IA de Primer Nivel: Los 10 Mejores Software de Aprendizaje Profundo de 2026

Mejor Lista de Software de Deep Learning


Aprovechando la potencia de la inteligencia artificial, el software de deep learning es tu herramienta para resolver problemas de negocio complejos. Al utilizar marcos de computación de alto rendimiento y tutoriales, incluso una startup puede crear redes neuronales convolucionales y recurrentes (RNN), lo que permite transformar las capacidades de reconocimiento de imágenes.
Una plataforma de IA así facilita la modularidad con módulos independientes y análisis predictivo, convirtiéndose en un pilar para los esfuerzos de minería de datos. Sus funciones "sin código" y el manejo de problemas de big data mediante Spark hacen que sea fácil de usar, manteniendo eficiente el uso de la CPU. Trabajar con nodos o aplicaciones de aprendizaje como Javascript nunca ha sido tan sencillo, permitiéndote navegar fácilmente por el mundo de la regresión y la analítica predictiva.
Table of Contents
Por qué confiar en nuestras reseñas de software
Llevamos probando y revisando software desde 2023. Como líderes tecnológicos, sabemos lo crítico y difícil que es tomar la decisión correcta al seleccionar software.
Invertimos en una investigación profunda para ayudar a nuestra audiencia a tomar mejores decisiones de compra de software. Hemos probado más de 2,000 herramientas para diferentes casos de uso tecnológicos y escrito más de 1,000 reseñas de software exhaustivas. Descubre cómo mantenemos la transparencia y nuestra metodología de revisión de software.
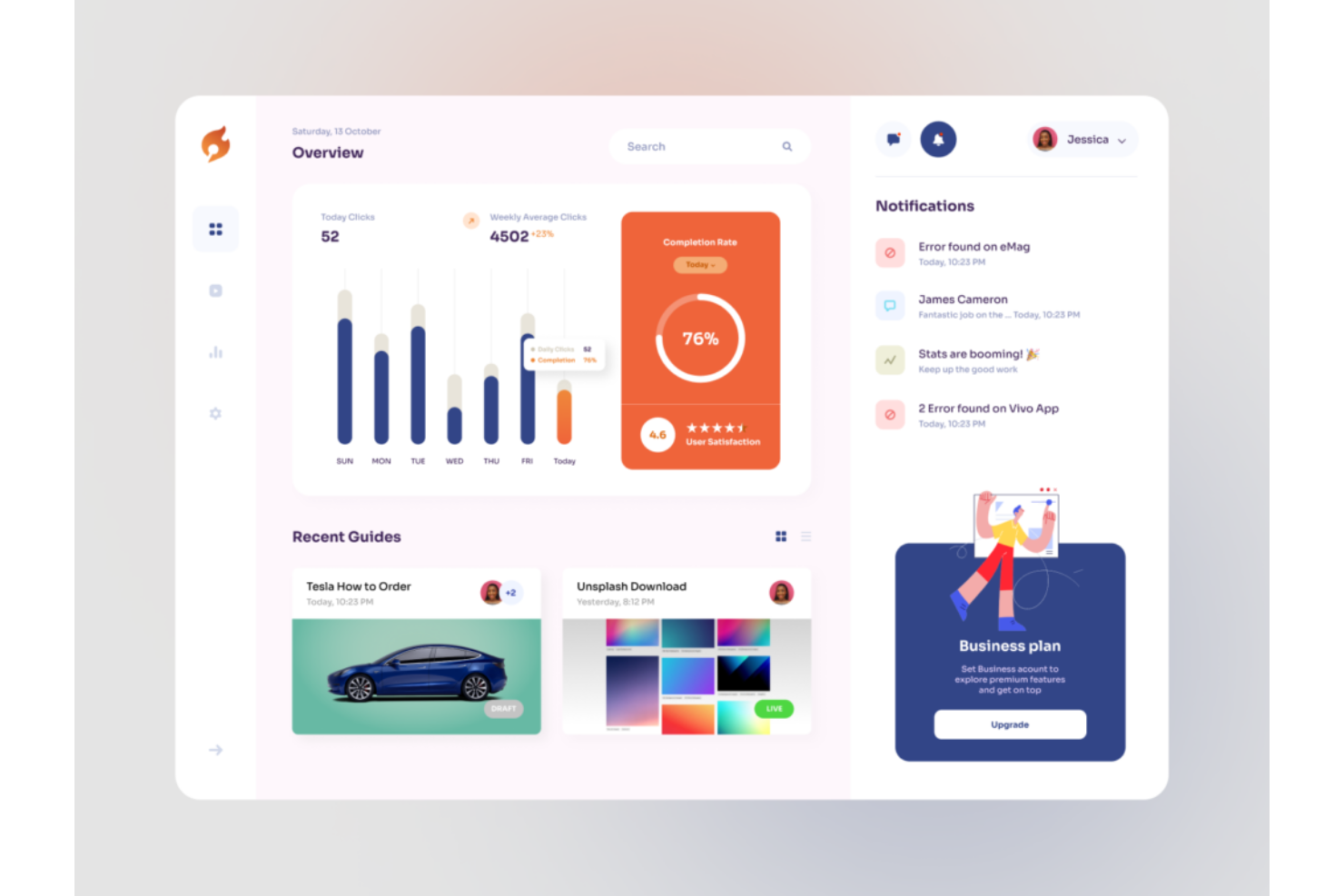
Resumen del Mejor Software de Deep Learning
Esta tabla comparativa resume los detalles de precios de mis principales selecciones de software de deep learning para ayudarte a encontrar la mejor opción según tu presupuesto y las necesidades de tu negocio.
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | Ideal para soluciones de análisis de video a escala empresarial | Plan gratuito disponible | Desde $47.85/mes | Website | |
| 2 | Ideal para desarrollo de aprendizaje automático basado en experimentos | No | $39/usuario/mes (facturado anualmente) | Website | |
| 3 | Ideal para el etiquetado y anotación de datos automatizados en IA | Not available | $49/user/month | Website | |
| 4 | Ideal para gestionar, automatizar y acelerar flujos de trabajo de ML | No | A consultar | Website | |
| 5 | Ideal para aprovechar potentes herramientas de IA y aprendizaje profundo aceleradas por GPU | Not available | $0.09 por hora de GPU | Website | |
| 6 | La mejor para el cálculo simbólico y numérico en deep learning | Not available | $25/usuario/mes (facturado anualmente) | Website | |
| 7 | Ideal para prototipado rápido y producción de redes neuronales | Not available | Gratis | Website | |
| 8 | Ideal para acceder a conjuntos de datos humanos anotados, variados y a gran escala | Not available | A solicitud | Website | |
| 9 | Ideal para el desarrollo avanzado de algoritmos con bibliotecas extensas | No | Gratis | Website | |
| 10 | Ideal para mejorar los resultados de aprendizaje con aprendizaje adaptativo impulsado por IA | Not available | A petición | Website |
-

TestDevLab
Visit Website -
Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8


Reseñas del Mejor Software de Deep Learning
A continuación están mis resúmenes detallados del mejor software de deep learning que entraron en mi lista. Mis reseñas ofrecen un análisis completo de las características clave, pros y contras, integraciones y casos de uso ideales de cada herramienta para ayudarte a encontrar la más adecuada para ti.
