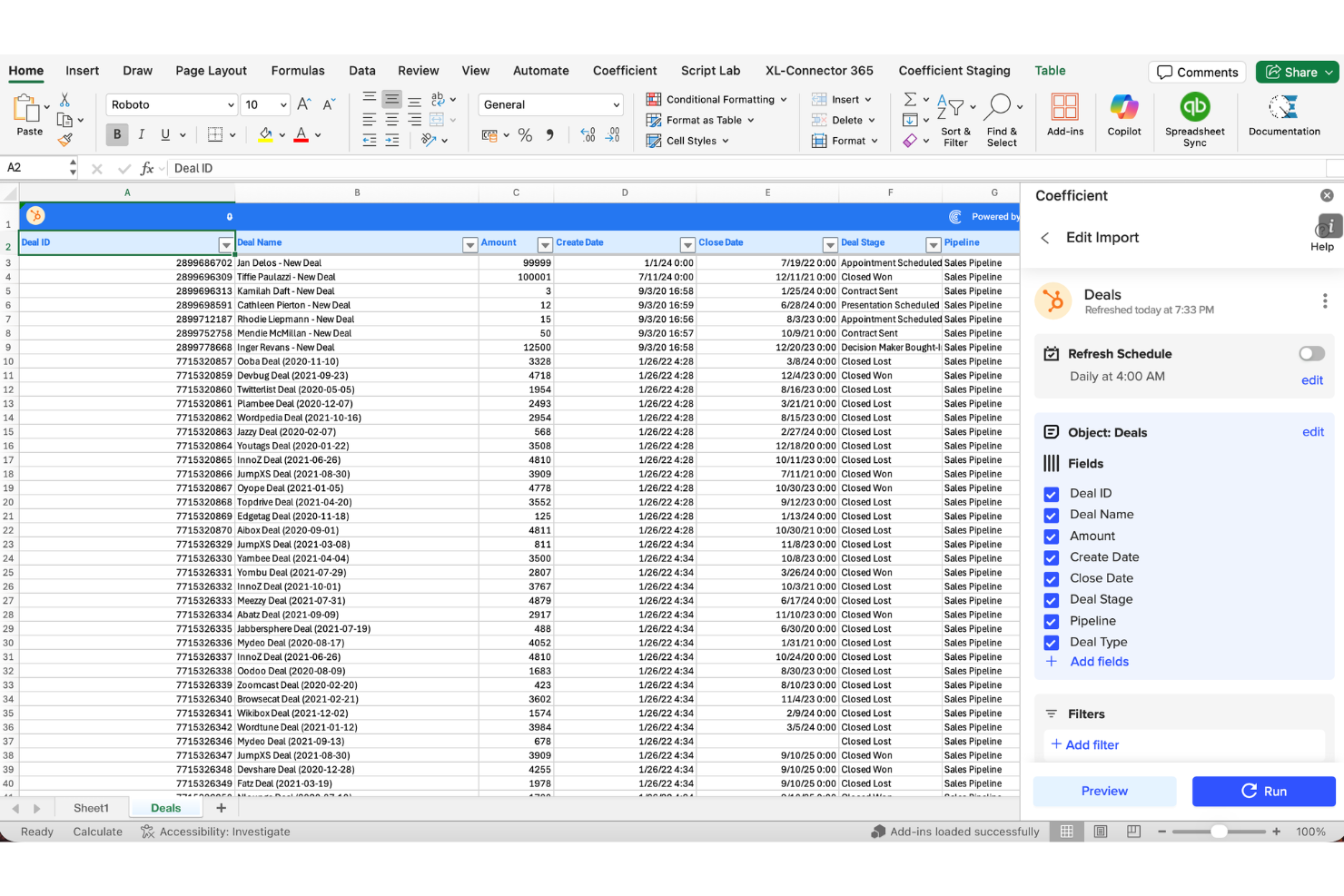
For professionals seeking efficient ETL solutions, Coefficient offers a compelling choice by integrating Google Sheets and Excel with over 100 data sources. It is particularly appealing to businesses in finance, marketing, and revenue operations, where real-time data analysis and automation are crucial. By eliminating the need for coding, Coefficient simplifies the creation of complex data applications, addressing challenges such as data management and productivity enhancement.
