10 Best NoSQL Databases Reviewed for 2026

Best NoSQL Databases Shortlist


The best NoSQL databases help teams handle large, unstructured, or rapidly changing datasets without the rigid schema requirements of traditional relational systems. They enable faster queries, easier scaling, and better support for distributed architectures, which are essential for modern use cases like real-time analytics, content management, and IoT data processing.
Teams often start looking for NoSQL solutions when they hit the limits of relational databases: slow queries under high load, schema changes that break workflows, or difficulties syncing data across regions. Challenges like inconsistent performance, data replication issues, and complex scaling requirements can make managing growth much harder without the right platform.
I’ve worked with engineering and data teams evaluating NoSQL databases for everything from analytics pipelines to high-traffic web apps, testing their performance, replication setups, and integration with cloud environments.
In this guide, you’ll learn which NoSQL databases deliver strong performance, simplify scaling, and support the data flexibility your applications actually need.
Why Trust Our Software Reviews
We’ve been testing and reviewing software since 2023. As tech leaders ourselves, we know how critical and difficult it is to make the right decision when selecting software.
We invest in deep research to help our audience make better software purchasing decisions. We’ve tested more than 2,000 tools for different tech use cases and written over 1,000 comprehensive software reviews. Learn how we stay transparent & our software review methodology.
Best NoSQL Databases Summary
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | Best serverless NoSQL database | Free tier available | From $1/month | Website | |
| 2 | Best NoSQL database for fully-functional ACID transactions | Free versions available | From $789/core/year | Website | |
| 3 | Best wide-column NoSQL database | Free version available | No paid plan | Website | |
| 4 | Best NoSQL database for user-friendliness | Free plan available | Pricing upon request | Website | |
| 5 | Best column-oriented database for storing very large datasets | Free version available | No paid option | Website | |
| 6 | Best document-based NoSQL database | Free version available | From $57/month or serverless from $0.10/million reads | Website | |
| 7 | Best cloud- and grid-based NoSQL database | Free version available | Fixed license from $15,456/year | Website | |
| 8 | Best graph-based NoSQL database | Free version available | Pricing upon request | Website | |
| 9 | Best for SQL-like functionality | Free trial available | From $0.28/hr per node | Website | |
| 10 | Best key-value NoSQL database | Free version available | From $7/month or $0.881/hour | Website |
-

TestDevLab
Visit Website -
Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8


Best NoSQL Database Reviews
Here are my recommendations of the 12 best NoSQL databases and the scenarios where I think each one performs best.
IBM Cloudant is on my list because it’s one of the few NoSQL databases that scales elastically as a pure serverless offering. For teams running distributed apps that need global throughput and managed replication, Cloudant’s auto-sharding and always-on availability just work. I appreciate how you never manage infrastructure, even with unpredictable growth or large-scale workloads.
IBM Cloudant's Best For
- Apps needing high availability and serverless scaling
- Teams building distributed, globally accessible NoSQL stores
IBM Cloudant's Not Great For
- Workloads needing complex relational queries or joins
- On-premises deployments or strict data residency requirements
What sets IBM Cloudant apart
Cloudant’s core idea is simple: you focus only on your data and APIs, and it handles the infrastructure underneath. Unlike MongoDB, which expects you to manage sharding, scaling, or patching, Cloudant takes full responsibility for keeping things responsive and distributed. This works best when you want to prioritize global access, uptime, and low operational burden.
Tradeoffs with IBM Cloudant
Cloudant optimizes for serverless managed infrastructure, so you lose out on the depth of customization or control you’d get from a self-managed NoSQL database. This limits advanced schema tuning or low-level database operations.
Pros and Cons
Pros:
- Free version available
- Serverless schema for easy configuration
- Comprehensive security
Cons:
- Slow time to index large databases
- Some documentation is out of date
RavenDB earned its spot because it’s the only NoSQL database I’ve worked with that delivers full ACID transactions without compromising performance. For teams building apps that demand transactional integrity, especially when handling aggregate updates across documents, RavenDB works reliably without the usual trade-offs. I have a lot of respect for how it handles distributed transactions and real-time replication, setting a high bar for data consistency and safety.
RavenDB's Best For
- Applications that require fully-ACID NoSQL transactions
- Teams handling complex, multi-document updates
RavenDB's Not Great For
- Simple key-value storage use cases
- Projects needing broad, out-of-the-box cloud integrations
What sets RavenDB apart
RavenDB approaches NoSQL data with a focus on transactional safety, which sets it apart from MongoDB or Couchbase that emphasize performance or breadth of data models. Rather than treating transactions as an advanced or add-on feature, it expects you to treat ACID guarantees as essential to your workflow. In practice, this works best if your team is already used to thinking with relational database habits and wants predictable data consistency in a document environment.
Tradeoffs with RavenDB
RavenDB optimizes for transactional integrity, but you lose out on the simpler deployment and broad cloud service integrations that you’d get from trendier NoSQL options. If you want fast onboarding with ready integrations, you’ll find setup more involved here.
Pros and Cons
Pros:
- On-premise and cloud versions
- ACID transactions ensure greater data consistency and time-saving
- Easy-to-use interface
Cons:
- Lacking community support and documentation
- Enterprise version is expensive
CASSANDRA earns its spot here because it handles massive, high-velocity write workloads better than any other NoSQL database I've tested. I tend to recommend it when your team needs linear scalability for time-series data or IoT, and you want tunable consistency across regions.