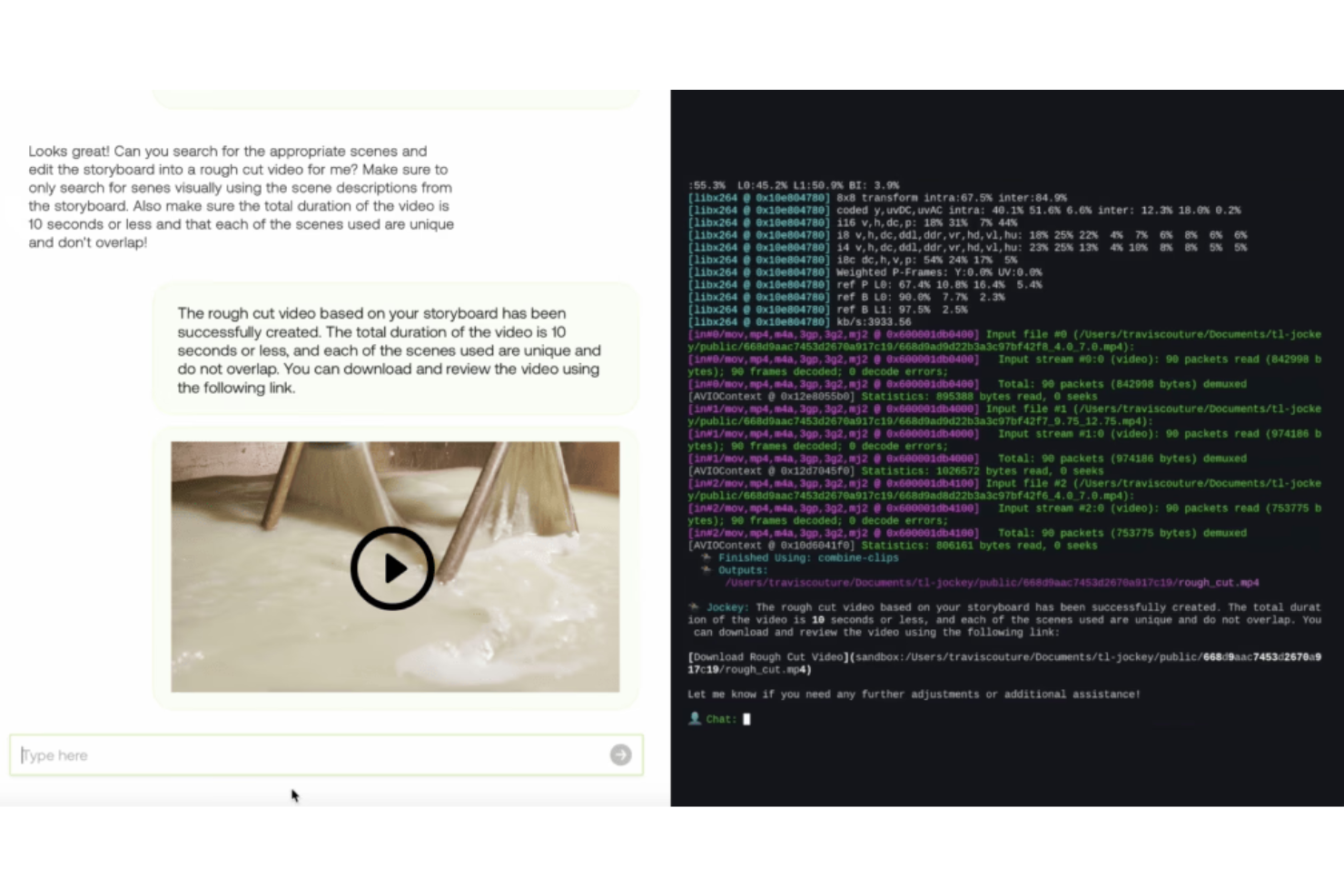
TwelveLabs es una plataforma de IA de video construida sobre modelos base de aprendizaje profundo multimodal—Marengo y Pegasus—que proporciona a los desarrolladores acceso vía API para búsqueda semántica de videos, generación de texto a partir de video, creación de incrustaciones vectoriales y clasificación de videos sin entrenamiento previo.
¿Para quién es mejor TwelveLabs?
TwelveLabs es ideal para desarrolladores y equipos de ingeniería que trabajan en aplicaciones de IA nativas de video a gran escala.
Por qué elegí TwelveLabs
TwelveLabs se gana su lugar en mi lista corta debido a la solidez de su infraestructura a nivel empresarial. La plataforma ingiere e indexa videos a aproximadamente 60 veces la velocidad en tiempo real, procesando más de 10.000 horas por día a través de un único canal multimodal. También me gusta que su infraestructura distribuida, nativa en la nube, maneja miles de solicitudes concurrentes, lo cual es importante cuando tu equipo realiza escaneos de cumplimiento o análisis de contenido en archivos masivos. La certificación SOC 2 Tipo II y las opciones flexibles de implementación la convierten en una opción realista para entornos empresariales que priorizan la seguridad.
Características clave de TwelveLabs
- Generación video-lenguaje Pegasus: Un modelo base integrado que genera texto a partir de contenido de video, como resúmenes de capítulos, respuestas abiertas de preguntas y respuestas (Q&A) y videos destacados.
- Incrustaciones multimodales Marengo: Produce representaciones vectoriales a través de modalidades de video, audio, imagen y texto desde un solo modelo, apoyando tareas de búsqueda por similitud y agrupamiento.
- Clasificación sin entrenamiento previo: Clasifica contenido de video utilizando taxonomías de etiquetas en lenguaje natural sin necesidad de datos etiquetados ni entrenamiento personalizado del modelo.
- Ajuste fino de modelos base: Personaliza los modelos base de TwelveLabs en tus propios conjuntos de datos de video de dominio específico para mejorar la precisión en tipos de contenido especializado.
Integraciones de TwelveLabs
TwelveLabs ofrece integraciones con socios como Adobe Premiere Pro, Pinecone, Weaviate, MongoDB, Milvus, Voxel51, MindsDB, Qdrant, Chroma y LanceDB. Databricks y Snowflake también son socios estratégicos, siendo Databricks quien provee una integración de canal para el servicio de incrustaciones de TwelveLabs y Snowflake desarrolla conectores a través de Cortex AI. Una API REST permite integraciones personalizadas y es compatible con la mayoría de los lenguajes de programación.
