AI di livello superiore: I 10 migliori software di deep learning del 2026

Migliori Software di Deep Learning: Lista Ristretta


Sfruttando la potenza dell'intelligenza artificiale, un software di deep learning è lo strumento ideale per risolvere i problemi aziendali più complessi. Grazie a framework di calcolo ad alte prestazioni e a tutorial dedicati, anche una startup può costruire reti neurali convoluzionali e ricorrenti (RNN), abilitando funzionalità transformative per il riconoscimento delle immagini.
Una piattaforma AI di questo genere favorisce la modularità con moduli indipendenti e analisi predittive, diventando una pietra miliare per l’attività di data mining. Le sue funzionalità "no code" e la gestione dei problemi di big data tramite Spark la rendono semplice da usare mantenendo efficiente l’utilizzo della CPU. Lavorare con nodi o applicazioni di apprendimento come Javascript non è mai stato così facile, consentendoti di esplorare facilmente il mondo della regressione e delle analisi predittive.
Perché Fidarti delle Nostre Recensioni Software
Testiamo e recensiamo software dal 2023. Come leader tecnologici, sappiamo quanto sia cruciale e difficile prendere la decisione giusta nella scelta di un software.
Investiamo in una ricerca approfondita per aiutare il nostro pubblico a effettuare scelte migliori di acquisto software. Abbiamo testato oltre 2.000 strumenti per diversi casi d’uso tecnologici e scritto più di 1.000 recensioni complete. Scopri come restiamo trasparenti e la nostra metodologia di recensione del software.
Riepilogo dei Migliori Software di Deep Learning
Questa tabella comparativa riassume i dettagli relativi ai prezzi delle mie migliori scelte di software di deep learning per aiutarti a trovare quella più adatta al tuo budget e alle esigenze della tua azienda.
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | Ideale per soluzioni di analisi video enterprise-scale | Piano gratuito disponibile | Da $47.85/mese | Website | |
| 2 | Ideale per lo sviluppo di machine learning guidato da esperimenti | No | $39/utente/mese (fatturato annualmente) | Website | |
| 3 | Ideale per l'etichettatura e annotazione automatizzata dei dati in ambito IA | Not available | $49/user/month | Website | |
| 4 | Ideale per gestire, automatizzare e accelerare i workflow di ML | No | Su richiesta | Website | |
| 5 | Ideale per sfruttare strumenti potenti di AI e Deep Learning accelerati tramite GPU | Not available | $0.09 per GPU ora | Website | |
| 6 | Ideale per calcoli simbolici e numerici nel deep learning | Not available | $25/user/month (fatturato annualmente) | Website | |
| 7 | Ideale per la prototipazione e la produzione rapida di reti neurali | Not available | Gratuito | Website | |
| 8 | Ideale per accedere a set di dati umani annotati, diversificati e su larga scala | Not available | Su richiesta | Website | |
| 9 | Ideale per lo sviluppo avanzato di algoritmi con librerie estese | No | Gratuito | Website | |
| 10 | Ideale per migliorare i risultati dell'apprendimento tramite l'apprendimento adattivo guidato dall'IA | Not available | Su richiesta | Website |
-

TestDevLab
Visit Website -
Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8


Recensioni dei Migliori Software di Deep Learning
Qui sotto trovi i miei riepiloghi dettagliati dei migliori software di deep learning che sono entrati nella mia lista ristretta. Le mie recensioni offrono una panoramica sulle caratteristiche principali, pro e contro, integrazioni e casi d’uso ottimali di ciascun tool per aiutarti a scegliere quello giusto per te.

TwelveLabs è una piattaforma di intelligenza artificiale video basata su modelli fondamentali di deep learning multimodale—Marengo e Pegasus—che fornisce agli sviluppatori accesso API per la ricerca semantica nei video, la generazione di testo da video, la creazione di embedding vettoriali e la classificazione video zero-shot.
Per chi è più adatto TwelveLabs?
TwelveLabs è ideale per sviluppatori e team di ingegneria che lavorano su applicazioni di intelligenza artificiale native per video su larga scala.
Perché ho scelto TwelveLabs
TwelveLabs si guadagna il suo posto nella mia shortlist grazie alla robustezza della sua infrastruttura su scala enterprise. La piattaforma acquisisce e indicizza video a una velocità di circa 60 volte superiore al tempo reale, elaborando oltre 10.000 ore al giorno tramite una singola pipeline multimodale. Apprezzo anche il fatto che la sua infrastruttura distribuita cloud-native gestisce migliaia di richieste simultanee, un aspetto importante quando il tuo team effettua scansioni di conformità o analisi dei contenuti su archivi di grandi dimensioni. La certificazione SOC 2 Type II e le opzioni di implementazione flessibili la rendono una scelta realistica per ambienti enterprise attenti alla sicurezza.
Caratteristiche principali di TwelveLabs
- Pegasus generazione video-linguaggio: Un modello fondamentale integrato che genera testo da contenuti video, come riepiloghi di capitoli, risposte a domande aperte e raccolte di momenti salienti.
- Embedding multimodali Marengo: Produce rappresentazioni vettoriali tra video, audio, immagini e testo da un singolo modello, supportando attività di ricerca per similarità e clustering.
- Classificazione zero-shot: Classifica il contenuto dei video utilizzando tassonomie di etichette in linguaggio naturale senza dati di training etichettati o addestramento personalizzato dei modelli.
- Fine-tuning dei modelli fondamentali: Personalizza i modelli base di TwelveLabs sui tuoi dataset video specifici di settore per migliorare la precisione su tipologie di contenuti specializzati.
Integrazioni di TwelveLabs
TwelveLabs offre integrazioni con partner tra cui Adobe Premiere Pro, Pinecone, Weaviate, MongoDB, Milvus, Voxel51, MindsDB, Qdrant, Chroma e LanceDB. Databricks e Snowflake sono anche partner strategici: Databricks fornisce una pipeline di integrazione per il servizio embedding di TwelveLabs e Snowflake sviluppa connettori tramite Cortex AI. Un'API REST supporta integrazioni personalizzate e funziona con la maggior parte dei linguaggi di programmazione.