What I appreciate most is how CASSANDRA's wide-column architecture handles huge datasets while staying responsive at scale.
CASSANDRA’s Best For
- High-throughput IoT, time-series, or event data workloads
- Distributed apps that need scalable, multi-region data stores
CASSANDRA’s Not Great For
- Relational data models or SQL-style joins
- Small teams without infrastructure expertise
What sets CASSANDRA apart
CASSANDRA is designed for massive scale and always-on availability, so it assumes you need to write and read data across lots of nodes without hiccups. Unlike MongoDB, which centers collections and document formats, CASSANDRA expects you to plan data up front as wide tables for fast ingest and retrieval. This approach works best when your workload is all about speed and horizontal scaling, not flexible ad-hoc queries.
Tradeoffs with CASSANDRA
CASSANDRA optimizes for scale and partition tolerance, but you lose the rich querying and join logic found in traditional relational or document-oriented databases. That makes reporting and on-the-fly data exploration much more difficult.
Pros and Cons
Pros:
- Horizontal scaling to accommodate growing data needs
- Can handle large volumes of unstructured data
- Support for hybrid cloud (private and public) and on-premises
Cons:
- Requires periodic manual maintenance
- No ad-hoc queries
Amazon DynamoDB stands out to me because of how well it abstracts infrastructure management for teams adopting NoSQL. I see teams gravitate toward it when they want to handle high-velocity workloads and need built-in scaling for unpredictable traffic.
What I like most is the automatic capacity management and global tables for cross-region replication—it takes a lot off your plate. You can focus on building features instead of wrestling with manual sharding or provisioning.
Amazon DynamoDB’s Best For
- Applications with unpredictable, high-velocity, or spiky traffic
- Teams needing automated scaling and global replication
Amazon DynamoDB’s Not Great For
- Workloads requiring multi-table joins or complex queries
- Teams wanting relational database features or SQL compatibility
What sets Amazon DynamoDB apart
DynamoDB is designed around high-scale, event-driven workloads where you want to write and read fast without managing any servers. It assumes you’re indexing data on key attributes and working in single-table, high-velocity patterns, more like a managed key-value store than a classical NoSQL database like MongoDB. Instead of expecting flexibility in querying or structure, DynamoDB leans hard into reliability, sharding, and global distribution.
Tradeoffs with Amazon DynamoDB
DynamoDB optimizes for speed and scale, but you give up relational-style joins and flexible ad hoc queries. This means you’ll need to rethink data modeling if you’re used to SQL or applications that rely on complex relationships.
Pros and Cons
Pros:
- AWS integration to extend functionality
- Strong documentation and support
- Easy to set up and use
Cons:
- Limited to AWS cloud
- No on-premises option

HBase makes this list because it’s designed specifically for storing and retrieving massive volumes of sparse, distributed data. I recommend it to teams running analytics, IoT, or compliance workloads where you need fast access to wide tables across clusters.
I really appreciate how HBase handles horizontal scaling and strong consistency. It lets you store petabytes reliably and run real-time queries, even as your data keeps growing.
HBase’s Best For
- Storing high-volume, wide-column datasets in real time
- Data warehousing, analytics, and IoT workloads at scale
HBase’s Not Great For
- Simple key-value or document-centric data models
- Projects needing SQL-based queries and transactions
What sets HBase apart
HBase is set up for massive scale and expects you to think in terms of column families and distributed storage rather than traditional tables. Unlike MongoDB, which works well for quick document modeling, HBase fits when you want to store trillions of rows and need consistent, low-latency lookups across petabytes of data. In practice, this is good for streaming analytics or sensor data you want to keep accessible.
Tradeoffs with HBase
HBase optimizes for scale and throughput, but that means you lose convenient querying and flexible data modeling found in document stores. For anyone who's used to SQL-like workflows, this approach can slow down development and increases the need for careful schema planning.
