Los 10 Mejores Herramientas de Seguimiento de Experimentos de ML en 2026

Mejores herramientas para el seguimiento de experimentos de ML


Las herramientas para el seguimiento de experimentos de ML ayudan a registrar, organizar y comparar experimentos de aprendizaje automático para que puedas gestionar los resultados y reproducir hallazgos con confianza. Si buscas maneras prácticas de hacer el seguimiento de experimentos, compartir avances con tu equipo o mantener organizados tus modelos y conjuntos de datos, la herramienta adecuada puede marcar una gran diferencia.
En esta lista encontrarás soluciones adaptadas a diferentes stacks técnicos y flujos de trabajo, lo que te ayudará a reducir la fricción, simplificar los reportes y centrarte en una gestión fiable de los experimentos de aprendizaje automático.
Table of Contents
- Mejor Lista de Software
- Por Qué Confiar en Nosotros
- Comparar Especificaciones
- Reseñas
- Otras Herramientas de Seguimiento de Experimentos de ML
- Reseñas Relacionadas
- Criterios de Selección
- Cómo Elegir
- ¿Qué Son las Herramientas de Seguimiento de Experimentos de ML?
- Características
- Beneficios
- Costos y Precios
- Preguntas Frecuentes
Por qué confiar en nuestras reseñas de software
Llevamos probando y revisando software desde 2023. Como líderes tecnológicos, sabemos lo crítico y difícil que es tomar la decisión correcta al seleccionar software.
Invertimos en una investigación profunda para ayudar a nuestra audiencia a tomar mejores decisiones de compra de software. Hemos probado más de 2,000 herramientas para diferentes casos de uso tecnológicos y escrito más de 1,000 reseñas de software exhaustivas. Descubre cómo mantenemos la transparencia y nuestra metodología de revisión de software.
Resumen de las mejores herramientas para el seguimiento de experimentos de ML
Este cuadro comparativo resume los detalles de precios de mis principales selecciones de herramientas para el seguimiento de experimentos de ML, para ayudarte a encontrar la mejor opción para tu presupuesto y necesidades de negocio.
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | Ideal para comparación de experimentos en tiempo real | Plan gratuito disponible | Desde $19/usuario/mes | Website | |
| 2 | Ideal para paneles de visualización personalizables | Plan gratuito disponible | Desde $60/mes | Website | |
| 3 | Ideal para versionado automático en pipelines | Prueba gratuita de 14 días disponible | Precios bajo consulta | Website | |
| 4 | Ideal para la orquestación automática de pipelines | Plan gratuito disponible | From $15/user/month | Website | |
| 5 | Lo mejor para soporte de ciclo de vida de modelos de código abierto | Demo gratis + plan gratuito para siempre disponible | Gratis para siempre (código abierto) | Website | |
| 6 | Ideal para la gestión de flujos de trabajo nativos en Kubernetes | Plan gratuito disponible | Gratis y de código abierto | Website | |
| 7 | Ideal para la integración con el ecosistema de la nube de AWS | Plan gratuito disponible | Desde $0.204/hora | Website | |
| 8 | Ideal por su arquitectura de plugins y gran extensibilidad | Plan gratuito disponible | Desde $399/mes | Website | |
| 9 | Mejor para opciones de implementación híbridas y en local | Plan gratuito + demo gratuita disponible | Desde $450/mes (facturación anual) | Website | |
| 10 | Mejor para un espacio de trabajo de análisis unificado para equipos | Prueba gratuita de 14 días disponible | Precio a consultar | Website |
-

TestDevLab
Visit Website -
Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8


Reseñas de las mejores herramientas para el seguimiento de experimentos de ML
A continuación tienes mis resúmenes detallados de las mejores herramientas para el seguimiento de experimentos de ML que seleccioné para mi lista. Mis reseñas ofrecen una visión detallada de las características, integraciones y mejores casos de uso de cada plataforma para ayudarte a encontrar la que mejor se adapte a ti.