Pros and Cons
Pros:
- Ricerca multilingue in oltre 100 lingue
- Fornisce timestamp oltre alle trascrizioni
- Disponibile su cloud, cloud privato o on-premise
Cons:
- Design API-first richiede risorse di sviluppo
- Nessun benchmark pubblicato sul bias dei modelli
Comet
Ideale per lo sviluppo di machine learning guidato da esperimenti
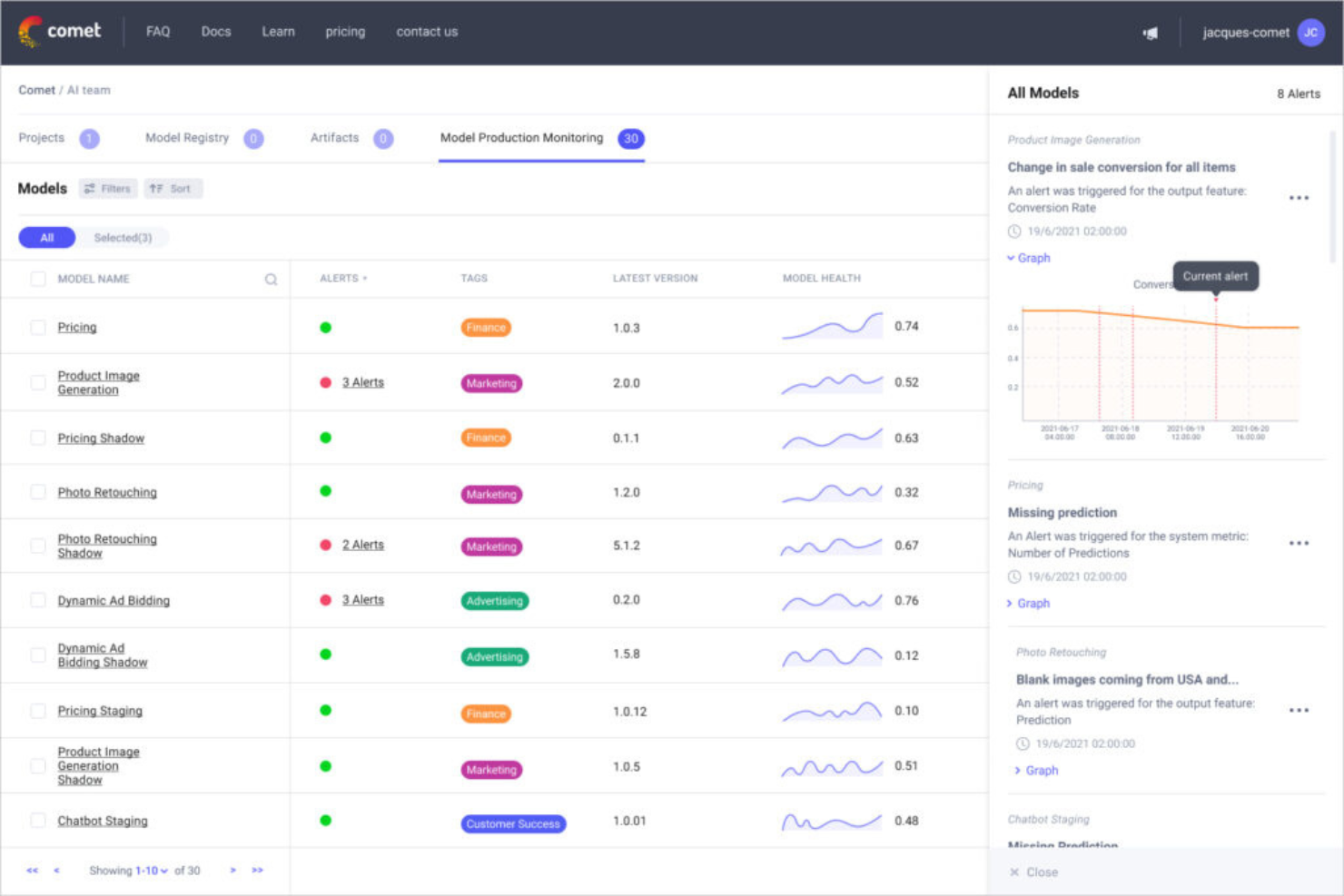
Comet è nella mia lista perché è una delle poche piattaforme di intelligenza artificiale costruite per flussi di lavoro approfonditi, guidati da esperimenti. Quando vedo team che scalano esperimenti di deep learning, tracciando, confrontando e visualizzando i risultati nel dettaglio, è proprio qui che Comet si inserisce.
Ciò che apprezzo davvero è come gestisce i metadati degli esperimenti, le versioni dei modelli e le modifiche al codice tutto in un unico luogo. È particolarmente utile quando è necessario riprodurre risultati in progetti ampi e in rapido movimento.
Migliori utilizzi di Comet
- Team di data science che gestiscono il tracciamento di un grande volume di esperimenti
- Organizzazioni focalizzate su flussi di lavoro di machine learning ripetibili e guidati da esperimenti
Quando Comet non è ideale
- Team che desiderano funzionalità integrate di deployment e serving dei modelli
- Progetti di piccole dimensioni in cui non è necessaria una gestione rigorosa degli esperimenti
Cosa distingue Comet
Comet è costruito per flussi di lavoro soggetti a molti esperimenti, dove tenere una documentazione accurata è importante quanto costruire il modello stesso. A differenza di strumenti come MLflow, che si concentrano fortemente sul deployment, Comet prevede che tu passi più tempo a progettare, tracciare e confrontare esperimenti. Questo approccio è naturale quando si analizzano dozzine o centinaia di esecuzioni, e il controllo delle versioni fa parte del lavoro quotidiano.
Il tutto si adatta perfettamente a team guidati dalla ricerca o a chiunque abbia pipeline di sperimentazioni strutturate e di ampia portata.
Compromessi con Comet
Dando la priorità al tracciamento degli esperimenti, Comet esclude dal proprio ambito il deployment e il serving dei modelli. Se vuoi operazioni sui modelli integrate, hai bisogno di una piattaforma separata.