Pros and Cons
Pros:
- Horizontally scalable across thousands of servers
- Integration with Apache Hadoop
- Free to use
Cons:
- CPU and memory intensive
- Fewer built-in features than Cassandra – relies on third-party integration
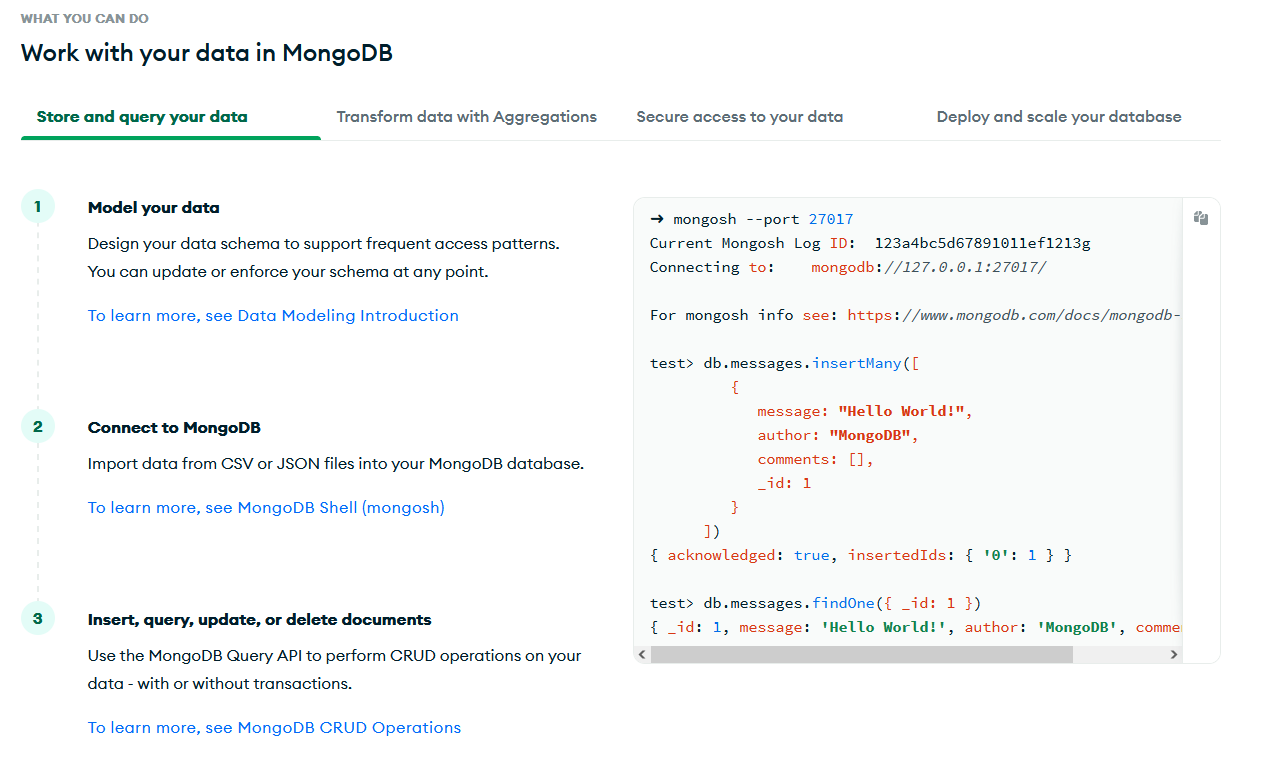
MongoDB makes my shortlist because of how well it handles document-based NoSQL workloads at scale. It uses flexible JSON-like documents instead of rigid tables, so you can easily map complex, nested data with changing schemas.
What I really appreciate is replica set support and automatic sharding. It works well when teams need fast, scalable storage for high-volume applications or data logging.
MongoDB’s Best For
- Teams needing fast, flexible document-oriented data storage
- Scale-out applications with dynamic or complex schemas
MongoDB’s Not Great For
- Workloads requiring strict multi-row transactional consistency
- Heavy relational data with complex join requirements
What sets MongoDB apart
MongoDB encourages you to think in documents, not tables, letting you store complex, nested data as single objects that reflect your application's structure. In practice, this makes it much more natural when you're working with applications that change frequently, like content management or event logging.
Unlike relational databases such as MySQL, you don't have to design rigid schemas. That flexibility is something I find especially helpful when your data shape isn't stable.
Tradeoffs with MongoDB
MongoDB optimizes for schema flexibility and horizontal scaling, but you lose join-heavy relational logic and strict multi-document transaction guarantees—meaning it's not a great fit if your workflows depend on transactional integrity across many documents.
Pros and Cons
Pros:
- No predetermined schema improves flexibility and scalability
- Comprehensive documentation and large community support
- BSON widens data type support while reducing parsing
Cons:
- Some performance issues with larger databases
- BSON uses up more storage space than JSON
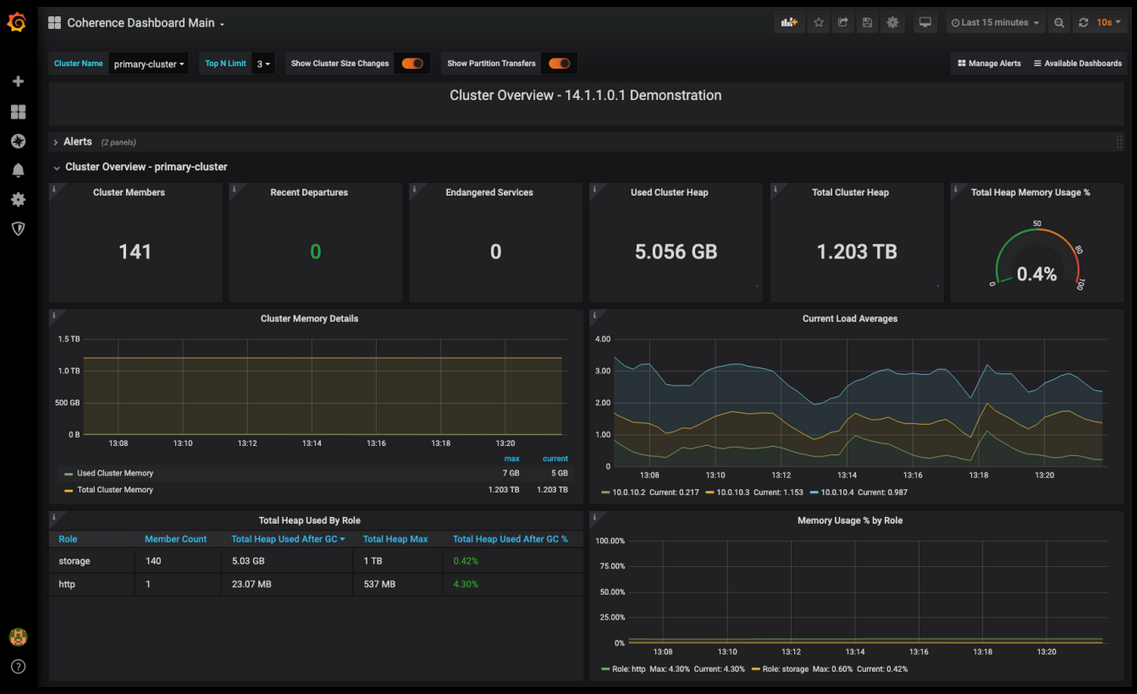
Oracle Coherence is one of my top picks when organizations need an in-memory data grid that scales across cloud and on-prem environments. What I find distinguishing is its focus on elastic clustering and real-time data availability, even under unpredictable loads.