Pros and Cons
Pros:
- Búsqueda multilingüe en más de 100 idiomas
- Entrega marcas de tiempo, no solo transcripciones
- Se implementa en la nube, nube privada o en las propias instalaciones
Cons:
- El diseño orientado a API requiere recursos de desarrollo
- No hay referencias publicadas sobre los sesgos de los modelos
Comet
Ideal para desarrollo de aprendizaje automático basado en experimentos
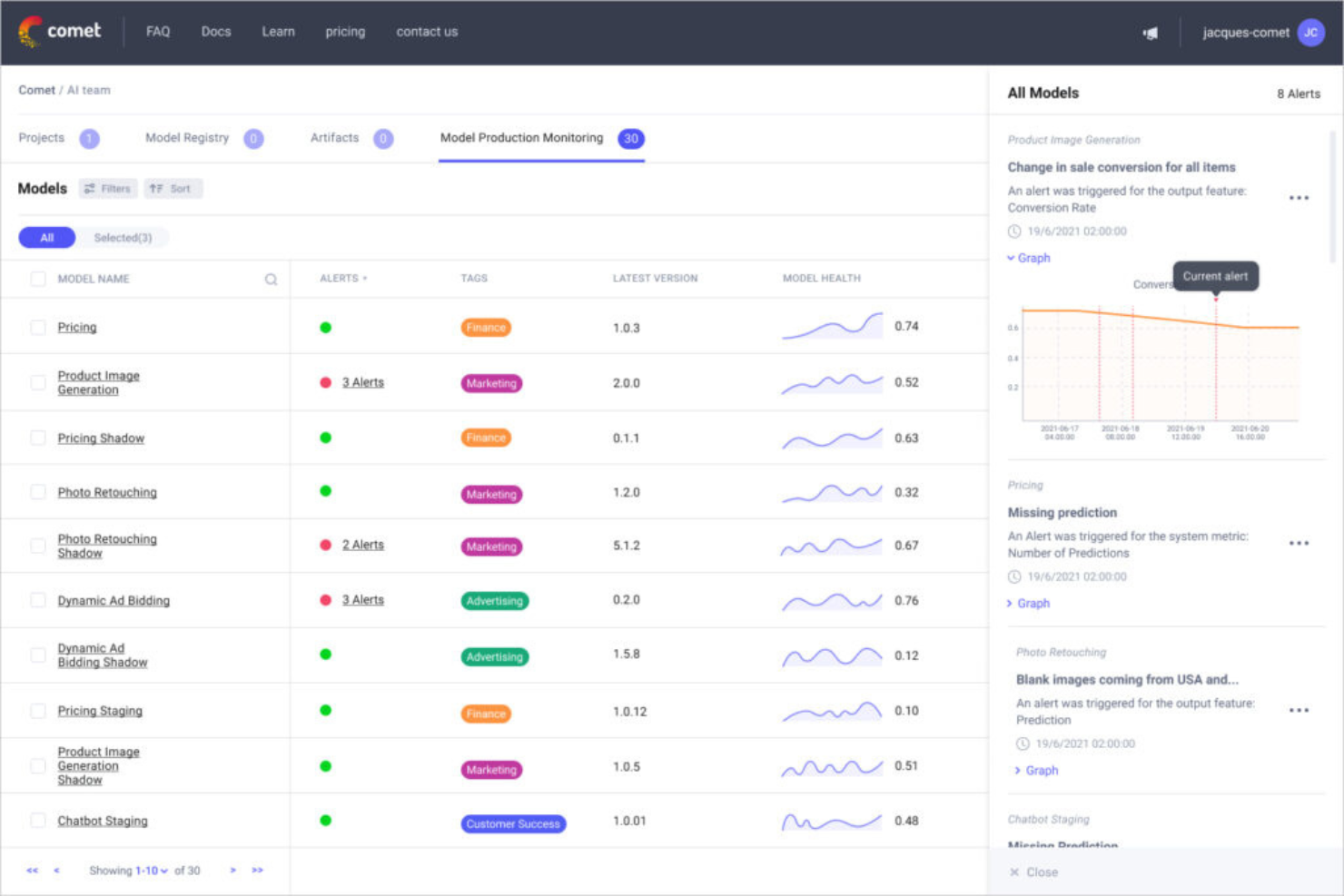
Comet está en mi lista porque es una de las pocas plataformas de IA creadas para flujos de trabajo profundos impulsados por experimentos. Cuando veo equipos que escalan experimentos de aprendizaje profundo, rastreando, comparando y visualizando resultados en detalle, ahí es donde encaja Comet.
Lo que realmente aprecio es cómo gestiona metadatos de experimentos, versiones de modelos y cambios de código, todo en un solo lugar. Es especialmente útil cuando necesitas reproducir resultados en proyectos grandes y de rápido movimiento.
Lo mejor de Comet
- Equipos de ciencia de datos que gestionan un seguimiento de experimentos de alto volumen
- Organizaciones enfocadas en flujos de trabajo de ML reproducibles y basados en experimentos
Lo menos adecuado de Comet
- Equipos que buscan funciones integradas para el despliegue y servicio de modelos
- Proyectos pequeños que no requieren una gestión rigurosa de experimentos
Lo que diferencia a Comet
Comet está diseñado para flujos de trabajo intensivos en experimentación, donde llevar registros cuidadosos es tan importante como construir el modelo. A diferencia de herramientas como MLflow, que se centran fuertemente en el despliegue, Comet espera que dediques más tiempo a diseñar, rastrear y comparar experimentos. Esto resulta natural cuando revisas decenas o cientos de ejecuciones, y el control de versiones es simplemente parte del trabajo diario.
Esto se adapta bien a equipos enfocados en la investigación o a cualquiera con grandes pipelines de experimentación.
Compensaciones de Comet
Al priorizar el seguimiento de experimentos, Comet deja fuera de su alcance el despliegue y servicio de modelos. Necesitas una plataforma aparte si buscas operaciones de modelos integradas.