Pros and Cons
Pros:
- Gestione degli esperimenti robusta
- Visualizzazioni delle prestazioni efficaci
- Ampia compatibilità con le librerie più diffuse
Cons:
- Il prezzo può essere elevato per piccoli team
- L'interfaccia può avere una curva di apprendimento ripida
- Capacità offline limitate
Ideale per l'etichettatura e annotazione automatizzata dei dati in ambito IA
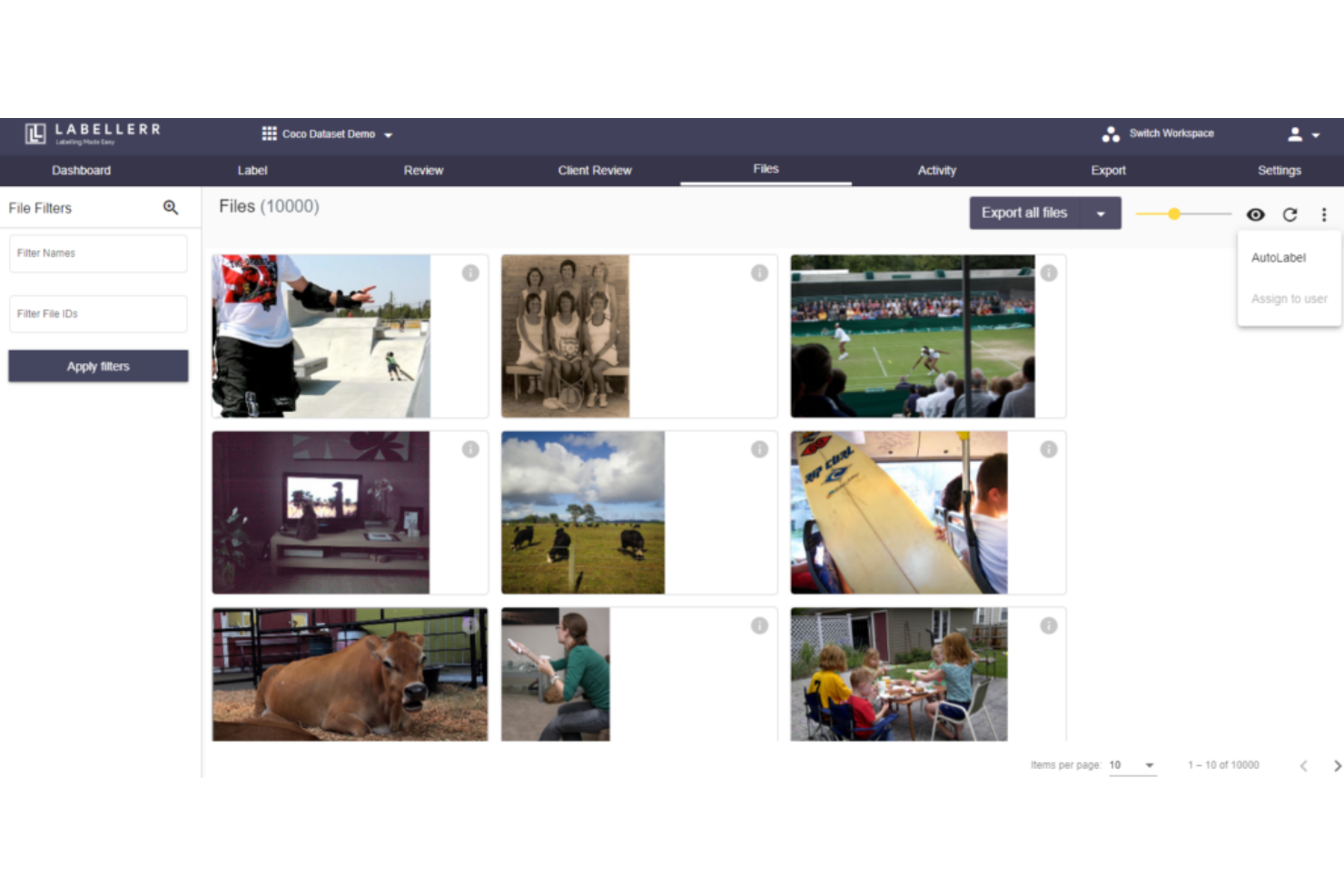
Labellerr si distingue per me perché porta l'automazione nella parte più impegnativa dei progetti di deep learning: trasformare i dati grezzi in etichette di alta qualità. Ho visto team che lavorano su progetti di computer vision o NLP passare rapidamente da attività manuali ad annotazioni assistite dall’IA grazie alle sue funzionalità di apprendimento attivo e ai flussi di lavoro orientati alla qualità. Ciò che mi piace di più è come Labellerr permette di gestire grandi volumi di dati non strutturati, con tracciabilità delle revisioni e cicli di revisione personalizzabili che mantengono i tuoi dataset pronti per la produzione.
Ideale per
- Team di IA e data science che gestiscono grandi dataset non strutturati
- Progetti che richiedono annotazione automatizzata di immagini, video o testo
Non indicato per
- Compiti di annotazione semplici dove l'automazione non è necessaria
- Team che necessitano integrazioni profonde con piattaforme MLOps legacy
Cosa rende Labellerr unico
Labellerr è progettato intorno all'automazione e al controllo di qualità per l’etichettatura dei dati non strutturati. A differenza dei sistemi di annotazione manuale o di strumenti più semplici come CVAT, Labellerr parte dal presupposto che si voglia automatizzare la maggior parte dell'etichettatura dati garantendo al contempo controlli di qualità e revisioni da parte del team dove necessario. Nella pratica, vedo team utilizzarlo quando dataset molto grandi o aggiornamenti frequenti del modello rendono i processi manuali impraticabili.
Compromessi con Labellerr
Labellerr è ottimizzato per l’annotazione automatizzata su larga scala, ma questa scelta può significare minore flessibilità o supporto se lavori principalmente su progetti più piccoli o una tantum, dove il controllo manuale è più importante.
Pros and Cons
Pros:
- Automazione efficiente dell'etichettatura dei dati
- Supporta diversi formati di dati
- Robusti strumenti di gestione dei progetti
Cons:
- Potrebbe non essere conveniente per progetti di piccola scala
- Potrebbe risultare complicato per i principianti
- Flessibilità limitata in determinati flussi di lavoro
cnvrg.io
Ideale per gestire, automatizzare e accelerare i workflow di ML
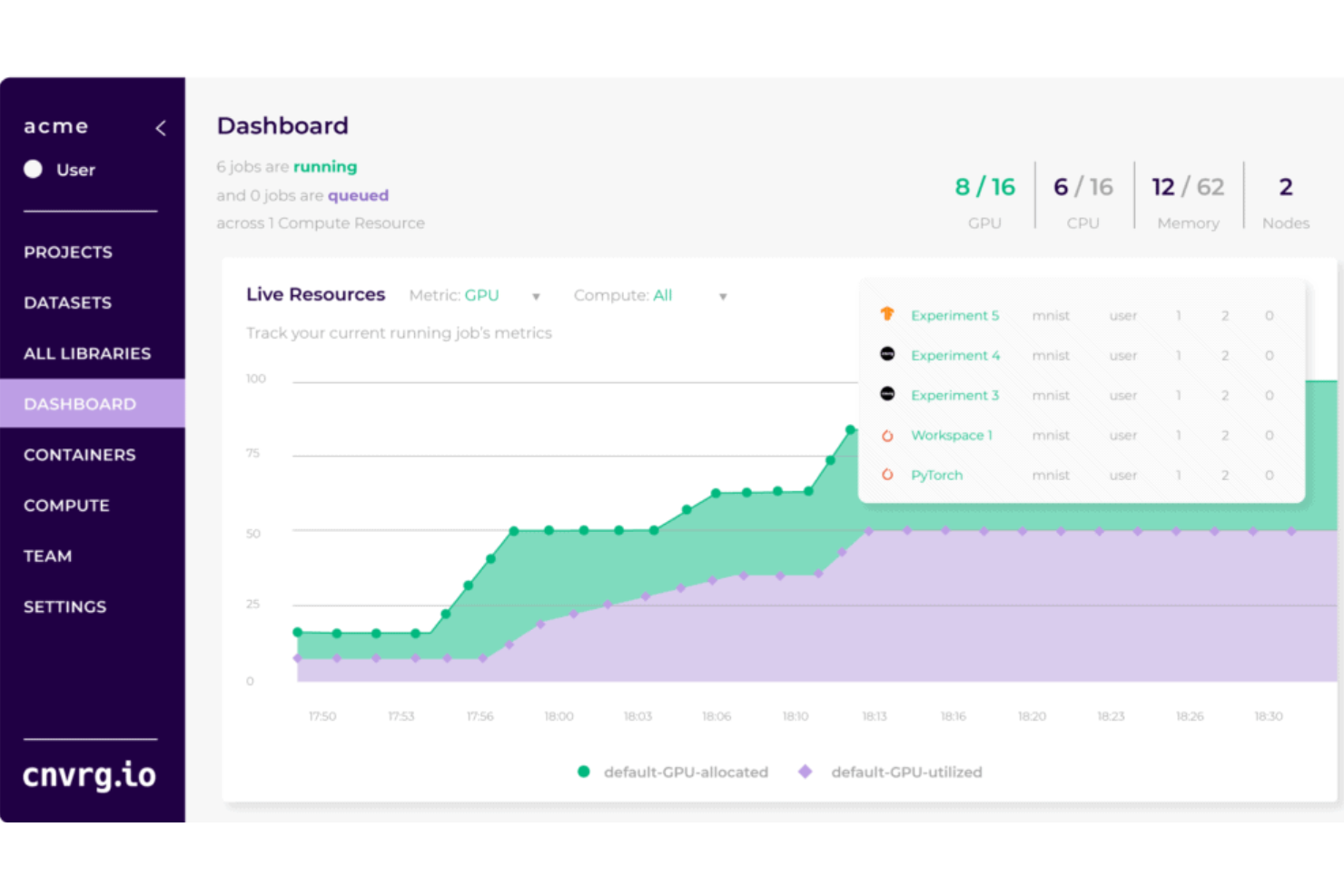
cnvrg.io si distingue perché consente ai team di gestire, eseguire e automatizzare ogni fase del ciclo di vita del machine learning da un'unica piattaforma. L'ho scelto per le organizzazioni pronte a superare l'utilizzo disordinato di notebook Jupyter e script di pipeline poco affidabili, soprattutto se hai bisogno di versionamento e tracciamento degli esperimenti su progetti realmente collaborativi.
Quello che apprezzo di più è come cnvrg.io supporti infrastrutture ibride e multi-cloud, permettendo così l'addestramento e la distribuzione di modelli di deep learning in modo scalabile e ripetibile, non solo occasionale.
Ideale per
- ML engineer che gestiscono workflow di modelli complessi e su più fasi
- Organizzazioni che distribuiscono modelli su infrastrutture ibride o multi-cloud
Non consigliato per
- Piccoli team concentrati su esperimenti ML basilari e a basso volume
- Chiunque abbia bisogno di una piattaforma di deep learning leggera o senza codice
Cosa distingue cnvrg.io