I especially appreciate its native integration with Oracle Cloud, which makes it straightforward for teams handling complex transactional workloads or high-volume, low-latency use cases across distributed systems.
Oracle Coherence’s Best For
- Enterprises running high-throughput, mission-critical applications
- Teams needing real-time data grids across cloud and on-prem
Oracle Coherence’s Not Great For
- Small projects with low scalability requirements
- Teams seeking a simple, one-click NoSQL deployment
What sets Oracle Coherence apart
Oracle Coherence is built for organizations that treat distributed, real-time data as core infrastructure. Instead of the plug-and-play approach you get from MongoDB or DynamoDB, Coherence expects you to architect systems that match demanding, high-throughput scenarios. I notice it’s structured for use cases where low latency matters more than flexibility or ease of setup.
It stands out when compared to Redis, which handles caching but isn’t as focused on clustering for large, transactional systems.
Tradeoffs with Oracle Coherence
Coherence optimizes for scale and configurability, but that means the setup and maintenance require more expertise and ongoing tuning than more straightforward NoSQL options.
Pros and Cons
Pros:
- Strong community support and documentation
- Many features to maintain data consistency
- Free to use
Cons:
- Difficult upgrade process
- Limited default security
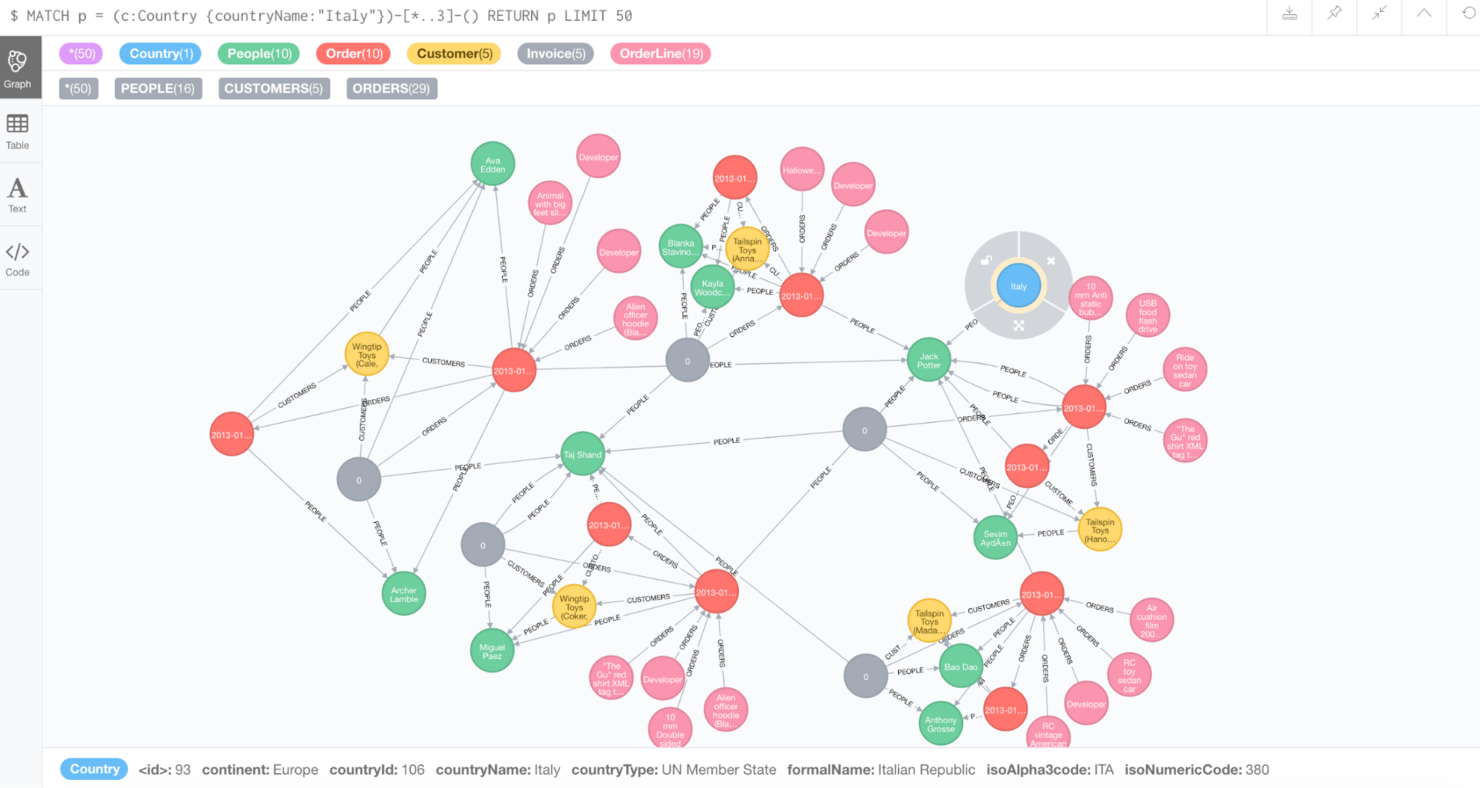
Neo4j earns a spot here thanks to its dedicated graph-based data model, which is different from most NoSQL options. I see teams get the most value out of Neo4j when they need to model and query deeply connected data, like IT asset relationships, authorization mapping, or fraud path detection.