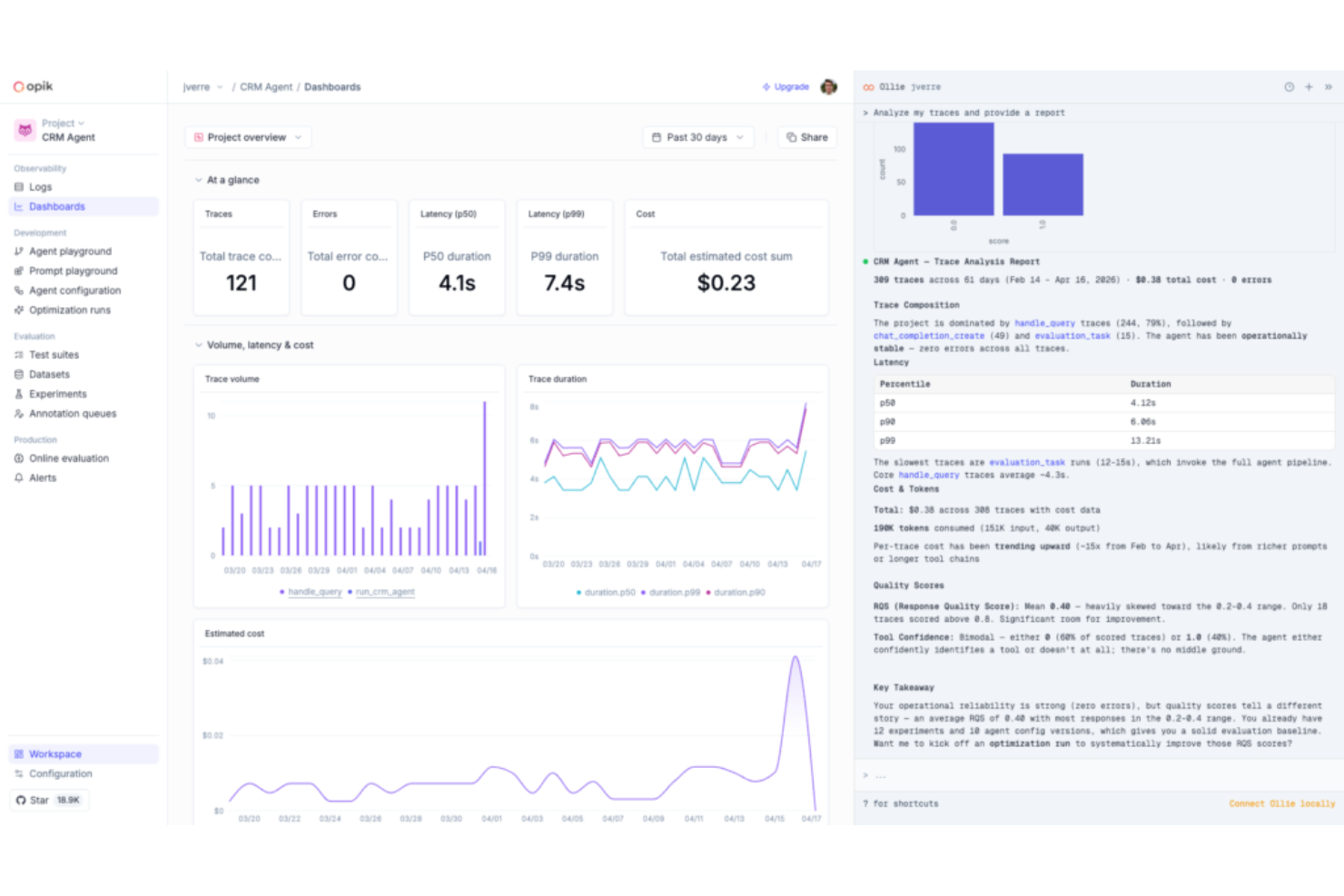
Comet es una plataforma para el seguimiento de experimentos de aprendizaje automático y evaluación de modelos que registra métricas, hiperparámetros y artefactos de los entrenamientos, y se extiende hacia la observabilidad de LLM y la evaluación de IA agentica a través de su producto Opik.
¿Para quién es Comet ideal?
Comet es una excelente opción para equipos de ML e IA de empresas en etapa de crecimiento o grandes empresas que ejecutan un gran volumen de experimentos y necesitan visibilidad en tiempo real sobre los entrenamientos.
Por qué elegí Comet
Elegí Comet como uno de los mejores porque su panel de seguimiento de experimentos en tiempo real actualiza las métricas mientras se entrenan los modelos, por lo que mi equipo puede detectar una curva de pérdida divergente y detener una ejecución problemática antes de desperdiciar recursos de cómputo. También utilizo su vista de comparación lado a lado de experimentos para filtrar entre decenas de ejecuciones por valor de hiperparámetro e identificar inmediatamente qué configuración alcanzó la mejor precisión de validación. Además de las prácticas clásicas de MLOps, Comet ahora amplía sus capacidades hacia la evaluación de LLM con Opik, lo que significa que no tengo que cambiar de herramienta al pasar del entrenamiento de modelos al monitoreo de agentes en producción.
Características clave de Comet
- Registro de modelos: Almacena, versiona y gestiona modelos entrenados en un registro centralizado con etiquetas de etapa como staging y producción.
- Registro de artefactos: Registra y versiona conjuntos de datos, imágenes, matrices de confusión y archivos de audio directamente junto a las ejecuciones de experimentos.
- Paneles personalizados: Crea visualizaciones personalizadas dentro de la interfaz de Comet usando JavaScript para ir más allá de los gráficos de métricas predeterminados.
- Seguimiento de métricas del sistema: Captura automáticamente la utilización de GPU, carga de CPU y uso de memoria en cada ejecución sin necesidad de instrumentación adicional.
Integraciones de Comet
Comet ofrece más de 30 integraciones nativas, incluyendo PyTorch, TensorFlow, Keras, Scikit-learn, XGBoost, Hugging Face Transformers, Ray, Kubeflow, Snowflake y Vertex AI. Está disponible en Zapier y ofrece una API REST junto con SDKs en Python, Java, JavaScript y R para integraciones personalizadas.