cnvrg.io è pensato per team che necessitano di una gestione end-to-end dei workflow ML su infrastrutture diverse, non solo per la semplice condivisione di notebook o la gestione degli esperimenti come Colab o SageMaker Studio.
Si aspetta che tu strutturi i progetti attorno a versionamento, collaborazione e pipeline ripetibili e scalabili, invece di eseguire semplicemente script scollegati. Nella pratica, questo funziona al meglio quando è richiesta coerenza e tracciabilità su più progetti ML, non solo per lo sviluppo di singoli modelli.
Compromessi con cnvrg.io
Puntando sull'orchestrazione di workflow affidabili e su larga scala, cnvrg.io aggiunge complessità, il che significa che piccoli esperimenti o prototipazione rapida possono risultare più lenti rispetto a tool di deep learning più snelli.
Pros and Cons
Pros:
- Gestione completa dei workflow ML
- Ottima capacità di integrazione
- Attenzione all'automazione, che libera i data scientist da compiti ripetitivi
Cons:
- La trasparenza sui prezzi può essere migliorata
- Potrebbe presentare una curva di apprendimento per i nuovi utenti
- Le opzioni di personalizzazione potrebbero essere più complete
Ideale per sfruttare strumenti potenti di AI e Deep Learning accelerati tramite GPU
NVIDIA GPU Cloud (NGC) è nella mia lista perché rende pratici enormi carichi di lavoro su modelli accelerati da GPU, anche per team che si muovono rapidamente. Ho utilizzato NGC per distribuire container ricchi di framework ottimizzati, modelli pre-addestrati e vero codice di ricerca per la visione artificiale e l'elaborazione del linguaggio naturale.
Quello che apprezzo è l'hub di modelli curato e sempre aggiornato—soprattutto quando i team hanno bisogno di risorse di livello enterprise e supporto per deep learning su scala produttiva.
NGC è ideale per
- Organizzazioni che eseguono modelli di AI e deep learning su scala produttiva
- Team che hanno bisogno di accedere a framework e container di modelli ottimizzati per NVIDIA
NGC non è l'ideale per
- Piccoli team senza accesso a infrastrutture GPU
- Progetti focalizzati su semplici compiti di machine learning non accelerati
Cosa distingue NGC
NGC è progettato per i team che lavorano con modelli di deep learning che richiedono risorse ottimizzate per GPU e container mantenuti ufficialmente. A differenza di Google Cloud Vertex AI, che cerca di astrarvi dall'infrastruttura, NGC si aspetta che sappiate quali framework e hardware vi servono e vi consente di gestire tutto con un'ottimizzazione completa da parte di NVIDIA.
In pratica, questa soluzione è adatta a chi vuole un controllo granulare sull'accelerazione e sul deployment dei modelli, non su workflow preconfezionati.
Compromessi con NGC
NGC è ottimizzato per il massimo controllo e per l'accelerazione specifica NVIDIA, ma richiede accesso dedicato a GPU, quindi i progetti più piccoli e i prototipi basati su CPU spesso finiscono per pagare risorse GPU non utilizzate o costi extra di configurazione.
Pros and Cons
Pros:
- Software potente accelerato da GPU
- Ampia selezione di modelli pre-addestrati
- Integrazione con i principali provider cloud
Cons:
- Il costo può crescere rapidamente con utilizzi intensivi
- Può essere eccessivo per progetti o aziende di piccole dimensioni
- Richiede conoscenza dell'ecosistema NVIDIA
Wolfram Mathematica merita un posto qui perché è insuperabile sia nei calcoli simbolici che numerici nel lavoro di deep learning. Si ha accesso diretto alla manipolazione delle espressioni matematiche e a calcoli numerici fluidi fianco a fianco, ciò che ritengo fondamentale per i team che ricercano architetture neurali personalizzate o algoritmi su misura.