What I like most is the Cypher query language and real-time traversal capabilities, which let you uncover complex patterns across huge datasets without a ton of custom code.
Neo4j’s Best For
- Modeling and querying complex, highly connected data sets
- IT, security, or analytics teams mapping real-world relationships
Neo4j’s Not Great For
- Workloads needing simple key-value or document storage
- Teams without graph data needs or experience with graph queries
What sets Neo4j apart
Neo4j centers its model around relationships between data points, not just storage of values or documents. Unlike MongoDB or Cassandra, it pushes you to think in terms of connected entities and how they interact. This works well when your work is about mapping real-world networks—users, assets, permissions, or dependencies—where pathfinding or understanding relationship patterns is central.
Tradeoffs with Neo4j
Neo4j optimizes for exploring and analyzing connections, but the graph mindset adds complexity for simple storage and CRUD. If your use case is straightforward data retrieval, it usually feels like more database than you need.
Pros and Cons
Pros:
- Surprisingly easy to learn and use
- Strong community and documentation
- ACID transactions ensure database operations happen across all nodes
Cons:
- New versions can introduce new errors
- Custom pricing for Enterprise edition

Couchbase Capella makes my cut because it’s one of the few NoSQL platforms that brings familiar SQL-style querying to distributed JSON data. I like how Capella’s N1QL language lets teams run expressive queries, joins, and aggregations that usually aren’t easy in NoSQL databases. This is where I recommend it to teams who need NoSQL flexibility but can’t drop their SQL skillset.
Couchbase Capella’s Best For
- Teams using SQL skills with NoSQL data models
- Large-scale applications needing flexible queries and high performance
Couchbase Capella’s Not Great For
- Small projects with minimal querying needs
- Simple workloads where relational databases are enough
What sets Couchbase Capella apart
Capella is designed for teams that want to use flexible NoSQL databases but keep their familiar SQL-style approach to data modeling and querying. Instead of letting go of concepts like joins, aggregations, or ad hoc searches, you keep them with N1QL. It feels familiar if you come from a MySQL or PostgreSQL background. Compared to something like MongoDB, you can express more logic in a single query.
Tradeoffs with Couchbase Capella
Capella optimizes for SQL-like querying over distributed JSON data, but the extra expressiveness adds overhead and complexity if you just need a basic key-value or document store.
Pros and Cons
Pros:
- Great value for money
- Built-in app development and deployment service
- Combines the benefits of SQL and NoSQL databases in one platform
Cons:
- Limited integrations
- Steep learning curve
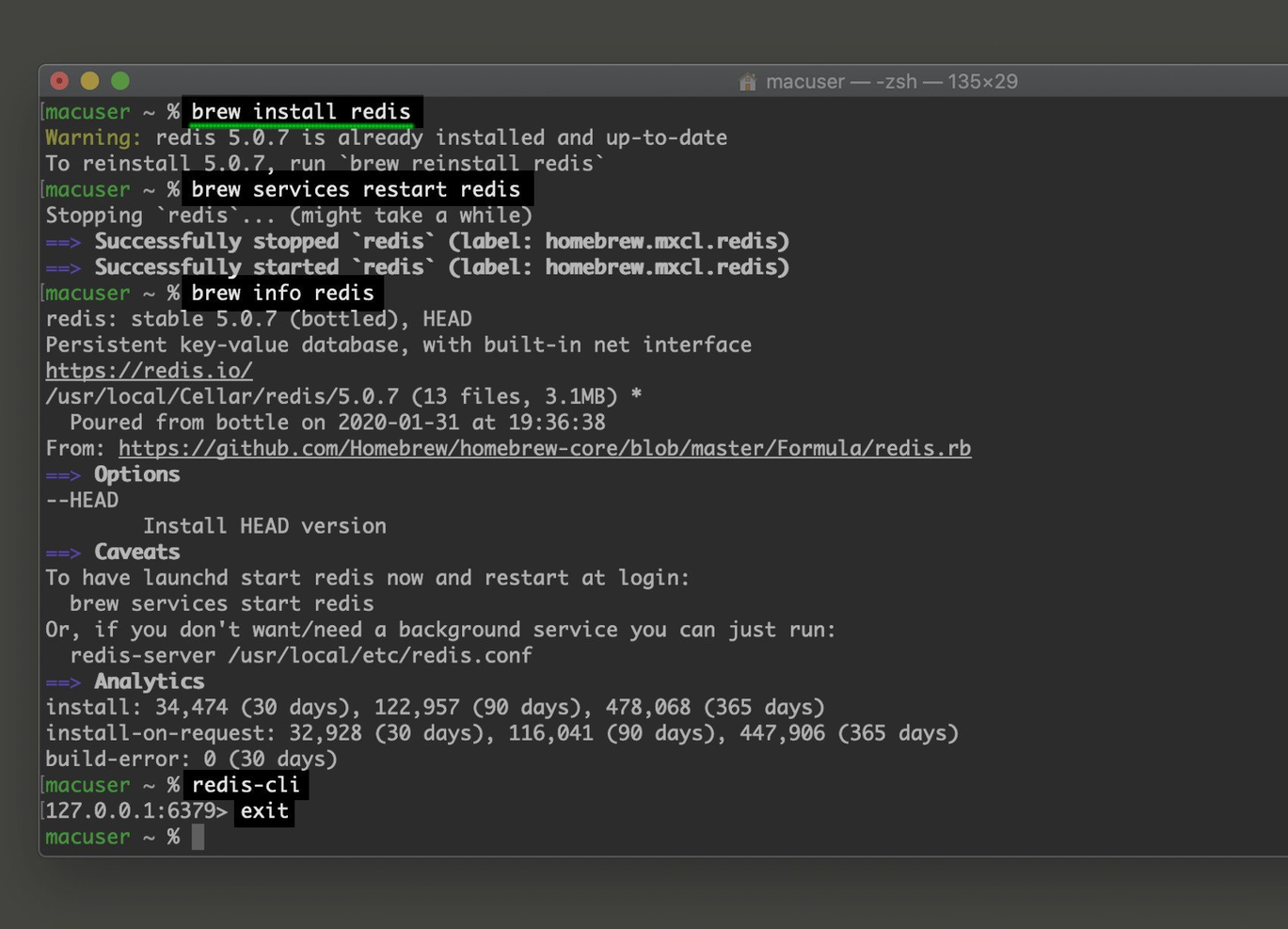
Redis is here because I see teams pick it when performance and fast response times for key-value storage are critical. It's my go-to for scenarios that need high-throughput caching or real-time analytics, where milliseconds matter.
I like how Redis combines in-memory speed with features like persistence, replication, and pub/sub messaging. When performance bottlenecks show up, especially at web scale, this is almost always the first NoSQL tool I recommend.
Redis’s Best For
- High-volume caching and real-time analytics workloads