Why I Picked Coefficient
I picked Coefficient for its unique ability to connect spreadsheets to a vast array of data sources, which is essential for any ETL tool. Its features, like formula preservation and data snapshotting, stand out by allowing teams to manage and transform data effortlessly. What's more, the inclusion of tools like the Google Sheets Assistant and SQL Query Builder further supports users in handling complex data tasks without requiring extensive technical expertise. As a result, these capabilities make Coefficient a valuable asset for businesses looking to optimize their data workflows.
Coefficient Key Features
In addition to its integration capabilities, Coefficient offers several noteworthy features:
- Live data analysis: Work with real-time business data directly within spreadsheets.
- AI-powered dashboards: Create dynamic dashboards that automatically update with the latest insights.
- Connect to any API: Pull data from custom or internal systems without building separate pipelines.
- No-code application creation: Build data applications such as commission trackers and marketing dashboards without coding.
Coefficient Integrations
Integrations include Salesforce, QuickBooks, Snowflake, HubSpot, Google Analytics, Slack, Stripe, Shopify, and more.
Pros and Cons
Pros:
- Supports both pre-built and API-based integrations
- Makes live business data accessible without heavy pipelines
- Reduces manual refreshes and repetitive reporting tasks
Cons:
- Best suited for business-friendly ETL workflows
- Less suitable for highly specialized data infrastructure

Hevo is a no-code ETL and data integration platform designed for businesses seeking to automate data pipelines. It supports enterprises by enabling connections with over 150 data sources without the need for coding, enhancing data management efficiency.
Why I picked Hevo: Built on a Kafka-based architecture, Hevo delivers data with low latency, ensuring that your analytics and business decisions are based on the most current information. This real-time processing is crucial for applications that require up-to-date data. With over 150 pre-built connectors, it facilitates data extraction and integration from diverse platforms, supporting businesses that rely on multiple data sources. Additionally, Hevo automatically detects the schema of your source data and replicates it to your destination, keeping your data warehouse in sync even as source data structures change.
Hevo Standout Features and Integrations:
Features include pre-load and post-load data transformations that let you clean, format, and standardize your data either before it lands in your warehouse or after, ensuring it's analytics-ready. Hevo also offers a REST API, allowing you to integrate it into your existing workflows and trigger pipelines programmatically.
Integrations include MongoDB, Google Analytics, Salesforce, HubSpot, Azure Synapse Analytics, BigQuery, Snowflake, Redshift, Mailchimp, Klaviyo, WordPress, Pipedrive, and more.
Pros and Cons
Pros:
- Automated schema management and error handling
- Real-time data synchronization
- The platform supports a wide range of data sources
Cons:
- Pricing may be a concern for small businesses
- Editing established pipelines can be challenging

Integrate.io is a cloud-based ETL platform designed to help you organize and prepare data for analytics and business intelligence. It offers a low-code environment that simplifies building and managing pipelines across a wide range of sources, including relational databases, NoSQL stores, file systems, object stores, and ad platforms.
Why I Picked Integrate.io: One reason I chose Integrate.io is its support for over 220 built-in transformations. This extensive library allows your team to perform complex data manipulations without writing code, making it easier to prepare data for analysis. Its low-code transformation layer also reduces the need for SQL or scripting, offering flexibility for both technical and non-technical users.
Integrate.io Standout Features and Integrations
Features include support for operational ETL use cases, such as automating bidirectional Salesforce integrations and enabling B2B file data sharing. It also supports multi-cloud, multi-region deployments across the US, EU, and APAC, which can help distributed teams meet performance and compliance needs.
Integrations include Salesforce, HubSpot, Google Analytics, Facebook Ads, Amazon Redshift, Google BigQuery, Amazon S3, Snowflake, MySQL, PostgreSQL, Microsoft Azure SQL Database, and MongoDB.
Pros and Cons
Pros:
- REST API access for automation
- Strong security features and compliance standards
- Low-code environment reduces need for scripting
Cons:
- Potential performance issues with large datasets
- May still come with a learning curve for non-technical users

AWS Data Pipeline is a managed ETL tool that allows you to transfer data between AWS services and other on-premise resources. It lets you specify the data you want to move, define transformation jobs or queries, and set schedules for performing these transformations.
Why I picked AWS Data Pipeline: What I really like about AWS Data Pipeline is its user-friendly drag-and-drop console that lets you simplify the process of building and managing your pipelines. It also offers fault-tolerant and customization capabilities that ensure smooth data pipeline operations.