Pros and Cons
Pros:
- Registro automático de métricas con mínimo código
- Visualización en tiempo real de ejecuciones de entrenamiento
- Supervisa tanto experimentos de ML como LLMs
Cons:
- El plan Pro limita los equipos a 10 usuarios
- Opciones de personalización de la UI limitadas
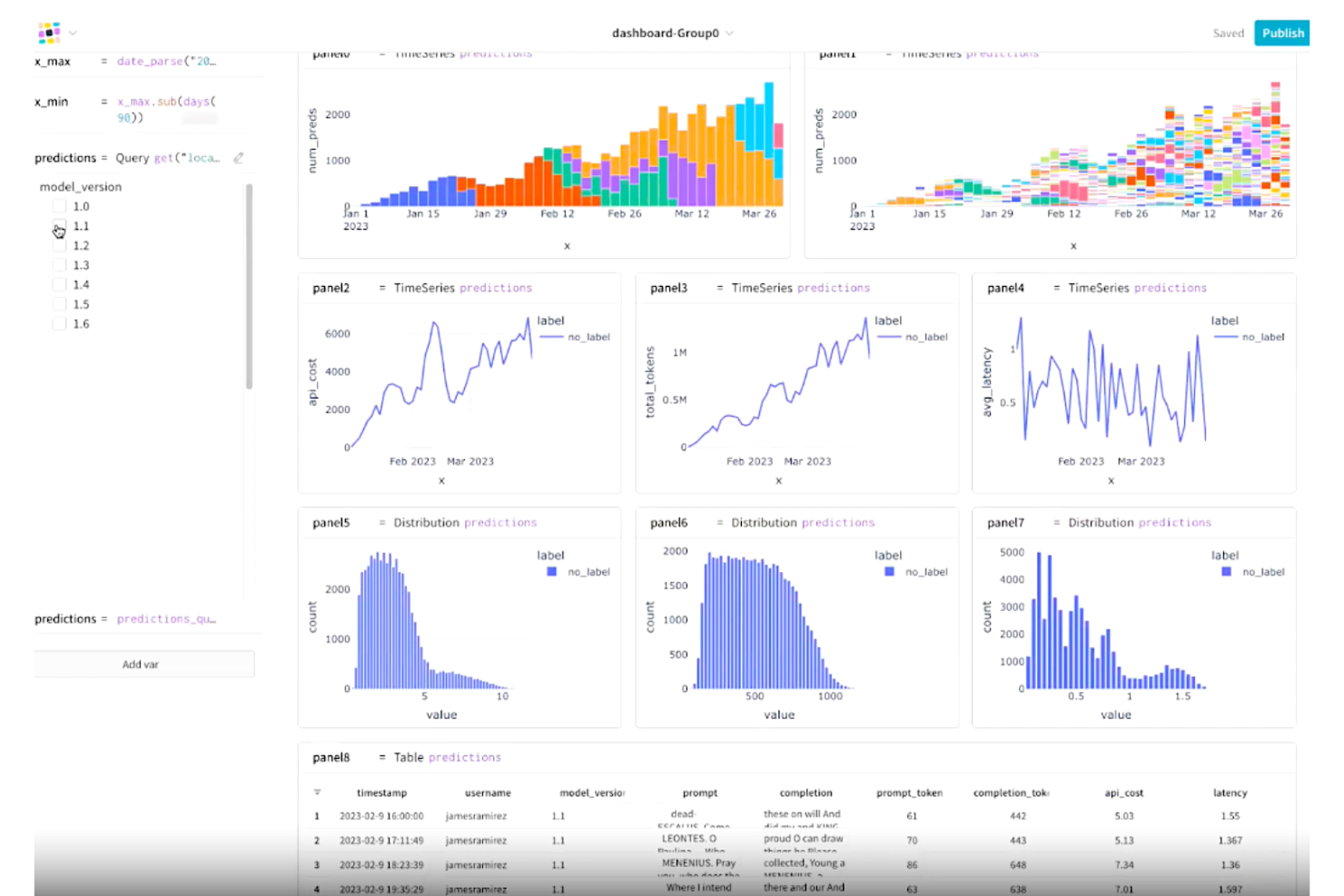
Weights & Biases es una plataforma de seguimiento de experimentos de aprendizaje automático que registra métricas, hiperparámetros y puntos de control del modelo y te permite visualizar y comparar ejecuciones a través de paneles interactivos.
¿Para quién es Weights & Biases?
Weights & Biases es ideal para científicos de datos e ingenieros de aprendizaje automático que realizan experimentos frecuentes y necesitan comparaciones detalladas de ejecuciones en equipos grandes.
Por qué elegí Weights & Biases
Weights & Biases es una de mis principales opciones porque me fascina lo lejos que llega con los paneles de visualización personalizables. Puedo extraer la utilización de GPU en tiempo real, curvas de pérdida y predicciones de muestra en un solo panel interactivo durante una ejecución de entrenamiento, lo que permite detectar cuellos de botella rápidamente. La función Sweeps me permite visualizar los resultados de las búsquedas de hiperparámetros directamente junto a las métricas de mis experimentos, así que comparo todo en una sola vista. Los informes también permiten que mi equipo anote y comparta esos paneles sin salir de la plataforma.