- Developers building fast, scalable key-value applications
Redis’s Not Great For
- Projects needing complex queries or secondary indexes
- Organizations requiring relational data models
What sets Redis apart
Redis is focused on simple key-value workloads that depend on consistently fast response times. Unlike MongoDB, which supports flexible schemas and broader data structures, Redis wants you to build around in-memory storage with straightforward access patterns. In practice, this works best for caching, queueing, or session storage, where you want quick reads and writes with minimal complexity.
Tradeoffs with Redis
Redis optimizes for speed and simplicity, so you give up advanced querying and complex data relationships—if you need more than quick lookups, you’ll run into limits fast.
Pros and Cons
Pros:
- Automatic failover guarantees high availability
- Useful for real-time applications such as gaming leaderboards and analytics
- In-memory data storage delivers fast performance
Cons:
- Lack of documentation
- No Graphical User Interface (GUI)
Other NoSQL Databases
Below is a list of alternative NoSQL databases that I also recommend:
- OrientDB
Multi-model NoSQL database
- Elasticsearch
Search-based document database
- Aerospike
For reducing server and cloud footprint
- InterSystems Caché
For managing transactional and historical data
- ScyllaDB
Fastest distributed database
- AstraDB
For real-time app building and scaling
- DataStax Enterprise
For zero server downtime
- Dgraph
For fault tolerance
- Apache Drill
Schema-free database
- MarkLogic Server
For simplifying complex data
- Riak
For unstructured data management


{kind=link}
Related Software & Tool Reviews
If you still haven't found what you're looking for here, check out these other types of tools that we've tested and evaluated.
- Network Monitoring Software
- Server Monitoring Software
- SD-Wan Solutions
- Infrastructure Monitoring Tools
- Packet Sniffer
- Application Monitoring Tools
How I Evaluate NoSQL Databases
I split my evaluation into baseline requirements—like horizontal scaling and flexible data models—and the differentiators that separate tools built for real-time, high-throughput workloads.
Core Functionality (Table Stakes For This List)
When I'm selecting tools for my list, I rank each one on a scale from 0 (does not offer the functionality) to 5 (excels in this area) for each core functionality listed below. Then, I calculate the tool's total score into a percentage. Each tool needs to achieve a minimum total score of 75% to be considered for inclusion.
- Flexible Data Model: I check whether a database supports document, key-value, wide-column, or graph structures—and whether it handles schema evolution without forced migrations.
- Horizontal Scalability: Distributing data across nodes matters for growing workloads, so I evaluate how each tool handles sharding, partitioning, and elastic cluster expansion.
- High Availability & Replication: I look at failover behavior and replication options, especially for multi-region setups where an outage in one zone can't take your application offline.
- Query & Indexing Capabilities: Beyond basic key lookups, I evaluate secondary indexing, aggregation pipelines, and filtering—features you'll rely on for analytics dashboards or search.
- Performance at Scale: Latency and throughput under heavy concurrent loads tell you a lot, so I compare documented benchmarks and real-world behavior at high data volumes.