AWS Data Pipeline Standout Features and Integrations:
Features of AWS Data Pipeline that stood out to me were its drag-and-drop UI and high fault tolerance. The drag-and-drop capability makes its console quite convenient to use, while the added fault tolerance helps in minimizing the impact of user errors.
Integrations for AWS Data Pipeline include Redshift, SQL, and DynamoDB. Such connectors are available as pre-built options when using the platform.
Pros and Cons
Pros:
- High fault tolerance and customization capabilities
- Lets you specify the data you wish to move
- Easy drag-and-drop console that simplifies processes
Cons:
- Doesn’t support third-party data
- Managing data can be time-consuming

AWS Glue provides access to a serverless data integration service that simplifies the process of discovering, preparing, handling, and integrating data from different sources. Its visual interface lets you facilitate the loading of data into your data lakes, ensuring data is readily available for analysis.
Why I picked AWS Glue: I chose AWS Glue because of its access to more than 70 data sources while efficiently managing your data using a centralized data catalog. It can even scale up or down depending on the current demands of your organization. These capabilities are the reasons why I believe AWS Glue is the best serverless ETL tool on this list.
AWS Glue Standout Features and Integrations:
Features of AWS Glue that stood out to me were its access to multiple data stores and ability to build complex ETL pipelines. Being able to tap into different data sources makes business intelligence gathering more convenient while developing complex pipelines can result in more in-depth insights.
Integrations for AWS Glue include MySQL, Oracle, Redshift, Amazon S3, and more. All these connectors come pre-built when you choose the platform.
Pros and Cons
Pros:
- Easy maintenance and deployment
- Provides filtering for faulty data
- Failed jobs in AWS Glue can be retrieved
Cons:
- Not the best choice for real-time ETL jobs
- Lacks compatibility with commonly used data sources

IBM DataStage is an ETL tool that allows you to extract, transform, apply business principles, and effortlessly load the data into any desired target. It has a basic version of the software that you can install on-premises and an upgrade that lets you reduce data integration time and expenses.
Why I picked IBM DataStage: I decided on IBM DataStage because it is an integration tool that excels at integrating data from a vast range of enterprise and external sources. I like how it is well-equipped to handle the processing and transformation of large data volumes, thanks to its scalable parallel processing approach.
IBM DataStage Standout Features and Integrations:
Features of IBM DataStage that stood out to me were its data science and automated load balancing. I found that its data science feature allows me to quickly derive insights from my data, while the automated load balancing helps me get the most throughput.
Integrations are available with Amazon S3, Azure, BDFS, BigQuery, and FTP Enterprise. You can also link up and transfer data with data sources like IBM Db2 Warehouse on Cloud and IBM Netezza. All of these integrations are pre-built into the platform.
Pros and Cons
Pros:
- Access to AI services
- Reduced data movement costs
- Workload balancing allows users to run workloads faster
Cons:
- Editing columns can be tedious
- Lacks automation for error handling and recovery

Hadoop is an open-source ETL tool that lets you store and process data. Instead of relying on a single computer, the software allows you to cluster multiple devices together, enabling fast analysis and storage of huge datasets.
Why I picked Hadoop: I chose Hadoop because it provides access to extensive storage capacity capable of accommodating any type of data. The tool offers immense processing power, allowing you to handle an extraordinary number of concurrent tasks or jobs.
Hadoop Standout Features and Integrations:
Features of Hadoop that stood out to me were its cluster job scheduling and access to common Java libraries. I found that these capabilities allowed the platform to quickly process large datasets, which matches well with its significant data storage capacity.
Integrations for Hadoop include MySQL, PostgreSQL, and Oracle. All these connectors are pre-built into the platform.
Pros and Cons
Pros:
- Highly scalable ETL tool
- Can deal with any kind of dataset
- Can process a huge amount of data simultaneously
Cons:
- Not ideal for smaller datasets
- Java framework can be easily exploited

Oracle Data Integrator caters to various data integration needs. It handles everything from large-scale batch loads with high performance to real-time event-driven integration and even SOA-enabled data services.
Why I picked Oracle Data Integrator: I chose Oracle Data Integrator because it offers a range of pre-built connectors that you can use to effortlessly link various databases. It allows you to readily connect with Hadoop, EREPs, CRMs, XML, JSON, LDAP, JDBC, and ODBC, right out of the box.