Ciò che apprezzo di più è la facilità con cui si può passare dall'esplorazione analitica alla modellizzazione di dati reali, soprattutto per flussi di lavoro sperimentali o ibridi di intelligenza artificiale.
Ideale per
- Ricercatori che sviluppano modelli e esperimenti di reti neurali su misura
- Flussi di lavoro di deep learning che necessitano di capacità simbolico-numeriche ibride
Meno adatto per
- Team che desiderano pipeline di deep learning pronte all'uso
- Deployment di larga scala in produzione o erogazione distribuita di modelli
Cosa distingue Wolfram Mathematica
Mathematica si distingue perché unisce calcolo simbolico e deep learning in un unico ambiente di lavoro. A differenza di TensorFlow o PyTorch, che richiedono di costruire tutto numericamente, Mathematica consente di manipolare formule e svolgere esperimenti simultaneamente. Trovo che dia il meglio quando si ha bisogno di prototipazione rapida di nuovi modelli matematici o si vuole interpretare i risultati in modo simbolico.
Si vede di solito che questo approccio torna più utile nella ricerca e nello sviluppo di algoritmi di intelligenza artificiale personalizzati che non in produzione.
Compromessi con Wolfram Mathematica
Ottimizzando per flessibilità e sperimentazione, Mathematica finisce per mancare del focus su deployment e scalabilità tipico dei framework di deep learning dedicati. In pratica, si sacrifica la prontezza per la produzione in cambio di libertà creativa e analisi avanzata.
Pros and Cons
Pros:
- Capacità eccezionali di calcolo simbolico e numerico
- Mette a disposizione un'ampia gamma di strumenti e funzionalità computazionali
- Offre integrazione con altre piattaforme di analisi dati
Cons:
- L'interfaccia può risultare complessa per i nuovi utenti
- Costo superiore rispetto ad alcuni altri strumenti computazionali
- Richiede una curva di apprendimento ripida per un utilizzo ottimale
Keras si guadagna il suo posto perché è ideale per i team che hanno bisogno di passare rapidamente dall'idea a modelli di reti neurali funzionanti. Lo consiglio quando si stanno creando prototipi o si itera velocemente e si desidera una barriera minima tra il concetto e l'esecuzione. Ho riscontrato che la sua API di alto livello, l'integrazione stretta con TensorFlow e il design modulare rendono facile testare idee o portare i workflow in produzione senza troppe difficoltà.
Ciò che mi colpisce è quanto sia minima la complicazione nel passare da un prototipo a qualcosa di distribuibile—specialmente nei progetti reali di deep learning dove il tempo è importante.
Ideale per
- Prototipazione rapida di modelli e workflow di deep learning
- Ricercatori o ingegneri che devono portare rapidamente i modelli in produzione
Non ideale per
- Progetti che richiedono un controllo altamente personalizzato e di basso livello sulle reti neurali
- Team che lavorano al di fuori degli ecosistemi Python e TensorFlow principali
Cosa distingue Keras
Keras è progettato per passare rapidamente dalla teoria al codice eseguibile, così dedichi più tempo alla logica della tua rete e meno alla configurazione. Rispetto a PyTorch, che permette di entrare nei dettagli, Keras ti guida verso workflow di livello superiore con una struttura chiara. Trovo che sia perfetto quando vuoi testare e distribuire modelli in fretta, senza perdersi nella configurazione.
Compromessi con Keras
Keras ottimizza velocità e semplicità, ma perdi un po' di controllo sui dettagli dei modelli a basso livello, il che limita architetture personalizzate e un debug molto raffinato.
Pros and Cons
Pros:
- Facile da usare, consente una prototipazione rapida
- Estensibile e altamente modulare
- Set completo di strumenti e funzionalità
Cons:
- Per compiti molto specifici, le API di basso livello possono offrire più controllo
- Può essere meno efficiente per modelli con ingressi/uscite multiple
- Richiede conoscenza delle piattaforme sottostanti per ottimizzazione e debug
Appen
Ideale per accedere a set di dati umani annotati, diversificati e su larga scala
Appen è nella mia lista perché dà accesso a una delle più grandi librerie al mondo di dati annotati manualmente, qualcosa di difficile da replicare se stai scalando progetti di intelligenza artificiale o deep learning. Ho visto team avere difficoltà a costruire set di dati di addestramento diversificati, ed è qui che i set curati di Appen (che coprono lingue, demografie e argomenti diversi) fanno la differenza.
Mi piace poter accedere a set di dati di testo, immagini, audio e video specifici per settore che altre piattaforme non offrono a questa scala. Consiglierei Appen per costruire o testare modelli di deep learning che richiedono input ricchi e rappresentativi, soprattutto per applicazioni multilingue o specializzate.
Per chi è ideale Appen
- Team di AI e data science che necessitano di dati di addestramento etichettati e diversificati
- Progetti di deep learning che richiedono set di dati multilingue e su larga scala
Per chi non è adatto Appen
- Team che necessitano di strumenti per la creazione personalizzata di modelli
- Piccoli progetti con esigenze di dati limitate
Cosa distingue Appen
Appen è pensato per organizzazioni che necessitano di set di dati annotati manualmente su larga scala, senza dover gestire internamente la raccolta e l'etichettatura dei dati. Prevede che tu progetti progetti basati su dati reali, integrando input da varie demografie e lingue.
A differenza di piattaforme come Hugging Face, che offrono modelli pre-addestrati e hosting, Appen si concentra esclusivamente sulla fornitura di dati personalizzati e rappresentativi per l'addestramento e il test di modelli di deep learning.
Compromessi con Appen
Appen punta sulla profondità e sulla varietà nei set di dati etichettati, ma rinunci al controllo diretto su come questi set sono prodotti o aggiornati. Questo può rallentare la sperimentazione se hai bisogno di aggiustamenti immediati o di tipi di dati di nicchia.
Pros and Cons
Pros:
- Fornisce grandi raccolte di dati etichettati e diversificati
- Alti standard per la qualità e la sicurezza dei dati
- Integrazioni con numerose piattaforme di machine learning
Cons:
- I prezzi non sono trasparenti
- Potrebbe essere costoso per progetti o aziende di piccole dimensioni
- La complessità dei progetti può influire sui tempi di consegna
Torch è nella mia lista di soluzioni preferite per la profondità e la flessibilità che offre nello sviluppo di algoritmi personalizzati. Quando ho avuto bisogno di implementare architetture neurali complesse o di testare tecniche di deep learning all’avanguardia, ho trovato che l’ampio supporto librario di Torch permette davvero di farlo senza dover assemblare tutto artigianalmente.