- Developer APIs & SDK Support: Good language coverage across Python, Java, Node.js, Go, and others speeds up adoption, so I check official SDK quality and API documentation depth.
Once I have a list of tools that meet this criteria, I consider what sets each platform apart.
Differentiating Factors (What Sets Vendors Apart)
Here's how I compare and contrast different vendors:
Standout Features
Tunable consistency is a meaningful differentiator. I evaluate whether a database lets you configure consistency per query—useful when real-time reads and background analytics coexist. Built-in vector search matters for teams building AI-powered features like recommendation engines or semantic search without bolting on extra tools. I also check for native change data capture, since streaming data mutations to platforms like Kafka is essential for event-driven architectures.
Beyond Features
Deployment flexibility is something I weigh early—whether a database runs as a managed cloud service, on-premise, or across multiple providers shapes how well it fits your infrastructure strategy. Security and compliance also factor in heavily; I check for RBAC, encryption at rest and in transit, and certifications like SOC 2 or HIPAA for teams handling sensitive data. Ecosystem depth rounds out the picture. Connectors for Kafka, Terraform providers, and Kubernetes operators tell you how smoothly a database slots into existing DevOps workflows.
How to Choose a NoSQL Database
As you're shortlisting, trialing, and selecting NoSQL databases, consider the following:
- What problem are you trying to solve - Start by identifying the NoSQL database feature gap you're trying to fill to clarify the features and functionality the tool needs to provide.
- Who will need to use it - To evaluate cost and requirements, consider who'll be using the platform and how many licenses you'll need. You'll need to evaluate if it'll just be the data team or the whole organization that will require access. When that's clear, it's worth considering if you're prioritizing ease of use for all, or speed for your technical power users.
- What other tools it needs to work with - Clarify what tools you're replacing, what tools are staying, and the tools you'll need to integrate with. This could include your existing data infrastructure, various data sources, and your overall tech stack. You might also need to decide if the tools will need to integrate together, or alternatively, if you can replace multiple tools with one consolidated NoSQL database.
- What outcomes are important - Consider the result that the tool needs to deliver to be considered a success. Think about what capability you want to gain, or what you want to improve, and how you will be measuring success. You could compare NoSQL database features until you’re blue in the face, but if you aren’t thinking about the outcomes you want to drive, you could be wasting a lot of valuable time.
- How it would work within your organization - Consider the solutions alongside your workflows and data management methodology. Evaluate what's working well, and the areas that are causing issues that need to be addressed. Remember every business is different — don’t assume that because a tool is popular that it'll work in your organization.
Trends in NoSQL Database
In my research, I sourced countless product updates, press releases, and release logs from different NoSQL database vendors. Here are some of the emerging trends I’m keeping an eye on:
- Edge-ready databases: Some NoSQL tools now support edge computing setups where data is stored and processed closer to users. It’s useful for apps with low-latency requirements or remote deployments.
- Multi-model support: More NoSQL databases are adding support for multiple data models like key-value, document, graph, and column in one system. This gives teams flexibility to run different types of workloads without switching platforms.
- Serverless architecture: Some vendors now offer serverless NoSQL databases that scale automatically and charge based on usage. It's a good option for teams that don’t want to manage infrastructure, like with Amazon DynamoDB or Azure Cosmos DB.
- Stronger consistency options: Traditionally, NoSQL prioritized availability over consistency, but now tools are offering tunable consistency levels. This helps when you need more control over how fresh or accurate your data reads are.
- Built-in full-text search: Vendors are starting to bake in search functionality so you don’t have to bolt on a separate engine like Elasticsearch. This saves setup time and keeps everything in one place.
What Are NoSQL Databases?
No Structured Query Language (SQL) databases are non-relational databases that allow for the storage, retrieval, and management of data without the need for a fixed schema. These tools are primarily used by software developers, data architects, and IT professionals who deal with large volumes of structured, semi-structured, or unstructured data.
The shift towards NoSQL databases is driven by the need to address the limitations of traditional relational databases in handling the volume, velocity, and variety of today's data. The overall value of these tools lies in their ability to provide robust, flexible, and cost-effective solutions for complex data management needs across various industries.
Features of NoSQL Databases
Here are the most important features I look for when I'm evaluating NoSQL databases:
- Scalability: This feature allows for the database to expand according to the growing data needs. The ability to scale out using distributed architecture is essential for handling vast amounts of data seamlessly, without compromising on performance.
- Flexible Data Models: NoSQL databases offer flexible data models for storing and managing diverse data types. This flexibility is crucial for accommodating the varied and dynamic nature of unstructured data without the need for predefined schemas.
- High Performance: Optimized for specific data models and access patterns, ensuring quick data retrieval and high throughput. High performance is key in scenarios where time-sensitive access to data is critical for decision-making and operational efficiency.
- High Availability: This feature ensures that the database remains accessible even in the face of hardware failures or maintenance events. High availability is critical for applications requiring constant uptime and real-time access to data.
- Data Replication: Facilitates the copying of data across multiple servers, enhancing data availability and disaster recovery. Data replication is important for maintaining data integrity and ensuring continuous access to data across geographically distributed systems.
- Partition Tolerance: The ability to continue operating despite network or partition failures. Partition tolerance is essential in distributed systems, ensuring that the system remains operational even when parts of it are not communicating effectively.
- Multi-Model Support: Supports various data models like document, key-value, graph, and column-family within a single database. Multi-model support provides the versatility to handle different types of data and access patterns, simplifying the data architecture.