Oracle Data Integrator Standout Features and Integrations:
Features of Oracle Data Integrator that stood out to me were its active integration platform and its ability to allow developers to create their own mappings through standard business logic. The active integration feature allows data-based, event-based, and service-based data integrations, while the latter lets them produce code for a wide range of data processing technologies.
Integrations are available with data warehouse platforms such as Oracle, Teradata, IBM DB2, Sybase, and Exadata. You can also use it to work with other technologies such as ERPs, XML, and LDAP. All of these integrations are pre-built into the platform.
Pros and Cons
Pros:
- Supports all platforms, hardware, and operating systems
- Automatically detects faulty data before application insertion
- Efficient architecture that uses both source and target servers
Cons:
- User interface can be complex
- Difficult to learn and requires training
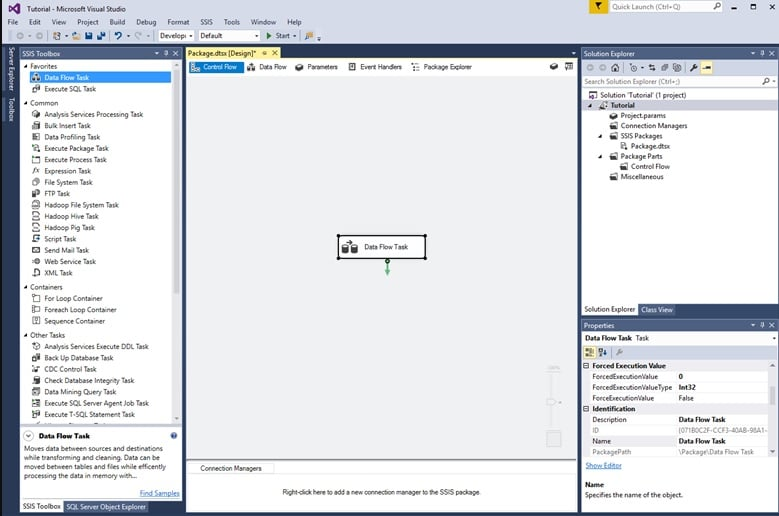
Microsoft SQL Server Integration Services, simply called Microsoft SSIS, is an enterprise tool that integrates, transforms, and migrates data within Microsoft’s SQL Server database. It offers integration-related capabilities, such as data analysis, cleansing, and performing ETL processes to update data warehouses.
Why I picked Microsoft SSIS: A major reason why I chose SSIS is because of its versatility, supporting various databases like SQL, DB2, and Oracle. Such flexibility allows users to combine data from different sources, while its graphical interface makes it easier to accomplish data warehousing tasks and transformations.
Microsoft SSIS Standout Features and Integrations:
Features of Microsoft SSIS that stood out to me were its graphical tools and built-in catalog database. The graphical tools make it easy to develop packages, while the SSIS catalog database makes it easy to manage projects, parameters, and environments. I also liked how the platform lets you import data from different sources and transform them the way you want.
Integrations are available for Microsoft SSIS with ADO, DQS, Excel, FTP, HTTP, WMI, and more. These connectors come pre-built into the platform. You can also download additional types of connection managers from their website.
Pros and Cons
Pros:
- Provides users with a number of documentation features
- UI is easy to use and configure
- A flexible ETL and data transformation tool
Cons:
- Only supports Microsoft Windows
- Lacks integration options with other tools

SAS Data Management is an integration platform designed to connect with data from diverse sources, including cloud platforms, legacy systems, and data lakes. It optimizes workflows by leveraging reusable data management rules, making it ideal for large enterprises with complex data integration processes.
Why I picked SAS Data Management: I chose SAS Data Management because it eliminates the need to build ETL pipelines, allowing you to easily connect with various data sources and transport data to different destinations. I found that its exceptional speed in transferring analytics data from source to warehouse can be useful for large organizations that want to quickly generate valuable reports and visualizations using business intelligence tools.
SAS Data Management Standout Features and Integrations:
Features of SAS Data Management that stood out to me were its ability to let users customize metadata and access audit history. Having the capacity to modify server metadata lets you configure a server according to your requirements. Additionally, being able to view your audit trails can provide operational integrity as well as proof of compliance for major corporations.