Pros and Cons
Pros:
- Gestión robusta de experimentos
- Visualizaciones de rendimiento efectivas
- Amplia compatibilidad con bibliotecas populares
Cons:
- El precio puede ser elevado para equipos pequeños
- La interfaz de usuario puede tener una curva de aprendizaje pronunciada
- Capacidades offline limitadas
Ideal para el etiquetado y anotación de datos automatizados en IA
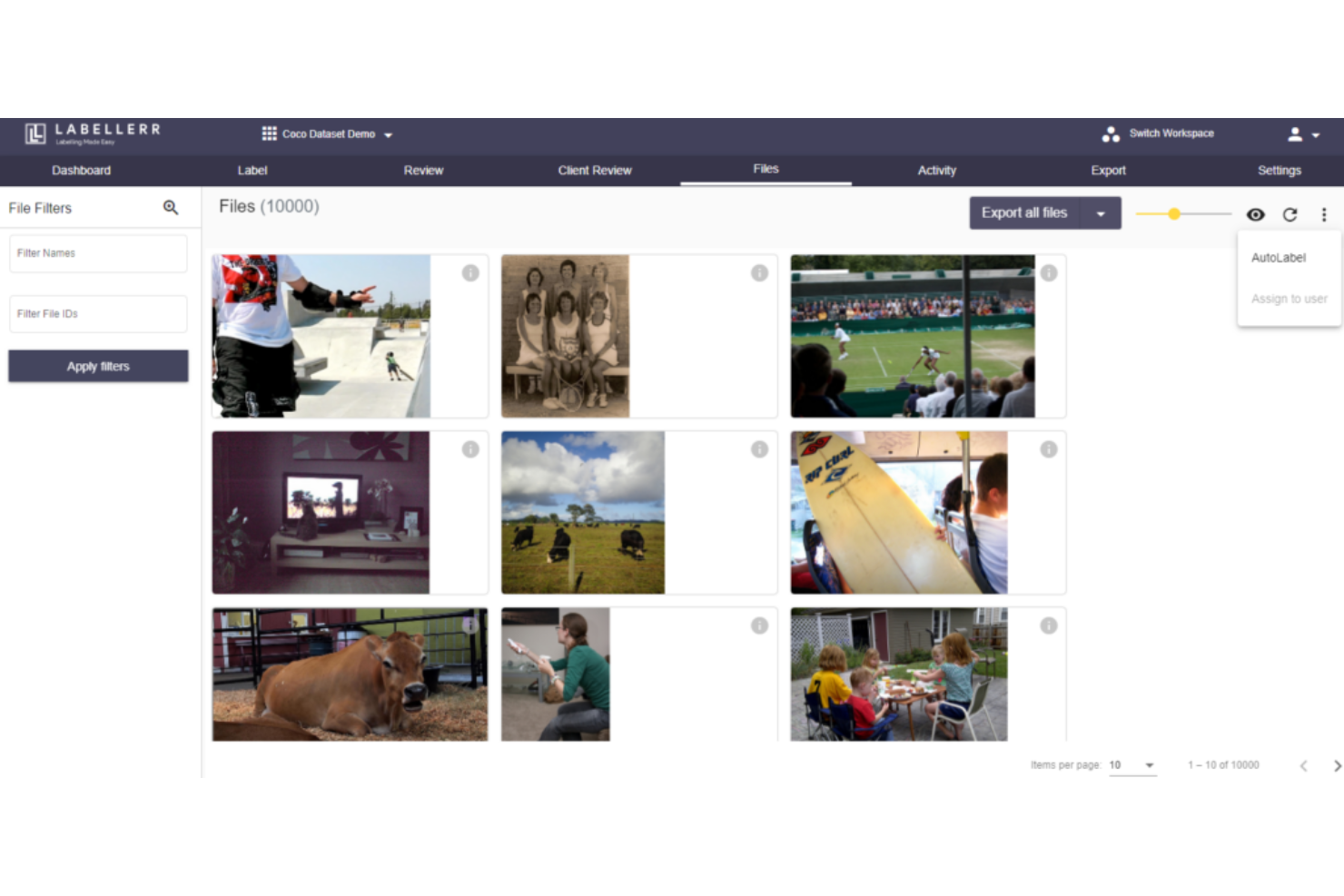
Labellerr destaca para mí porque aporta automatización a la parte más difícil de los proyectos de aprendizaje profundo: convertir datos sin procesar en etiquetas de alta calidad. He visto equipos que trabajan en visión por computadora o PLN pasar rápidamente de esfuerzos manuales a anotación asistida por IA usando sus funciones de aprendizaje activo y flujos de trabajo de calidad. Lo que más me gusta es cómo Labellerr te permite manejar grandes volúmenes de datos no estructurados, con registros de auditoría y ciclos de revisión personalizables que mantienen tus conjuntos de datos listos para producción.
Labellerr es ideal para
- Equipos de IA y ciencia de datos que manejan grandes conjuntos de datos no estructurados
- Proyectos que necesitan anotación automatizada de imágenes, videos o texto
Labellerr no es la mejor opción para
- Tareas de anotación simples donde no se requiere automatización
- Equipos que necesitan una integración profunda con plataformas MLOps heredadas
Lo que distingue a Labellerr
Labellerr está diseñado en torno a la automatización y el control de calidad para el etiquetado de datos no estructurados. A diferencia de los sistemas de anotación manual o herramientas más simples como CVAT, Labellerr parte del supuesto de que deseas automatizar la mayor parte del etiquetado de datos, pero aún así integrar controles de calidad y revisiones del equipo donde realmente importa. En la práctica, veo que los equipos lo utilizan cuando grandes volúmenes de datos o actualizaciones frecuentes de modelos hacen que los procesos manuales sean poco prácticos.
Compromisos con Labellerr
Labellerr está optimizado para la anotación automatizada de alto volumen, pero este enfoque puede significar menor flexibilidad o menor soporte si trabajas principalmente en proyectos pequeños y puntuales donde el control manual es más importante.
Pros and Cons
Pros:
- Automatización eficiente del etiquetado de datos
- Compatible con varios formatos de datos
- Potentes herramientas de gestión de proyectos
Cons:
- Puede no ser rentable para proyectos pequeños
- Puede ser complicado para principiantes
- Flexibilidad limitada en ciertos flujos de trabajo
cnvrg.io
Ideal para gestionar, automatizar y acelerar flujos de trabajo de ML
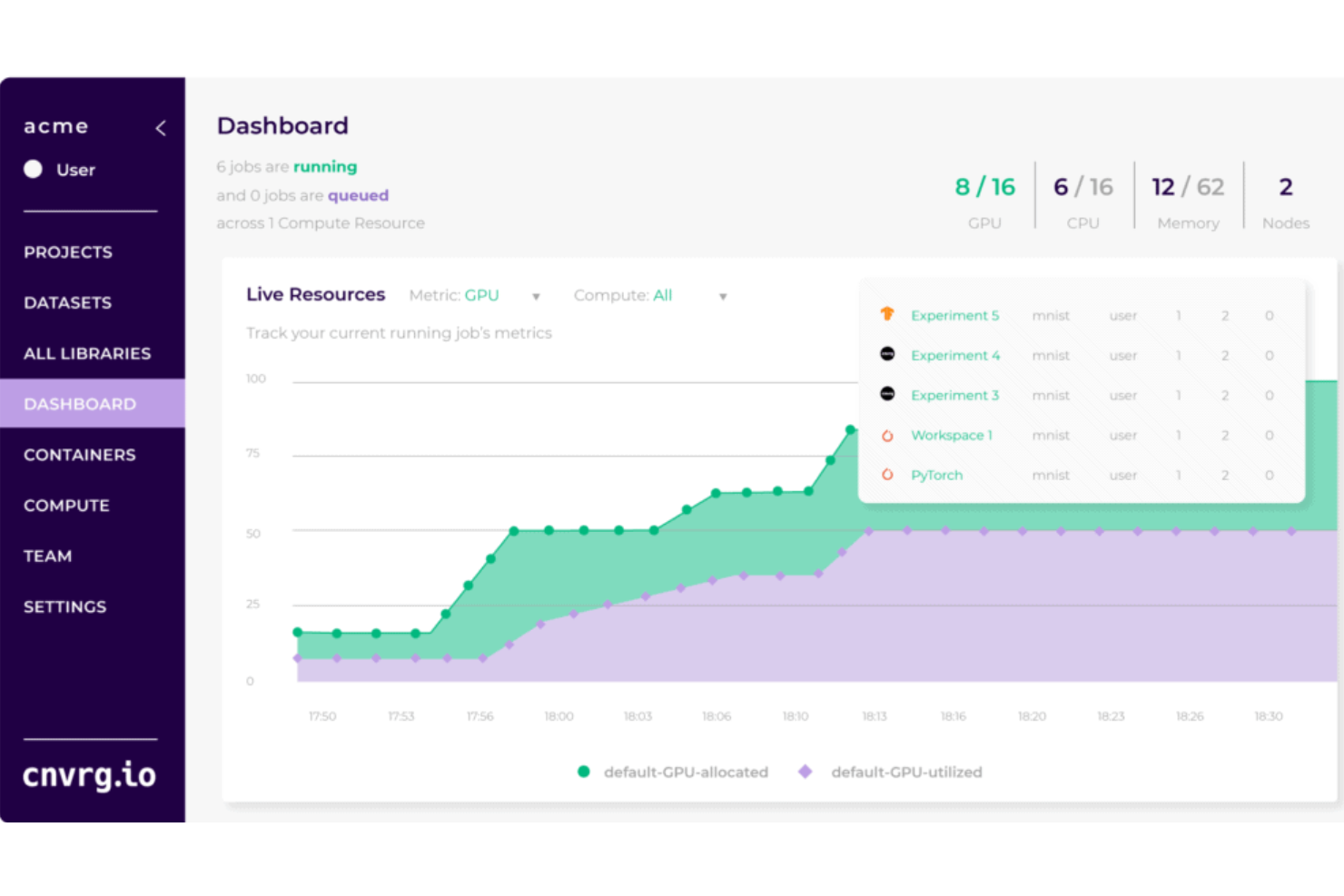
cnvrg.io destaca porque permite a los equipos ejecutar, gestionar y automatizar cada parte del ciclo de vida del aprendizaje automático desde un solo lugar. Lo elegí para organizaciones listas para ir más allá de los Jupyter notebooks dispersos y scripts de pipeline poco fiables, especialmente si necesitas control de versiones y seguimiento de experimentos en proyectos colaborativos reales.