Mi piace la possibilità di sfruttare sia operazioni a basso livello sia moduli pronti all’uso, così i team con esigenze avanzate non si sentono limitati dalle restrizioni del framework. Questa impostazione è perfetta per ricerca, ambito accademico o per qualsiasi team impegnato nel raggiungimento dei confini dell’IA.
Torch: Per chi è ideale
- Team di ricerca che sviluppano nuove architetture di reti neurali
- Progetti che necessitano di un’elevata personalizzazione tramite le librerie di deep learning
Torch: Non è l’ideale per
- Principianti che cercano uno strumento di deep learning semplice
- Team che vogliono template di modelli IA già pronti
Cosa distingue Torch
Torch adotta un approccio molto aperto, offrendo accesso diretto ai componenti base per la costruzione dei modelli e aspettandosi che sia tu a definire l’architettura. È simile a strumenti come TensorFlow, ma Torch è meno prescrittivo su come definire le reti o modificare gli algoritmi. Vedo spesso ricercatori e ingegneri scegliere Torch quando necessitano di un controllo molto dettagliato, invece che affidarsi alle convenzioni tipiche di framework come Keras.
Compromessi di Torch
Torch privilegia la personalizzazione e la flessibilità, quindi la configurazione e la sperimentazione risultano più lente per chi cerca modelli già pronti all’uso. Se preferisci partire da template preimpostati, probabilmente ti sentirai rallentato.
Pros and Cons
Pros:
- Librerie di machine learning molto complete
- Elevata efficienza computazionale
- Ottimo supporto della community
Cons:
- Potrebbe avere una curva di apprendimento ripida per i principianti
- Basato principalmente su Lua, meno diffuso di Python nella community data science
- Mancanza di un supporto di livello enterprise
Amplifire
Ideale per migliorare i risultati dell'apprendimento tramite l'apprendimento adattivo guidato dall'IA
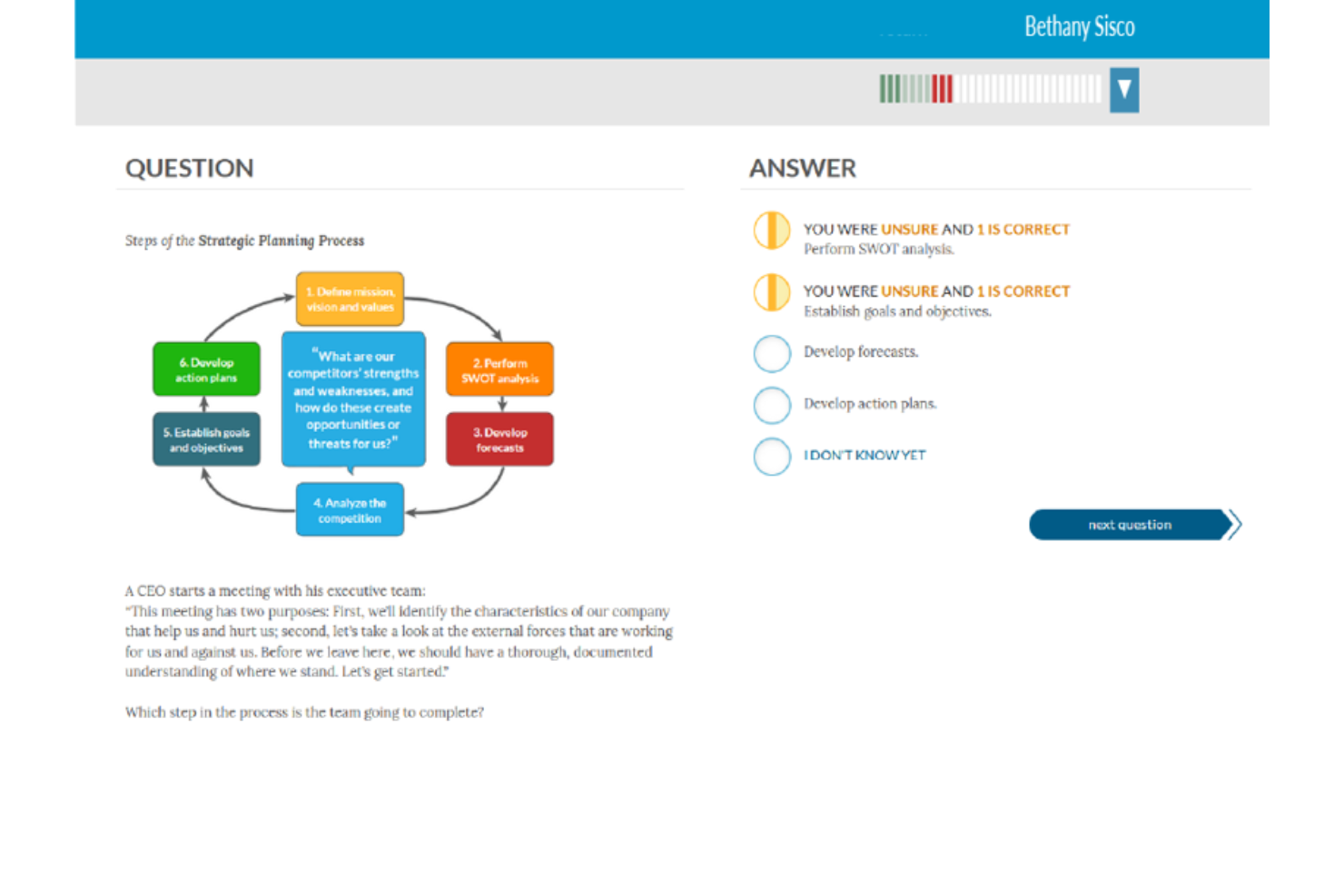
Amplifire si distingue per la combinazione di apprendimento adattivo guidato dall'IA e analisi approfondite dei contenuti per individuare le lacune di conoscenza di ciascun discente. Lo consiglio quando le organizzazioni vogliono migliorare gli esiti dell'apprendimento su scala di sistema, specialmente in settori ad alta regolamentazione come quello sanitario o finanziario.
Ciò che rende Amplifire unico sono le sue valutazioni diagnostiche e il feedback in tempo reale, che personalizzano realmente il percorso di apprendimento in base ai punti di forza e debolezza dimostrati. Apprezzo il fatto che i team possano identificare rapidamente le aree di rischio e monitorare le conoscenze dimostrate nel tempo, invece di limitarsi solo ai tassi di completamento.