Integrations for SAS Data Management include Hadoop, Impala, ODBC, Oracle, PostgreSQL, and more. These connectors are pre-built within the platform and do not require a third-party integration manager.
Pros and Cons
Pros:
- Exceptional analytics data transfer speed
- Non-technical stakeholders can easily start using it
- Easy connectivity with various data sources
Cons:
- Can be quite costly
- Needs third-party drivers to connect with other data sources

Fivetran is an automated data integration platform that lets you consolidate and synchronize data from various sources. It has over 160 data connectors that let you simplify the process of moving data between different cloud data platforms.
Why I picked Fivetran: The primary goal of Fivetran is to streamline your data management by offering a set of user-friendly tools. I chose the software because of its relative ease in staying up-to-date with API changes and efficiently retrieving the latest data from databases within minutes.
Fivetran Standout Features and Integrations:
Features of Fivetran that stood out to me were its quickstart data models and automated schema drift handling. The quickstart models let me create tables ready for analytics in a short amount of time. Meanwhile, the handling of schema drift allows the platform to automatically copy any changes made while backfilling applicable data.
Integrations for Fivetran include BigQuery, Redshift, Snowflake, and Azure. These database connectors are all pre-built into the platform and are fully managed as well. It also integrates with many SaaS applications like Airtable and Asana.
Pros and Cons
Pros:
- Excellent customer support services
- Offers customizable security features
- Can synchronize with various data sources
Cons:
- Syncing a lot of data can be costly
- Data transformation support is limited
Other ETL Tools
Besides the ones above, I’ve also shortlisted a few more ETL tools that are worth checking out:
- Talend Open Studio
Data handling time
- Informatica PowerCenter
In parsing advanced data formats
- Pentaho Data Integration
User-friendly interface
- Stitch Data
For automated data pipelines
- Apache Airflow
For data pipeline orchestrations
- Azure Data Factory
For business and IT-led data analytics
- SAP Data Services
For data cleansing
- Google Cloud Dataflow
For real-time data streaming
- Qlik Compose
For leveraging proven design patterns


{kind=link}
Related IT Software Reviews
If you still haven't found what you're looking for here, check out these tools closely related to API Management, that we've tested and evaluated.
- Network Monitoring Software
- Server Monitoring Software
- SD-Wan Solutions
- Infrastructure Monitoring Tools
- Packet Sniffer
- Application Monitoring Tools
Selection Criteria for ETL Tools
When selecting ETL tools, I focus on functionality and how well they meet specific use cases. My criteria are based on extensive personal research and hands-on experience with various ETL solutions. Here's an overview of my methodology for selecting tools to include in my list:
Core ETL tools Functionality: 25% of total weighting score
To be considered for inclusion on my list of the best ETL tools, the solution had to support one or more of these common use cases:
- Efficient data integration from diverse sources
- Scalable data transformations
- Automated data workflows
- Real-time data processing and analytics
- Ensuring data quality and compliance
Additional Standout Features: 25% of total weighting score
- Tools that offer advanced data transformation logic, such as fuzzy matching and machine learning capabilities for predictive modeling.
- Solutions with extensive pre-built connectors to new and emerging data sources like IoT devices or blockchain platforms.
- ETL platforms that provide unique data visualization tools for monitoring data flows and performance in real time.
- Innovative approaches to data governance and compliance, ensuring data is not only secure but also meets global regulatory standards.
- Examples include tools that leverage AI to enhance data quality checks or platforms that offer in-depth customization options allowing businesses to tailor the tool to their specific needs.
Usability: 10% of total weighting score
- Interfaces that simplify complex processes, like drag-and-drop functionality for designing data pipelines.
- Clear, intuitive dashboard designs that provide quick access to frequently used features.
- Responsive design that works well across different devices, enabling users to manage ETL tasks on the go.
Onboarding: 10% of total weighting score
- Availability of comprehensive training materials, such as video tutorials, documentation, and interactive product tours.
- Templates and pre-configured workflows to help new users get started with common ETL challenges and tasks quickly.
- Access to customer support or community forums during the onboarding process to ensure smooth transition and immediate problem solving.
Customer Support: 10% of total weighting score
- Offering various channels for support, including live chat, phone support, and email, to accommodate different user preferences.
- Proactive support, such as regular check-ins and updates on new features or best practices.