Lo que más valoro es cómo cnvrg.io soporta infraestructuras híbridas y multinube, de modo que el entrenamiento y despliegue de modelos de aprendizaje profundo se convierte en algo escalable y repetible, y no solo en ejecuciones puntuales.
cnvrg.io es ideal para
- Ingenieros de ML que gestionan flujos de trabajo de modelos complejos y de múltiples etapas
- Organizaciones que despliegan modelos en entornos híbridos o multinube
cnvrg.io no es recomendable para
- Equipos pequeños enfocados en experimentos básicos de ML de bajo volumen
- Quienes necesiten una plataforma de aprendizaje profundo ligera o sin código
Lo que diferencia a cnvrg.io
cnvrg.io está diseñado para equipos que necesitan gestionar flujos de trabajo de ML de extremo a extremo sobre infraestructuras diversas, no solo compartir notebooks o gestionar experimentos como en Colab o SageMaker Studio.
Espera que estructures los proyectos en torno al versionado, la colaboración y pipelines repetibles y escalables, en lugar de ejecutar scripts aislados. En la práctica, esto suele funcionar mejor cuando necesitas consistencia y auditoría entre varios proyectos de ML, no solo construir modelos individuales.
Compromisos de cnvrg.io
Al centrarse en orquestar flujos de trabajo grandes y fiables, cnvrg.io añade complejidad, lo que significa que los experimentos pequeños o los prototipos rápidos pueden sentirse más lentos en comparación con herramientas de aprendizaje profundo más ligeras.
Pros and Cons
Pros:
- Gestión integral de flujos de trabajo de ML
- Capacidades sólidas de integración
- Énfasis en la automatización, liberando a los científicos de datos para tareas más complejas
Cons:
- La transparencia en la fijación de precios podría mejorar
- Puede tener una curva de aprendizaje para nuevos usuarios
- Las opciones de personalización podrían ser más robustas
Ideal para aprovechar potentes herramientas de IA y aprendizaje profundo aceleradas por GPU
NVIDIA GPU Cloud (NGC) está en mi lista de favoritos porque hace que las cargas de trabajo de modelos aceleradas por GPU sean viables, incluso para equipos que trabajan a gran velocidad. He utilizado NGC para desplegar contenedores repletos de frameworks optimizados, modelos preentrenados y código de investigación real para visión por computadora y procesamiento de lenguaje natural.
Lo que valoro es el repositorio de modelos curado y siempre actualizado—especialmente cuando los equipos necesitan recursos de nivel empresarial y soporte para aprendizaje profundo a escala de producción.
NGC es ideal para
- Organizaciones que ejecutan modelos de IA y aprendizaje profundo a escala de producción
- Equipos que necesitan acceso a frameworks y contenedores de modelos optimizados por NVIDIA
NGC no es recomendable para
- Equipos pequeños sin acceso a infraestructura GPU
- Proyectos enfocados en tareas sencillas de aprendizaje automático sin aceleración
Qué hace diferente a NGC
NGC está diseñado para equipos que trabajan con modelos de aprendizaje profundo que exigen recursos optimizados para GPU y contenedores mantenidos oficialmente. A diferencia de Google Cloud Vertex AI, que intenta abstraerte de la infraestructura, NGC espera que sepas qué frameworks y hardware necesitas, y te permite ejecutar todo con la optimización completa de NVIDIA.
En la práctica, esto es ideal cuando deseas un control granular sobre la aceleración y el despliegue de modelos, no flujos de trabajo empaquetados previamente.
Compromisos con NGC
NGC optimiza para ofrecer alto control y aceleración específica de NVIDIA, pero requiere acceso dedicado a GPU, por lo que los proyectos pequeños y prototipos basados en CPU a menudo terminan pagando por recursos de GPU no utilizados o una configuración adicional.
Pros and Cons
Pros:
- Potente software acelerado por GPU
- Amplia selección de modelos preentrenados
- Integración con los principales proveedores de la nube
Cons:
- El coste puede aumentar rápidamente con un uso intensivo
- Puede ser demasiado para proyectos o empresas pequeñas
- Requiere conocimiento del ecosistema de NVIDIA
Wolfram Mathematica merece un lugar aquí porque es insuperable en cuanto a cálculo simbólico y numérico en el trabajo de deep learning. Obtienes acceso directo a la manipulación de expresiones matemáticas y a cálculos numéricos sin interrupciones, algo que considero fundamental para equipos que investigan arquitecturas personalizadas de redes neuronales o algoritmos.
Lo que más valoro es lo fácil que resulta pasar de la exploración analítica al modelado de datos del mundo real, especialmente en flujos de trabajo de IA experimentales o híbridos.
Mejor uso de Wolfram Mathematica
- Investigadores que desarrollan modelos y experimentos personalizados de redes neuronales
- Flujos de trabajo de deep learning que requieren capacidad híbrida simbólica-numérica
Cuando Wolfram Mathematica no es la mejor opción
- Equipos que buscan flujos de trabajo de deep learning listos para usar
- Implementaciones a gran escala en producción o servicio distribuido de modelos
Lo que diferencia a Wolfram Mathematica
Mathematica destaca porque une el cálculo simbólico y el deep learning en un único espacio de trabajo. A diferencia de TensorFlow o PyTorch, que esperan que construyas todo de manera numérica, Mathematica te permite manipular fórmulas y ejecutar experimentos al mismo tiempo. Veo que esto funciona mejor cuando se necesita prototipar rápidamente modelos impulsados por matemáticas nuevas o cuando se quieren interpretar resultados de forma simbólica.
Normalmente, este enfoque ayuda más en investigación y desarrollo de algoritmos personalizados de IA que en producción.
Compromisos de Wolfram Mathematica
Al optimizar la flexibilidad y la experimentación, Mathematica acaba careciendo del enfoque en implementación y escalabilidad de los marcos de deep learning dedicados. En la práctica, se intercambia preparación para producción por libertad creativa y análisis avanzado.