Amplifire è ideale per
- Grandi organizzazioni che necessitano di formazione adattiva su larga scala
- Settori sanitari e compliance che monitorano il rischio di conoscenze
Amplifire non è indicato per
- Team di ricerca che hanno bisogno di creare modelli di deep learning personalizzati
- Piccoli team che cercano strumenti AI open-source o altamente personalizzabili
Cosa distingue Amplifire
Amplifire affronta la formazione come un processo guidato dai dati, adattando automaticamente i contenuti in base a ciò che ciascun discente dimostra di sapere o non sapere. A differenza di piattaforme come Coursera, che si basano su percorsi di apprendimento ampi e lineari, Amplifire utilizza strumenti diagnostici iniziali e adatta il materiale in tempo reale man mano che gli utenti lo affrontano.
Questo funziona particolarmente bene per settori regolamentati che necessitano di prove di ritenzione delle conoscenze invece di semplici tracciamenti dei completamenti.
Compromessi con Amplifire
Amplifire è ottimizzato per la consegna adattiva dei contenuti e la valutazione, ma si rinuncia alla flessibilità di creare o personalizzare i modelli di deep learning sottostanti. Se serve una piattaforma per ricerca o sviluppo AI personalizzato, questa non si adatta a tale flusso di lavoro.
Pros and Cons
Pros:
- Utilizza metodi guidati dall'IA per migliorare i risultati dell'apprendimento
- Individua e colma le lacune di conoscenza
- Si integra con diversi sistemi di gestione dell'apprendimento
Cons:
- I dettagli sui prezzi non sono trasparenti
- Potrebbe richiedere formazione per sfruttare al meglio le sue funzionalità
- Potrebbe offrire più opzioni di personalizzazione per ambienti di apprendimento unici
Altri Software di Deep Learning
Ecco alcune altre opzioni di software di deep learning che non sono entrate nella mia lista ristretta, ma che vale comunque la pena scoprire:
- Prime AI
Ideale per un’integrazione facile del machine learning nelle operazioni aziendali
- MIPAR
Ideale per l'analisi delle immagini con algoritmi di deep learning
- Cauliflower
Ideale per la creazione intuitiva di modelli AI con interfaccia visiva


{kind=link}
Come valuto il software di deep learning
Divido la mia valutazione in requisiti di base—come l'addestramento accelerato da GPU e il supporto alla distribuzione—e fattori differenzianti che distinguono gli strumenti pensati per la produzione MLOps dai framework destinati solo alla ricerca.
Funzionalità principali (requisiti fondamentali per questa lista)
Quando seleziono gli strumenti per la mia lista, ne valuto ognuno su una scala da 0 (non offre la funzionalità) a 5 (eccelle in quest'area) per ciascuna delle funzionalità principali elencate di seguito. Successivamente, calcolo il punteggio totale dello strumento come percentuale. Ogni strumento deve raggiungere un punteggio totale minimo del 65% per essere considerato per l'inclusione.
- Supporto ai framework di reti neurali: Controllo se è possibile costruire architetture come CNN per la classificazione di immagini, RNN per compiti sequenziali e transformer per NLP all'interno della piattaforma.
- Accelerazione GPU/TPU: L'addestramento di un grande modello di visione solo su CPU può richiedere settimane, quindi valuto il supporto di ogni strumento per configurazioni multi-GPU e distribuite.
- Libreria di modelli pre-addestrati: Una solida libreria di modelli pre-addestrati—come ResNet, BERT o varianti di GPT—rende il transfer learning e il fine-tuning molto più accessibili per il tuo team.
- Strumenti per l'addestramento dei modelli: Cerco l'ottimizzazione automatica degli iperparametri integrata, il tracciamento degli esperimenti e la visualizzazione dell'addestramento, così da permetterti di confrontare le esecuzioni senza dover integrare strumenti separati.
- Capacità di distribuzione del modello: Passare da un modello addestrato a un'API attiva o a un servizio containerizzato è spesso una sfida per molti team, quindi valuto i formati di esportazione, le opzioni di servizione e il supporto per l'edge.
- Supporto ai data pipeline: Gestire grandi dataset di immagini, corpora testuali o file audio richiede strumenti di preprocessamento e aumentazione che scalano—verifico come ogni piattaforma gestisce questi workflow.
Una volta individuati gli strumenti che soddisfano questi criteri, considero ciò che distingue ogni piattaforma.
Fattori differenzianti (ciò che distingue i fornitori)
Ecco come confronto e metto in risalto i diversi fornitori:
Caratteristiche salienti
L'integrazione MLOps è davvero importante qui. Quando il tuo team riaddestra i modelli settimanalmente, pipeline CI/CD integrate e rilevamento del drift ti risparmiano dal dover costruire quell'infrastruttura da zero. Valuto anche gli strumenti di spiegabilità—le mappe di salienza e le visualizzazioni dell'attenzione aiutano i team a effettuare il debug del comportamento dei modelli e a soddisfare gli stakeholder che hanno bisogno di comprendere le previsioni. L'ottimizzazione per edge e mobile è un altro fattore che considero, soprattutto per i team che distribuiscono su dispositivi IoT o app mobili, dove quantizzazione e pruning influiscono direttamente sulla latenza di inferenza.
Oltre le caratteristiche
La compatibilità tra framework è una delle prime cose che verifico. Se una piattaforma ti vincola a un solo framework mentre il tuo team lavora sia con PyTorch che con TensorFlow, si tratta di una reale limitazione. La flessibilità nella distribuzione è strettamente correlata—valuto se uno strumento supporta setup cloud, on-premise e ibridi, poiché molti team addestrano nel cloud ma servono i modelli su infrastruttura interna. Anche il costo totale di proprietà influenza le mie raccomandazioni. I costi di calcolo GPU aumentano rapidamente durante gli addestramenti su larga scala, quindi mi informo su quanto la tariffazione sia trasparente e se esistano versioni gratuite o opzioni open source.
Come Scegliere un Software di Deep Learning
È facile perdersi in liste infinite di funzionalità e strutture di prezzo complesse. Per aiutarti a restare concentrato durante il tuo personale processo di selezione del software, ecco una checklist dei fattori da tenere a mente:
| Fattore | Cosa considerare |
|---|---|
| Scalabilità | Il software può crescere con le tue esigenze? Verifica se supporta l'aumento dei volumi di dati e degli utenti senza perdere performance. |
| Integrazioni | Si collega con il tuo attuale software AI? Cerca la compatibilità con le tue fonti dati e le applicazioni aziendali per evitare sistemi isolati. |
| Personalizzazione | Puoi adattare il software ai tuoi flussi di lavoro? Valuta se offre opzioni di personalizzazione per dashboard, report e processi. |
| Facilità d'uso | È facile da usare per il tuo team? Considera la curva di apprendimento e se richiede una formazione approfondita per iniziare. |
| Implementazione e onboarding | Quanto tempo serve per essere operativi? L'implementazione all'interno di software di realtà virtuale, ad esempio, può richiedere più tempo rispetto ai canali tradizionali. Valuta il processo di configurazione, la disponibilità di risorse per l'onboarding e il supporto nella fase iniziale. |
| Costo | Rientra nel tuo budget? Confronta i piani tariffari, i costi nascosti e le spese a lungo termine. Verifica se sono disponibili prove gratuite per valutare il valore prima dell'acquisto. |
| Tutele sulla sicurezza | Come protegge i tuoi dati? Assicurati che sia conforme agli standard di settore e offra funzionalità come crittografia e controlli degli accessi. |
| Disponibilità del supporto | Avrai assistenza quando necessario? Cerca opzioni di supporto 24/7 e verifica la qualità delle risorse come documentazione e forum della community. |
Che cos'è un Software di Deep Learning?