- A knowledgeable and responsive support team that can assist with both technical and operational queries.
Value For Money: 10% of total weighting score
- Transparent pricing models that align with the features and scalability offered.
- Consideration of long-term value through flexible plans that grow with the user’s needs.
- Free trials or demos that allow users to assess the tool’s effectiveness before committing financially.
Customer Reviews: 10% of total weighting score
- Consistently high ratings in areas critical to ETL processes, such as reliability, performance, and user satisfaction.
- Positive feedback on ease of use and customer support responsiveness.
- Reviews that highlight successful use cases similar to the buyer's needs, indicating the tool’s capability to solve specific problems.
This criteria framework ensures that ETL tools are evaluated comprehensively, focusing on both their core functionalities and additional features that distinguish them in the market, such as ETL testing automation tools. It addresses the full spectrum of buyer concerns, from initial onboarding to long-term value, ensuring that the selected ETL tool not only meets your immediate data management needs but also supports future growth and complexity.
How to Choose ETL Tools
As you're shortlisting, trialing, and selecting ETL tools, consider the following:
- What problem are you trying to solve - Start by identifying the ETL pipeline management feature gap you're trying to fill to clarify the features and functionality the tool needs to provide.
- Who will need to use it - To evaluate cost and requirements, consider who'll be using the tool and how many licenses you'll need. You'll need to evaluate if it'll just be the data department, or the whole organization that will require access. When that's clear, it's worth considering if you're prioritizing ease of use for all, or speed for your technical power users.
- What other tools it needs to work with - Clarify what tools you're replacing, what tools are staying, and the tools you'll need to integrate with. This could include your existing ETL infrastructure, various data sources, and your overall tech stack. You might also need to decide if the tools will need to integrate together, or alternatively, if you can replace multiple tools with one consolidated ETL tool.
- What outcomes are important - Consider the result that the tool needs to deliver to be considered a success. Think about what capability you want to gain, or what you want to improve, and how you will be measuring success. You could compare ETL tool features until you’re blue in the face, but if you aren’t thinking about the outcomes you want to drive, you could be wasting a lot of valuable time.
- How it would work within your organization - Consider the solutions alongside your workflows and ETL methodology. Evaluate what's working well, and the areas that are causing issues that need to be addressed. Remember every business is different — don’t assume that because a tool is popular that it'll work in your organization.
Trends in ETL Tools
In my research, I sourced countless product updates, press releases, and release logs from different ETL tool vendors. Here are some of the emerging trends I’m keeping an eye on:
- Real-time data processing: More ETL tools are moving from batch to real-time data processing, helping businesses make quicker decisions based on live data.
- AI-powered data transformation: Some vendors are adding AI capabilities to automate complex data transformation tasks, reducing the need for manual coding.
- Data quality monitoring: ETL tools are starting to include built-in data validation and quality checks, helping teams catch errors and inconsistencies before they affect downstream systems.
- Self-service ETL: Vendors are focusing on making ETL tools more user-friendly, so business teams without technical expertise can handle data extraction and transformation.
- Hybrid and multi-cloud support: With more companies using multiple cloud platforms, ETL tools are adapting by offering better support for hybrid and multi-cloud environments.
What Are ETL Tools?
ETL tools are software that help move data from different sources, clean and format it, and load it into a system where it can be used. They're used by data engineers, analysts, and IT teams who need to prepare data for reporting, dashboards, or machine learning.
Features like data extraction, transformation rules, and automated scheduling help with reducing manual work, fixing errors, and making sure data is ready when it's needed. These tools make it easier to work with data without having to build everything from scratch.
Features of ETL Tools
Here are some of the most important features I look for when evaluating extract, transform, and load (ETL) tools:
- Intuitive User Interface (UI): An easy-to-use and understand interface simplifies the creation and management of ETL processes. It allows users with varying levels of technical expertise to efficiently work with data.
- Connectivity and Integration: The ability to connect to a wide range of data sources and destinations. This feature is key for businesses that collect data from multiple sources and need to ensure seamless integration across platforms.
- Data Transformation Capabilities: Powerful data transformation features enable the conversion of data into the required format with ease. This is vital for preparing data accurately for analysis and reporting.
- Automation and Scheduling: Tools that offer automation and scheduling capabilities allow for the ETL processes to run at predetermined times or in response to specific triggers. This reduces manual effort and ensures data is always up-to-date.