Pros and Cons
Pros:
- Capacidades excepcionales de cálculo simbólico y numérico
- Brinda una amplia variedad de herramientas y funciones computacionales
- Ofrece integración con otras plataformas de análisis de datos
Cons:
- La interfaz puede resultar abrumadora para nuevos usuarios
- Costo más alto en comparación con algunas otras herramientas computacionales
- Requiere una curva de aprendizaje pronunciada para un uso óptimo
Keras se gana su lugar porque es ideal para equipos que necesitan pasar rápidamente de una idea a modelos funcionales de redes neuronales. Lo recomiendo cuando estás creando prototipos o iterando rápidamente y quieres la menor barrera posible entre el concepto y la ejecución. He comprobado que su API de alto nivel, su estrecha integración con TensorFlow y su diseño modular facilitan la prueba de ideas o la producción de flujos de trabajo sin mucho inconveniente.
Lo que más destaco es lo poco complicado que resulta pasar de un prototipo a algo que se puede desplegar—especialmente en proyectos de aprendizaje profundo del mundo real donde el tiempo es esencial.
Mejor uso de Keras
- Prototipado rápido de modelos y flujos de trabajo de aprendizaje profundo
- Investigadores o ingenieros que llevan modelos rápidamente a producción
Keras no es ideal para
- Proyectos que requieren control altamente personalizado y de bajo nivel sobre las redes neuronales
- Equipos que trabajan fuera de los ecosistemas principales de Python y TensorFlow
Qué distingue a Keras
Keras está diseñado para pasar rápidamente de la teoría al código ejecutable, así que dedicas más tiempo a la lógica de tu red y menos a la configuración. En comparación con PyTorch, que te permite profundizar en los detalles, Keras te guía hacia flujos de trabajo de alto nivel con una estructura clara. Encuentro que es la mejor opción cuando deseas probar y desplegar modelos rápidamente, sin perderte entre configuraciones.
Compromisos de Keras
Keras está optimizado para la rapidez y la simplicidad, pero se pierde algo de control sobre los detalles de bajo nivel del modelo, lo que limita las arquitecturas personalizadas y la depuración detallada.
Pros and Cons
Pros:
- Muy intuitivo, permite prototipado rápido
- Extensible y altamente modular
- Conjunto de herramientas y características muy completo
Cons:
- Para tareas muy específicas, las API de bajo nivel pueden ofrecer más control
- Puede ser menos eficiente para modelos con múltiples entradas/salidas
- Requiere comprender las plataformas subyacentes para optimización y depuración
Appen
Ideal para acceder a conjuntos de datos humanos anotados, variados y a gran escala
Appen está en mi lista porque te da acceso a una de las bibliotecas más grandes del mundo de datos anotados por humanos, lo cual es difícil de replicar si estás escalando proyectos de IA o deep learning. He visto equipos luchar al construir conjuntos de datos de entrenamiento diversos, y es aquí donde los conjuntos curados de Appen (a través de idiomas, demografías y temas) marcan la diferencia.
Lo que me gusta es poder acceder a conjuntos de datos de texto, imagen, audio y video específicos de un dominio que otras plataformas no ofrecen a esta escala. Recomendaría Appen al construir o probar modelos de deep learning que requieran entradas ricas y representativas, especialmente para aplicaciones multilingües o especializadas.
Lo mejor de Appen
- Equipos de IA y ciencia de datos que necesitan datos de entrenamiento diversos y etiquetados
- Proyectos de deep learning que requieren conjuntos de datos multilingües a gran escala
Situaciones donde Appen no es ideal
- Equipos que necesitan herramientas personalizadas de creación de modelos
- Proyectos pequeños con requisitos de datos limitados
Qué diferencia a Appen
Appen está diseñado para organizaciones que necesitan conjuntos de datos anotados por humanos a gran escala, sin manejar la logística de la recolección y etiquetado de datos internamente. Se espera que diseñes proyectos en torno a datos del mundo real, incorporando información de varias demografías e idiomas.
A diferencia de plataformas como Hugging Face, que proporcionan modelos preentrenados y hosting, Appen se centra totalmente en entregar datos personalizados y representativos para entrenar y probar modelos de deep learning.
Compensaciones con Appen
Appen optimiza la profundidad y variedad en los conjuntos de datos etiquetados, pero sacrificas el control directo sobre cómo se producen o actualizan dichos conjuntos. Esto puede ralentizar la experimentación si necesitas ajustes instantáneos o tipos de datos muy específicos.
Pros and Cons
Pros:
- Ofrece grandes conjuntos de datos humanos, diversos y anotados
- Altos estándares de calidad y seguridad de datos
- Integraciones con numerosas plataformas de aprendizaje automático
Cons:
- Los precios no son transparentes
- Puede ser costoso para proyectos o empresas más pequeñas
- La complejidad de los proyectos puede afectar el tiempo de entrega
Torch está en mi lista corta debido a la profundidad y flexibilidad que ofrece al trabajar en el desarrollo de algoritmos personalizados. Cuando he necesitado implementar arquitecturas neuronales complejas o probar técnicas de aprendizaje profundo de vanguardia, encuentro que el amplio soporte de bibliotecas de Torch realmente te permite hacerlo sin tener que hacer ajustes improvisados.
Me gusta cómo puedes acceder tanto a operaciones de bajo nivel como a módulos listos para usar, por lo que los equipos con necesidades avanzadas no quedan limitados por las restricciones del framework. Esto resulta ideal para investigaciones, entornos académicos o cualquier equipo que busque romper los límites de la IA de última generación.
Torch es ideal para
- Equipos de investigación que desarrollan arquitecturas novedosas de redes neuronales
- Proyectos que requieren una personalización extensa con bibliotecas de aprendizaje profundo
Torch no es adecuado para
- Principiantes que buscan un kit de herramientas simple de aprendizaje profundo
- Equipos que desean plantillas de modelos de IA listas para usar
Qué distingue a Torch
Torch adopta un enfoque muy abierto, dándote acceso directo a los bloques de construcción del modelo y esperando que seas tú quien dé forma a la arquitectura. Esto se parece a cómo operan herramientas como TensorFlow, pero Torch resulta menos restrictivo al definir redes o modificar algoritmos. Veo que los investigadores e ingenieros optan por Torch cuando necesitan control a nivel granular, en lugar de depender de las convenciones de un framework como Keras.
Compromisos con Torch
Torch prioriza la personalización y flexibilidad, lo que hace que la configuración y la experimentación sean más lentas para cualquiera que necesite modelos sencillos listos para usar. Si prefieres partir de plantillas ya hechas, probablemente te atasques.
Pros and Cons
Pros:
- Amplias bibliotecas de aprendizaje automático
- Alta eficiencia computacional
- Fuerte apoyo de la comunidad
Cons:
- Puede tener una curva de aprendizaje pronunciada para principiantes
- Basado principalmente en Lua, menos popular que Python en la comunidad de ciencia de datos
- Falta de soporte a nivel empresarial
Amplifire
Ideal para mejorar los resultados de aprendizaje con aprendizaje adaptativo impulsado por IA
Amplifire destaca para mí porque combina el aprendizaje adaptativo impulsado por IA con análisis profundos de contenido para identificar las brechas de conocimiento de cada alumno. Lo recomiendo cuando las organizaciones desean mejorar los resultados de aprendizaje a gran escala en todo el sistema, especialmente en sectores con fuertes requerimientos de cumplimiento normativo como la salud o las finanzas.