- Schema-less: Allows the storage of data without a predefined schema, offering flexibility in handling changes to data structures. Schema-less databases are ideal for applications that require the ability to evolve rapidly without the need for frequent database redesigns.
- Integrated Caching: Improves performance by storing frequently accessed data in memory. Integrated caching reduces data access times significantly, enhancing the user experience and system efficiency.
- Security Features: Comprehensive security measures including encryption, access control, and auditing. Robust security features protect sensitive data from unauthorized access and breaches, which is crucial for maintaining trust and compliance.
Benefits of NoSQL Databases
NoSQL databases offer a flexible, scalable, and efficient way to manage data, making them an attractive option for organizations and developers dealing with large volumes of diverse data types. Unlike traditional relational databases, NoSQL databases are designed to handle unstructured and semi-structured data, offering unique advantages that can significantly enhance business operations and data management strategies. Here are five primary benefits of NoSQL databases for users and organizations:
- Scalability: Easily manage data growth with distributed architecture. NoSQL databases are inherently designed to scale out across multiple servers and data centers, allowing businesses to handle increasing volumes of data without a hitch, supporting growth and ensuring performance is maintained.
- Flexibility: Adapt to changing data models without downtime. The schema-less nature of NoSQL databases allows for the storage of unstructured and semi-structured data, providing the flexibility to rapidly evolve your application without the need to modify a rigid database schema, thus accelerating development cycles.
- High Performance: Achieve faster data access and processing. NoSQL databases can provide superior performance for certain types of operations, including those involving large volumes of data and real-time applications, by leveraging optimized storage, caching, and retrieval mechanisms tailored to specific data models.
- Cost-Effectiveness: Reduce costs with efficient data storage and processing. The distributed nature of NoSQL databases, combined with their ability to efficiently manage large volumes of diverse data, can lead to significant cost savings in hardware, storage, and maintenance compared to traditional database systems.
- Data Variety Handling: Store and query a wide range of data types. NoSQL databases support multiple data models, including key-value, document, wide-column, and graph formats, enabling organizations to leverage a single database for a variety of data types and applications, simplifying data management and enhancing analytical capabilities.
Costs & Pricing For NoSQL Databases
NoSQL databases offer a variety of plan and pricing options designed to accommodate the needs of businesses of all sizes, from startups to large enterprises. These databases are tailored to manage large volumes of structured and unstructured data efficiently, offering scalability, flexibility, and high performance.
The pricing models vary significantly among different NoSQL database providers, typically based on factors such as data storage, read/write throughput, number of transactions, and level of support required.
Plan Comparison Table For NoSQL Databases
Here's a summary overview of the different pricing plans and cost ranges typically available for these tools:
| Plan Type | Average Price | Common Features |
|---|---|---|
| Free | $0 | Basic access, limited storage and throughput, community support |
| Standard | $100 - $1,000/month | Increased storage and throughput, technical support, basic security |
| Professional | $1,000 - $10,000/month | Enhanced security features, higher throughput and storage limits, 24/7 support |
| Enterprise | Custom pricing | Customized solutions, dedicated support, unlimited storage and throughput |
NoSQL Database FAQs
Here are the most common questions that people ask when searching for information on NoSQL databases.
How do I decide which NoSQL database type to use for my tech stack?
Start by mapping your core use cases like real-time analytics, content management, or distributed caching to NoSQL database categories (document, key-value, column, graph, etc.). Assess data structure, scalability needs, and integration with your existing architecture. Benchmark leading tools for compatibility with your programming language and cloud stack. If you’re unsure, run proofs of concept with shortlisted options and involve your engineering leads early.
What are the scaling limitations of NoSQL databases in enterprise deployments?
NoSQL databases usually scale horizontally, but limitations arise from factors like network latency, data partitioning, and management complexity at massive scale. Some have hard limits on cluster size, secondary indexes, or geographic distribution consistency. Before choosing a database, test its scaling behavior under enterprise loads and review real-world case studies from companies with similar requirements.
Can NoSQL databases support ACID transactions for critical workloads?
Yes, some NoSQL databases offer ACID-compliant transactions, but support varies by platform and configuration. Document and graph databases often provide local or clustered transactions while key-value stores may emphasize eventual consistency. If you need strict ACID guarantees enterprise-wide, evaluate each tool’s transaction model carefully and run sample workloads to test fit.
What security practices should CTOs follow when deploying NoSQL databases?
Always enforce authentication and role-based access. Enable encryption for data at rest and in transit. Regularly update database software to patch vulnerabilities. Limit network exposure—run services on private subnets or use VPNs. Monitor logs and set alerts for suspicious activity. Review vendor security guides for compliance with your company’s standards, and audit deployments quarterly.
How do I migrate from a relational database to NoSQL without disrupting operations?
Successful migration starts with careful schema mapping and phased rollouts. Run parallel systems and sync data in real time during the transition. Automate data transformation using specialized migration tools or custom scripts. Test your new system thoroughly with real workloads to minimize downtime. Throughout, keep your team updated and provide rollback plans if issues arise.
What's Next?
If you're in the process of researching nosql database, connect with a SoftwareSelect advisor for free recommendations.
You fill out a form and have a quick chat where they get into the specifics of your needs. Then you'll get a shortlist of software to review. They'll even support you through the entire buying process, including price negotiations.