Il software di deep learning è un insieme di strumenti pensati per creare, addestrare e distribuire reti neurali artificiali per soluzioni come il riconoscimento di immagini e software di intelligenza conversazionale. Data scientist, ingegneri di machine learning e ricercatori utilizzano generalmente questi strumenti per migliorare la modellazione predittiva e automatizzare analisi complesse dei dati. Le funzionalità di pre-elaborazione dei dati, addestramento dei modelli e integrazione aiutano a gestire dataset e migliorare la precisione dei modelli. In generale, questi strumenti offrono un valore significativo semplificando attività complesse basate sui dati e migliorando i processi decisionali.
Funzionalità
Nella scelta di un software di deep learning, presta attenzione alle seguenti caratteristiche chiave:
- Addestramento del modello: Facilita lo sviluppo di reti neurali fornendo strumenti per la definizione dei parametri e l'ottimizzazione dei modelli.
- Capacità di integrazione: Consente il collegamento diretto con fonti dati e applicazioni aziendali, garantendo un flusso di dati efficiente. Questo è ancora più cruciale per le aziende che utilizzano software di riconoscimento immagini per assicurare precisione in tempo reale.
- Opzioni di personalizzazione: Offre flessibilità per adattare dashboard, report e processi alle esigenze e ai flussi di lavoro specifici.
- Interfaccia intuitiva: Garantisce facilità d'uso, riducendo la curva di apprendimento e rendendo il software accessibile a diversi membri del team.
- Tutele sulla sicurezza: Protegge i dati tramite crittografia e controlli di accesso, assicurando la conformità agli standard del settore.
- Ottimizzazione automatica degli iperparametri: Migliora le prestazioni del modello regolando automaticamente i parametri per risultati ottimali.
- Pre-elaborazione dei dati: Semplifica la pulizia e l'organizzazione dei dati, garantendo input di qualità per l'addestramento dei modelli di strumenti come software NLP.
- Analisi in tempo reale: Fornisce insight immediati dai dati, supportando decisioni rapide e tempestive.
- Accesso mobile: Permette agli utenti di interagire con il software anche in mobilità, aumentando la flessibilità e la disponibilità.
- Risorse formative: Comprende tutorial, webinar e documentazione per supportare gli utenti nell'apprendimento e nell'utilizzo efficace del software.
Vantaggi
Implementare un software di deep learning offre numerosi vantaggi per il tuo team e la tua azienda. Ecco alcuni benefici a cui puoi aspirare:
- Accuratezza migliorata: Migliora la modellazione predittiva grazie a un'analisi dati precisa e a funzionalità avanzate di addestramento dei modelli.
- Efficienza nella gestione dei dati: Automatizza le attività di pre-elaborazione dei dati, risparmiando tempo e riducendo errori manuali.
- Soluzioni scalabili: Sostiene la crescita con funzionalità che supportano l’aumento dei volumi di dati e degli utenti.
- Decisioni più informate: Offre analisi in tempo reale per insight tempestivi e strategie aziendali reattive.
- Personalizzazione secondo le esigenze: Si adatta ai tuoi flussi di lavoro grazie a dashboard e processi personalizzabili.
- Maggiore sicurezza dei dati: Protegge le informazioni sensibili con misure come crittografia e controlli di accesso.
- Accessibilità e flessibilità: Fornisce accesso da dispositivi mobili, consentendo agli utenti di lavorare ovunque e restare connessi.
Costi e Prezzi
La scelta di un software di deep learning richiede la comprensione dei vari modelli e piani tariffari disponibili. I costi variano in base alle funzionalità, al numero di membri del team, alle opzioni aggiuntive e altro ancora. La tabella seguente riassume i piani più comuni, i prezzi medi e le caratteristiche tipiche incluse nelle soluzioni di deep learning:
Tabella di confronto dei piani per software di deep learning
| Tipo di Piano | Prezzo Medio | Caratteristiche Comuni |
|---|---|---|
| Piano Gratuito | $0 | Addestramento di base dei modelli, spazio dati limitato e supporto dalla community. |
| Piano Personale | $10-$30/utente/ mese | Pre-elaborazione dei dati, analisi standard e supporto via email. |
| Piano Business | $50-$100/utente/mese | Analisi avanzata, capacità di integrazione e supporto prioritario. |
| Piano Enterprise | $150-$300/utente/mese | Soluzioni personalizzabili, gestione account dedicata e sicurezza avanzata. |
Domande frequenti sul software di deep learning
u003cspan style=u0022font-weight: 400u0022u003eEcco alcune risposte alle domande più frequenti sul software di deep learning:u003c/spanu003e
Quali sono i requisiti hardware per eseguire un software di deep learning?
Il software di deep learning spesso richiede hardware potente per elaborare efficacemente grandi set di dati. Sono generalmente raccomandate GPU ad alte prestazioni, una quantità adeguata di RAM e soluzioni di archiviazione veloci. Consulta la documentazione del software per raccomandazioni hardware specifiche al fine di ottimizzare le prestazioni ed evitare colli di bottiglia.
È possibile personalizzare gli algoritmi nei software di deep learning?
Molti software di deep learning permettono di personalizzare gli algoritmi per adattarli alle proprie esigenze. Cerca strumenti che offrano architetture di rete neurale flessibili e la possibilità di modificare i parametri. Questa personalizzazione può migliorare l’accuratezza dei modelli e la loro pertinenza al proprio caso d’uso.
Il software di deep learning può integrarsi con l’infrastruttura IT esistente?
Sì, la maggior parte dei software di deep learning offre funzionalità di integrazione con infrastrutture IT già presenti. È importante verificare che lo strumento supporti API o disponga di connettori integrati per i tuoi sistemi attuali, come database e servizi cloud, così da garantire un flusso dati ottimale e la compatibilità.
E Ora?
Se stai cercando informazioni sui software di deep learning, collegati con un consulente SoftwareSelect per ricevere gratuitamente raccomandazioni.
Compili un modulo e fai una breve chiacchierata in cui verranno approfondite le tue esigenze specifiche. Poi riceverai una breve lista di software da valutare. Ti supporteranno anche durante l’intero processo d’acquisto, incluse le negoziazioni dei prezzi.