Lo que diferencia a Amplifire son sus evaluaciones diagnósticas y retroalimentación en tiempo real, que realmente personalizan el camino de aprendizaje en función de las fortalezas y debilidades demostradas. Me gusta que los equipos puedan identificar rápidamente áreas de riesgo y hacer seguimiento del conocimiento demostrado a lo largo del tiempo, en lugar de limitarse a las tasas de finalización.
Lo Mejor de Amplifire
- Grandes organizaciones que necesitan capacitación adaptativa a escala
- Sectores de salud y cumplimiento normativo que requieren seguimiento del riesgo de conocimiento
No Es Ideal Para
- Equipos de investigación que requieren construir modelos avanzados de aprendizaje profundo
- Pequeños equipos que buscan herramientas de IA de código abierto o altamente personalizables
Lo que diferencia a Amplifire
Amplifire aborda la capacitación como un proceso basado en datos, adaptando el contenido automáticamente según lo que cada alumno demuestra saber o no saber. A diferencia de plataformas como Coursera, que dependen de rutas de aprendizaje amplias y lineales, Amplifire utiliza herramientas de diagnóstico desde el principio y adapta el material en tiempo real mientras las personas avanzan.
Esto resulta eficaz para industrias reguladas que necesitan pruebas de retención del conocimiento en lugar de simplemente rastrear finalizaciones.
Aspectos a considerar con Amplifire
Amplifire optimiza la entrega y evaluación adaptativa del contenido, pero se sacrifica la flexibilidad para crear o ajustar modelos subyacentes de aprendizaje profundo. Si necesitas una plataforma para investigación o desarrollo de IA personalizado, esta opción no se ajustará a ese flujo de trabajo.
Pros and Cons
Pros:
- Utiliza métodos basados en IA para mejorar los resultados de aprendizaje
- Identifica y aborda las brechas de conocimiento
- Se integra con varios sistemas de gestión de aprendizaje
Cons:
- Los detalles de precios no son transparentes
- Puede requerir capacitación para aprovechar al máximo sus características
- Podría ofrecer más opciones de personalización para entornos de aprendizaje únicos
Otro Software de Deep Learning
Aquí tienes algunas opciones adicionales de software de deep learning que no llegaron a mi lista principal, pero que aún vale la pena revisar:
- Prime AI
Ideal para la fácil integración de aprendizaje automático en operaciones empresariales
- MIPAR
Ideal para el análisis de imágenes con algoritmos de aprendizaje profundo
- Cauliflower
Ideal para la creación intuitiva de modelos de IA con interfaz visual


{kind=link}
Cómo evalúo el software de deep learning
Divido mi evaluación en requisitos básicos—como soporte para entrenamiento acelerado por GPU y despliegue—y factores diferenciadores que separan las herramientas pensadas para MLOps en producción de los frameworks solo para investigación.
Funcionalidad central (condiciones mínimas para esta lista)
Cuando selecciono herramientas para mi lista, califico cada una en una escala de 0 (no ofrece la funcionalidad) a 5 (destaca en esta área) para cada funcionalidad central que se detalla a continuación. Después calculo el puntaje total de la herramienta como un porcentaje. Cada herramienta necesita lograr un puntaje total mínimo del 65% para ser considerada para su inclusión.
- Soporte de frameworks de redes neuronales: Reviso si puedes construir arquitecturas como CNN para clasificación de imágenes, RNN para tareas secuenciales y transformers para PLN dentro de la plataforma.
- Aceleración GPU/TPU: Entrenar un modelo de visión grande solo en CPU puede tomar semanas, así que evalúo cómo cada herramienta soporta configuraciones con múltiples GPU y entrenamiento distribuido.
- Librería de modelos pre-entrenados: Una buena librería de modelos pre-entrenados—como variantes de ResNet, BERT o GPT—hace que el aprendizaje por transferencia y ajuste fino sea mucho más accesible para tu equipo.
- Herramientas de entrenamiento de modelos: Busco ajuste de hiperparámetros integrado, seguimiento de experimentos y visualización de entrenamiento para que puedas comparar ejecuciones sin tener que unir herramientas separadas.
- Capacidades de despliegue de modelos: Pasar de un modelo entrenado a una API en vivo o un servicio contenedorizado es donde muchos equipos tienen dificultades, así que evalúo formatos de exportación, opciones de servicio y soporte en el borde.
- Soporte de pipelines de datos: Manejar grandes conjuntos de datos de imágenes, corpus de texto o archivos de audio requiere herramientas de preprocesamiento y aumento que escalen—verifico cómo cada plataforma gestiona estos flujos de trabajo.
Una vez que tengo una lista de herramientas que cumplen con estos criterios, considero lo que distingue a cada plataforma.
Factores diferenciadores (qué distingue a los proveedores)
Así es como comparo y contrasto a los diferentes proveedores:
Características destacadas
La integración con MLOps es muy importante aquí. Cuando tu equipo reentrena modelos semanalmente, pipelines de CI/CD y detección de desviaciones integrados te ahorran construir esa infraestructura tú mismo. También evalúo herramientas de explicabilidad—los mapas de saliencia y las visualizaciones de atención ayudan a los equipos a depurar el comportamiento del modelo y satisfacer a los interesados que necesitan entender las predicciones. La optimización para edge y móvil es otro factor que considero, especialmente para equipos que implementan en dispositivos IoT o aplicaciones móviles, donde la cuantización y el recorte afectan directamente la latencia de inferencia.
Más allá de las características
La compatibilidad con frameworks es de las primeras cosas que reviso. Si una plataforma te obliga a usar un solo framework y tu equipo trabaja tanto con PyTorch como con TensorFlow, eso es una verdadera limitante. La flexibilidad en el despliegue está muy relacionada—evalúo si una herramienta soporta implementaciones en la nube, en local y en entornos híbridos, ya que muchos equipos entrenan en la nube pero sirven los modelos en infraestructura interna. El costo total de propiedad también influye en mis recomendaciones. Los costos de cómputo con GPU se acumulan rápidamente durante los grandes entrenamientos, así que reviso cuán transparente es la tarificación y si existen opciones gratuitas o de código abierto.