Características clave de Weights & Biases
- Artefactos: Versiona y realiza el seguimiento de conjuntos de datos, modelos y resultados de evaluación en diferentes ejecuciones de experimentos.
- Registro de modelos: Centraliza los modelos entrenados y vincúlalos directamente con los experimentos que los generaron.
- Agrupación de ejecuciones: Organiza ejecuciones relacionadas en grupos para comparar resultados entre configuraciones de entrenamiento.
- Alertas: Establece notificaciones automáticas para umbrales de métricas, fallos de ejecución o eventos de finalización de tareas.
Integraciones de Weights & Biases
Weights & Biases ofrece integraciones nativas con PyTorch, Keras, TensorFlow, Scikit-learn, XGBoost, Hugging Face Transformers y PyTorch Lightning, además de herramientas LLM como LangChain y LlamaIndex. También se integra con Kubeflow, Jenkins, Airflow, GitHub Actions, AWS SageMaker y Google Vertex AI. Hay disponible una API y un SDK de Python para integraciones personalizadas.
Pros and Cons
Pros:
- Transmisión en tiempo real de métricas a paneles en vivo
- Registro automático de commits de git y configuraciones
- Informes colaborativos enriquecidos con gráficos incrustados
Cons:
- La interfaz web se ralentiza con muchas ejecuciones en paralelo
- Faltan detalles en la documentación sobre funcionalidades básicas
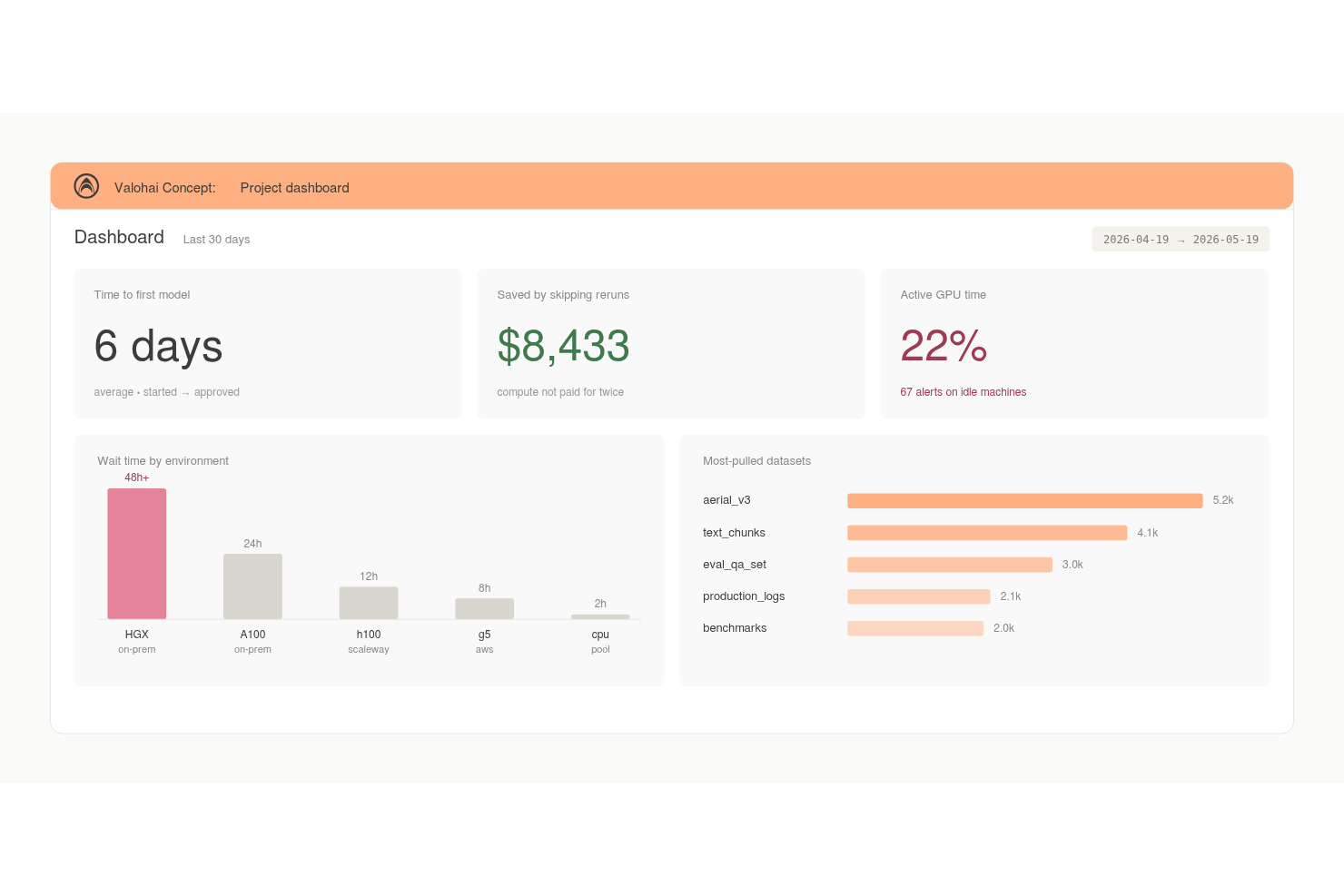
Valohai es una plataforma de ML que combina el seguimiento automático de experimentos, versionado de conjuntos de datos, linaje de modelos y orquestación de cómputo en la nube para equipos que construyen y entrenan modelos a escala.