- Scalability: The capacity to scale up or down based on data volume and computational needs. As data volumes grow, a scalable ETL tool can handle increased loads without compromising performance.
- Real-time Processing: Support for real-time data processing enables businesses to make decisions based on the most current data. This is crucial for time-sensitive applications where up-to-the-minute data is required.
- Data Quality and Cleansing: Features that support data cleansing and ensure quality are essential. They help in identifying and correcting errors or inconsistencies in data, ensuring that only reliable data is used for analysis.
- Security: Robust security features, including data encryption and access controls, protect sensitive information from unauthorized access. Security is non-negotiable for compliance with regulations and safeguarding business data.
- Monitoring and Logging: The ability to monitor ETL processes in real-time and log activities for audit trails. This helps in troubleshooting issues and ensuring transparency in data operations.
- Support and Community: Strong customer support and an active user community can greatly assist in resolving issues and sharing best practices. This is beneficial for continuous learning and overcoming challenges in managing ETL pipelines.
Benefits of ETL Tools
ETL tools play a crucial role in the modern data-driven business landscape, enabling organizations to efficiently manage vast amounts of data from various sources. These tools streamline the process of extracting data, transforming it into a usable format, and loading it into a data warehouse or other storage solutions. Here are five primary benefits of ETL tools for users and organizations:
- Increased Efficiency: ETL tools automate the process of data extraction, transformation, and loading, significantly reducing the time and effort required compared to manual processes. This automation allows businesses to rapidly process large volumes of data, improving productivity and operational efficiency.
- Improved Data Quality: By providing functionalities for data cleansing and validation, ETL tools help ensure the accuracy and reliability of data. Improved data quality leads to better decision-making and can significantly reduce the costs associated with errors and inaccuracies in data.
- Enhanced Scalability: ETL tools are designed to handle data of varying volumes, from small to large datasets, without compromising performance. This scalability supports business growth, as organizations can easily adjust to increased data volumes without needing to overhaul their data processing infrastructure.
- Data Integration from Multiple Sources: ETL tools can extract data from diverse sources, including databases, cloud services, and applications, and consolidate it into a single repository. This integration capability enables businesses to gain a holistic view of their operations, enhancing analytics and reporting capabilities.
- Increased Data Security: Many ETL tools include robust security features, such as encryption and access controls, to protect sensitive information during the data handling process. This increased data security helps organizations comply with data protection regulations and safeguard against data breaches.
Costs & Pricing for ETL Tools
When venturing into the realm of ETL tools, it's crucial for software buyers, especially those with little to no experience, to understand the various plan and pricing options available. Pricing and plans can vary widely based on features, scalability, support, and other factors.
Plan Comparison Table for ETL Tools
Below is a detailed overview of common plan options for ETL tools, aimed at helping you make an informed decision that aligns with your organizational needs and budget constraints.
| Plan Type | Average Price | Common Features | Best For |
|---|---|---|---|
| Free | $0 | Access to basic ETL functionalities, limited data volume processing, community support. | Small businesses with minimal data integration needs, individual developers, open source enthusiasts |
| Basic | $500 - $2,000 / month | Standard ETL features, support for multiple data sources, email support, basic data transformation capabilities. | Startups, small to medium-sized businesses with growing data needs, organizations with limited IT resources |
| Professional | $2,001 - $10,000 / month | Advanced data transformations, real-time data processing, higher data volume capacity, priority customer support. | Medium-sized businesses with complex data integration requirements, enterprises with multiple data sources and formats |
| Enterprise | $10,001+ / month | Custom ETL solutions, dedicated support, unlimited data volume, advanced security features, API access. | Large enterprises with massive data volumes, complex data integration needs, high security requirements |
ETL Tools FAQs
The following are the answers to the most frequently asked questions about ETL tools:
How do you implement an ETL tool?
How do ETL tools ensure data security?
Can ETL tools handle large data volumes?
How much do ETL tools cost?
How can you improve ETL performance?
How do I choose the right ETL tool for my needs?
What's Next?
If you're in the process of researching ETL tools, connect with a SoftwareSelect advisor for free recommendations.
You fill out a form and have a quick chat where they get into the specifics of your needs. Then you'll get a shortlist of software to review. They'll even support you through the entire buying process, including price negotiations.