Cómo Elegir un Software de Deep Learning
Es fácil perderse entre extensas listas de características y complejas estructuras de precios. Para ayudarte a mantener el foco mientras avanzas en tu proceso único de selección de software, aquí tienes una lista de factores que debes tener en cuenta:
| Factor | Qué considerar |
|---|---|
| Escalabilidad | ¿Puede el software crecer según tus necesidades? Verifica si soporta el aumento de volúmenes de datos y usuarios sin perder rendimiento. |
| Integraciones | ¿Se conecta con tu software de IA existente? Busca compatibilidad con tus fuentes de datos y aplicaciones empresariales para evitar sistemas aislados. |
| Personalización | ¿Puedes adaptar el software a tus flujos de trabajo? Evalúa si ofrece opciones de personalización para paneles, informes y procesos. |
| Facilidad de uso | ¿Es fácil de usar para tu equipo? Considera la curva de aprendizaje y si requiere formación extensa para comenzar. |
| Implementación y adopción | ¿Cuánto tiempo tomará ponerlo en marcha? La implementación en software de realidad virtual, por ejemplo, puede demorar más que los canales tradicionales. Evalúa el proceso de configuración, la disponibilidad de recursos de incorporación y soporte durante la fase inicial. |
| Costo | ¿Se ajusta a tu presupuesto? Compara planes de precios, tarifas ocultas y costos a largo plazo. Busca pruebas para evaluar el valor antes de comprometerte. |
| Salvaguardas de seguridad | ¿Cómo protege tus datos? Asegúrate de que cumpla con estándares de la industria y que ofrezca funciones como cifrado y controles de acceso. |
| Disponibilidad de soporte | ¿Tendrás ayuda cuando la necesites? Busca opciones de soporte 24/7 y la calidad de recursos como documentación y foros comunitarios. |
¿Qué es un software de deep learning?
El software de deep learning es un conjunto de herramientas diseñadas para crear, entrenar y desplegar redes neuronales artificiales en soluciones como reconocimiento de imágenes y software de inteligencia conversacional. Por lo general, los científicos de datos, ingenieros de machine learning e investigadores utilizan estas herramientas para mejorar la modelización predictiva y automatizar el análisis complejo de datos. Capacidades como el preprocesamiento de datos, el entrenamiento de modelos y la integración ayudan a gestionar conjuntos de datos y mejorar la precisión de los modelos. En resumen, estas herramientas ofrecen un valor significativo al simplificar tareas complejas orientadas a datos y mejorar los procesos de toma de decisiones.
Características
Al seleccionar software de deep learning, presta atención a las siguientes características clave:
- Entrenamiento de modelos: Facilita el desarrollo de redes neuronales proporcionando herramientas para configurar parámetros y optimizar modelos.
- Capacidades de integración: Permite la conexión fluida con fuentes de datos y aplicaciones empresariales existentes para un flujo de datos eficiente. Esto puede ser aún más crucial para empresas que utilizan software de reconocimiento de imágenes para asegurar la precisión en tiempo real.
- Opciones de personalización: Ofrece flexibilidad para adaptar paneles, informes y procesos a flujos de trabajo y necesidades específicas.
- Interfaz fácil de usar: Asegura la facilidad de uso, reduciendo la curva de aprendizaje y haciendo el software accesible para diferentes miembros del equipo.
- Salvaguardas de seguridad: Proporciona protección de datos mediante cifrado y controles de acceso, garantizando el cumplimiento de los estándares del sector.
- Optimización automática de hiperparámetros: Mejora el rendimiento del modelo ajustando automáticamente los parámetros para obtener resultados óptimos.
- Preprocesamiento de datos: Simplifica la limpieza y organización de datos, asegurando entradas de calidad para el entrenamiento de modelos de herramientas como software de PLN.
- Análisis en tiempo real: Ofrece información instantánea a partir de los datos, apoyando una rápida toma de decisiones y capacidad de respuesta.
- Acceso móvil: Permite a los usuarios interactuar con el software en cualquier lugar, aumentando la flexibilidad y accesibilidad.
- Recursos de formación: Incluye tutoriales, seminarios web y documentación para ayudar a los usuarios a aprender y utilizar el software de manera efectiva.
Beneficios
Implementar software de deep learning aporta varios beneficios para tu equipo y tu empresa. Aquí tienes algunos a los que puedes aspirar:
- Precisión mejorada: Mejora el modelado predictivo con capacidades precisas de análisis de datos y entrenamiento de modelos.
- Eficiencia en el manejo de datos: Automatiza tareas de preprocesamiento de datos, ahorrando tiempo y reduciendo errores manuales.
- Soluciones escalables: Permite el crecimiento con funciones que se adaptan al aumento de volúmenes de datos y usuarios.
- Toma de decisiones informada: Ofrece análisis en tiempo real para obtener ideas rápidas y estrategias de negocio ágiles.
- Personalización para necesidades específicas: Se adapta a tus flujos de trabajo con paneles y procesos personalizables.
- Seguridad de datos mejorada: Protege información sensible con medidas de seguridad como cifrado y controles de acceso.
- Accesibilidad y flexibilidad: Ofrece acceso móvil, permitiendo a los usuarios trabajar desde cualquier lugar y mantenerse conectados.
Costos y Precios
Seleccionar software de deep learning requiere comprender los distintos modelos y planes de precios disponibles. Los costos varían en función de las funciones, el tamaño del equipo, los complementos y más. La siguiente tabla resume los planes más comunes, sus precios promedio y las características típicas incluidas en las soluciones de software de deep learning:
Tabla comparativa de planes para software de Deep Learning
| Tipo de Plan | Precio Promedio | Funciones Comunes |
|---|---|---|
| Plan Gratuito | $0 | Entrenamiento de modelos básicos, almacenamiento de datos limitado y soporte de la comunidad. |
| Plan Personal | $10-$30/usuario/ mes | Preprocesamiento de datos, análisis estándar y soporte por correo electrónico. |
| Plan Empresarial | $50-$100/usuario/mes | Análisis avanzados, capacidades de integración y soporte prioritario. |
| Plan Corporativo | $150-$300/usuario/mes | Soluciones personalizables, gestión de cuenta dedicada y seguridad mejorada. |
Preguntas Frecuentes sobre el Software de Deep Learning
u003cspan style=u0022font-weight: 400u0022u003eAquí encontrarás respuestas a preguntas comunes sobre el software de deep learning:u003c/spanu003e
¿Cuáles son los requisitos de hardware para ejecutar software de deep learning?
El software de deep learning suele requerir hardware potente para procesar grandes conjuntos de datos de manera eficiente. Generalmente se recomiendan GPUs de alto rendimiento, suficiente memoria RAM y soluciones de almacenamiento rápidas. Consulta la documentación del software para recomendaciones de hardware específicas y así optimizar el rendimiento y evitar cuellos de botella.
¿Es posible personalizar los algoritmos en el software de deep learning?
Muchas soluciones de software de deep learning permiten personalizar los algoritmos para ajustarse a necesidades específicas. Busca herramientas que ofrezcan arquitecturas de redes neuronales flexibles y la posibilidad de modificar parámetros. Esta personalización puede mejorar la precisión del modelo y su relevancia para tu caso de uso particular.
¿Puede el software de deep learning integrarse con la infraestructura de TI existente?
Sí, la mayoría de las soluciones de software de deep learning ofrecen capacidades de integración con la infraestructura de TI existente. Debes verificar que la herramienta soporte APIs o cuente con conectores integrados para tus sistemas actuales, como bases de datos y servicios en la nube, para garantizar un flujo de datos fluido y la compatibilidad.
¿Qué sigue?
Si estás en proceso de investigar software de deep learning, conéctate con un asesor de SoftwareSelect para recibir recomendaciones gratuitas.
Solo tienes que rellenar un formulario y mantener una breve conversación donde conocerán los detalles específicos de tus necesidades. Luego recibirás un listado reducido de software para evaluar. Incluso te acompañarán durante todo el proceso de compra, incluidas las negociaciones de precios.