¿Para Quién Es Mejor Valohai?
Valohai es ideal para equipos de ingeniería de ML en empresas medianas y grandes que ejecutan trabajos de entrenamiento frecuentes en múltiples entornos en la nube.
Por Qué Elegí Valohai
Elegí Valohai como uno de los mejores porque el versionado automático está realmente integrado en cada ejecución. Las métricas, metadatos, registros y hiperparámetros se versionan sin etiquetado manual, así que nunca tengo que reconstruir qué se ejecutó y cuándo. También me gusta que Valohai rastrea completamente el linaje de conjuntos de datos y modelos, lo que significa que puedo rastrear exactamente qué versión de conjunto de datos produjo cada modelo. Cada ejecución es reproducible por diseño, lo que elimina las suposiciones que complican las auditorías de experimentos.
Características Clave de Valohai
- Vista comparativa de experimentos: Muestra múltiples ejecuciones en paralelo, permitiéndote comparar hiperparámetros, métricas y resultados de experimentos en una sola tabla.
- Constructor de pipelines: Un editor visual para construir pipelines de ML de varios pasos, donde cada nodo corresponde a una etapa de ejecución versionada.
- Orquestación de cómputo en la nube: Provisión y terminación automática de instancias en la nube a través de AWS, GCP o Azure para cada ejecución de entrenamiento.
- Desencadenadores de despliegue: Promueve modelos entrenados directamente a un endpoint de servicio desde la misma plataforma utilizada para el entrenamiento.
Integraciones de Valohai
Valohai ofrece un pequeño conjunto de integraciones prediseñadas a través de su biblioteca Ecosystem, que incluye conectores para Snowflake, BigQuery y Redshift, una plantilla para Hugging Face, e integraciones con Slurm y OVHcloud. Funciona en AWS, GCP, Azure e Oracle Cloud Infrastructure, y proporciona una API REST para crear integraciones personalizadas.
Pros and Cons
Pros:
- Registra métricas de JSON impreso automáticamente
- Funciona en cualquier nube o hardware local
- Rastreo completo del linaje desde el modelo hasta el conjunto de datos
Cons:
- Integrar scripts al formato Valohai requiere esfuerzo
- La vista principal del experimento resulta visualmente poco atractiva
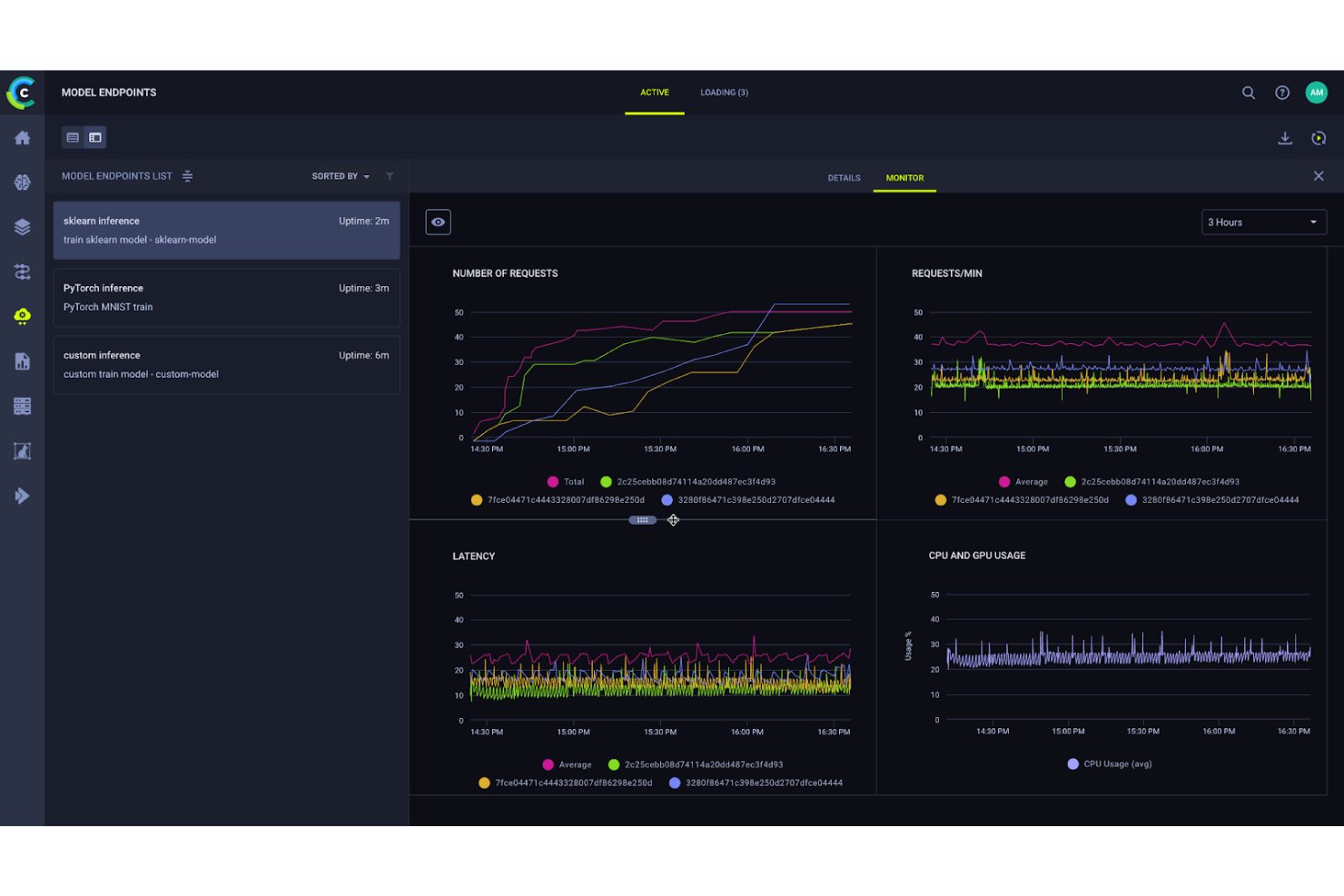
ClearML es una plataforma MLOps de código abierto que cubre el seguimiento de experimentos, versionado de conjuntos de datos, gestión de modelos y orquestación de pipelines a lo largo de todo el ciclo de vida del aprendizaje automático.
¿Para quién es ideal ClearML?
ClearML es una excelente opción para ingenieros de ML y científicos de datos en organizaciones que alojan su propia infraestructura de MLOps y necesitan control total sobre sus flujos de trabajo.
Por qué elegí ClearML
ClearML se ha ganado su lugar en mi lista porque su orquestación automática de pipelines es realmente sin intervención manual. Cuando agrego un trabajo a una cola, ClearML lo contenediza con todo su entorno y gestiona automáticamente la programación y los recursos. No necesito reescribir el código para cambiar entre sistemas locales, la nube o clústeres HPC. También me gusta que los componentes de pipeline en caché me permiten omitir pasos redundantes en las repeticiones, lo que reduce considerablemente el tiempo de ciclo en flujos de trabajo de entrenamiento iterativos.
Características clave de ClearML
- Auto-registro de experimentos: Captura automáticamente métricas, hiperparámetros, salida de consola y código fuente de cada ejecución de entrenamiento sin instrumentación adicional.
- Versionado de datos de ClearML: Versiona y gestiona conjuntos de datos con un completo seguimiento de linaje, vinculando cada versión de dataset directamente a los experimentos que la utilizaron.
- Registro de modelos: Almacena, etiqueta y recupera modelos entrenados con control de versiones y asignación de etapas a través de todo el ciclo de desarrollo.
- Optimización de hiperparámetros: Ejecuta búsquedas automáticas de HPO a través de experimentos utilizando estrategias integradas como optimización bayesiana y búsqueda aleatoria.
Integraciones de ClearML
ClearML ofrece integraciones nativas con PyTorch, TensorFlow, Keras, Scikit-learn, XGBoost, Hugging Face Transformers, FastAI, Optuna y Hydra, además de herramientas de visualización como Matplotlib y TensorBoard. Hay disponible una API y un SDK de Python para integraciones personalizadas.
Pros and Cons
Pros:
- Servidor autoalojado de código abierto elimina costos de suscripción
- Registra automáticamente código, conjuntos de datos e hiperparámetros sin instrumentación
- El diseño modular permite adoptar componentes individuales
Cons:
- Las lagunas en la documentación ralentizan la incorporación de nuevos usuarios
- La navegación entre módulos resulta poco fluida a gran escala
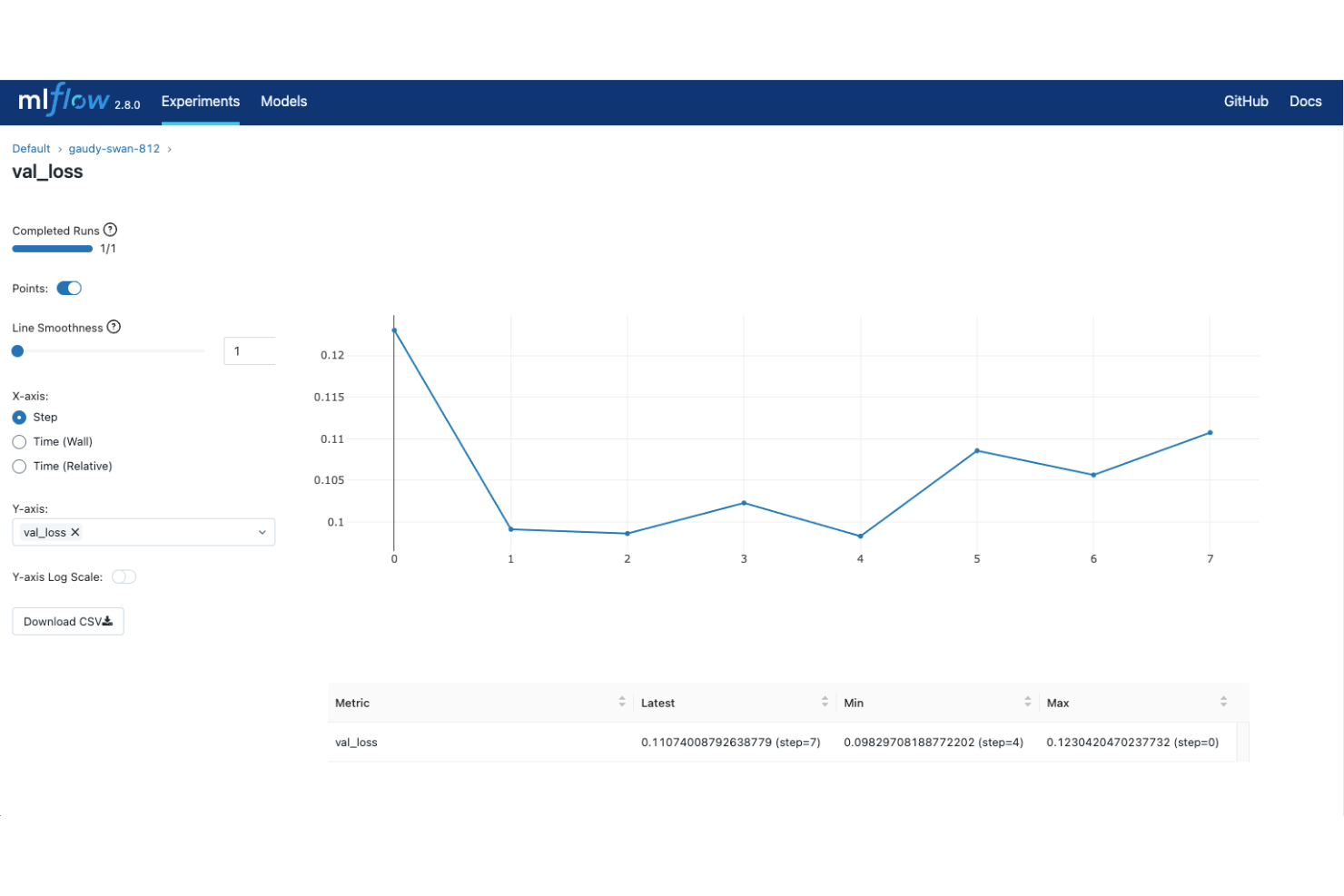
MLflow es una plataforma de seguimiento de experimentos de ML de código abierto que cubre el ciclo de vida completo del modelo, desde el registro de experimentos y la comparación de ejecuciones hasta el empaquetado, versionado y despliegue del modelo.
¿Para quién es mejor MLflow?
MLflow es una opción natural para ingenieros de ML y científicos de datos en organizaciones que alojan sus propias herramientas y desean tener un control total sobre su infraestructura de seguimiento de experimentos sin depender de proveedores.
Por qué elegí MLflow
MLflow se gana su lugar en mi lista porque cubre el ciclo de vida completo del modelo en un solo marco de trabajo de código abierto. Uso la API MLflow Tracking para registrar parámetros, métricas y artefactos de las ejecuciones; luego utilizo el Registro de Modelos para versionar y mover los modelos desde desarrollo a producción. Lo que realmente valoro es que puedo empaquetar modelos usando el formato estándar de MLflow y desplegarlos en cualquier destino sin tener que reescribir el código de servicio.
Funciones clave de MLflow
- Registro automático: Captura automáticamente parámetros, métricas y artefactos de bibliotecas compatibles como Scikit-learn, XGBoost y PyTorch sin llamadas manuales de registro.
- Interfaz de comparación de ejecuciones: Visualiza y compara métricas de múltiples entrenamientos uno al lado del otro en la interfaz web integrada de MLflow.
- MLflow Projects: Empaqueta el código de ML junto con sus dependencias y puntos de entrada para que cualquier ejecución pueda reproducirse exactamente en cualquier máquina.
- Sistema de plugins: Extiende el seguimiento, almacenamiento y despliegue de MLflow a través de plugins creados por la comunidad sin modificar el núcleo del código.
Integraciones de MLflow
MLflow ofrece más de 60 integraciones integradas, incluyendo PyTorch, TensorFlow, Scikit-learn, XGBoost, LightGBM, Hugging Face Transformers, LangChain, LlamaIndex y OpenAI. También es compatible con AWS SageMaker, Azure ML, Databricks y OpenTelemetry. Hay una API REST y un SDK de Python disponibles para integraciones personalizadas.
Pros and Cons
Pros:
- Registro independiente del marco de trabajo en múltiples bibliotecas de ML
- Versionado completo de modelos con transición de estados
- Autoalojable en cualquier infraestructura
Cons:
- Se requiere esfuerzo de DevOps para el despliegue en producción
- Visualización limitada de perfiles de hardware integrada

Kubeflow es una plataforma de aprendizaje automático (ML) de código abierto construida sobre Kubernetes que abarca la orquestación de pipelines, el seguimiento de experimentos, el entrenamiento de modelos y la optimización de hiperparámetros de forma nativa dentro de infraestructuras contenerizadas.
¿Para quién es mejor Kubeflow?
Kubeflow es ideal para equipos de ingeniería de ML que ya ejecutan cargas de trabajo en Kubernetes y desean mantener su infraestructura de seguimiento de experimentos en la misma plataforma.
Por qué elegí Kubeflow
Kubeflow se gana su lugar en mi lista porque asigna cada paso del pipeline directamente a un pod de Kubernetes, dando a las ejecuciones de los experimentos los mismos controles de recursos que cualquier otra carga de trabajo del clúster. Uso Kubeflow Pipelines para versionar y reproducir ejecuciones de entrenamiento sin salir del entorno de Kubernetes. Su componente Katib ejecuta pruebas de optimización de hiperparámetros en paralelo como trabajos nativos de Kubernetes, sin necesidad de infraestructura adicional.
Funciones Clave de Kubeflow
- Aislamiento de espacios de nombres para múltiples usuarios: Separa experimentos y pipelines por equipo o proyecto utilizando controles de acceso a nivel de namespace en Kubernetes.
- Kubeflow Notebooks: Lanza servidores de notebooks Jupyter directamente en el clúster, manteniendo la exploración de datos en el mismo entorno que las ejecuciones de entrenamiento.
- Seguimiento de linaje de artefactos: Registra las entradas, salidas y metadatos de cada paso del pipeline, vinculando conjuntos de datos y modelos a ejecuciones específicas.
- Training Operator: Gestiona trabajos de entrenamiento distribuido en frameworks como PyTorch, TensorFlow y XGBoost como recursos personalizados nativos de Kubernetes.
Integraciones de Kubeflow
Kubeflow no ofrece integraciones nativas tradicionales; en su lugar, funciona dentro del ecosistema de Kubernetes y admite frameworks de ML como TensorFlow, PyTorch, JAX, XGBoost, HuggingFace y Apache Spark a través de sus operadores de subproyectos. También puedes desplegarlo en servicios gestionados de Kubernetes de AWS, Google Cloud, Microsoft Azure y Red Hat OpenShift.
Pros and Cons
Pros:
- Ejecuta experimentos directamente en pods de Kubernetes
- Versionado de pipelines que rastrea cada ejecución de entrenamiento
- Ajuste de hiperparámetros en paralelo mediante el componente Katib
Cons:
- La configuración del clúster requiere experiencia avanzada en Kubernetes
- La interfaz de usuario parece anticuada en comparación con alternativas comerciales

Amazon SageMaker es una plataforma de aprendizaje automático (ML) totalmente gestionada en AWS que abarca el seguimiento de experimentos, entrenamiento de modelos, ajuste de hiperparámetros, registro de modelos y el despliegue a lo largo de todo el ciclo de vida de aprendizaje automático.
¿Para quién es Amazon SageMaker?
Amazon SageMaker es una excelente opción para equipos de ciencia de datos e ingeniería de ML que ya ejecutan cargas de trabajo sobre la infraestructura de AWS.
Por qué elegí Amazon SageMaker
He incluido Amazon SageMaker entre mis mejores opciones porque su seguimiento de experimentos está directamente integrado en el ecosistema de AWS de una manera que otras herramientas no pueden replicar. SageMaker Experiments registra ejecuciones, parámetros y métricas de forma nativa junto con el almacenamiento de artefactos en S3 y acceso controlado por IAM, por lo que no hay una infraestructura separada que gestionar. Mi equipo también utiliza SageMaker Pipelines para encadenar trabajos de entrenamiento, evaluaciones y registro de modelos en un único flujo de trabajo auditado sin salir de AWS.
Funciones clave de Amazon SageMaker
- Registro de modelos SageMaker: Versiona, aprueba y gestiona modelos entrenados con seguimiento de metadatos a lo largo de todo el ciclo de vida del modelo.
- Ajuste automático de modelos: Ejecuta trabajos de optimización de hiperparámetros utilizando estrategias de búsqueda bayesiana, aleatoria o en cuadrícula a escala.
- SageMaker Debugger: Supervisa los trabajos de entrenamiento en tiempo real para detectar problemas como gradientes que desaparecen o sobreajuste en el momento en que ocurren.
- SageMaker Feature Store: Almacena, comparte y recupera características de ML para cargas de trabajo de entrenamiento e inferencia desde un repositorio centralizado.
Integraciones de Amazon SageMaker
Amazon SageMaker se integra de forma nativa en todo el ecosistema de AWS, incluyendo Amazon S3, Amazon Redshift, AWS Glue, Amazon EMR, Amazon Athena, Amazon ECR, AWS Lambda, Amazon CloudWatch y MLflow. Hay disponible una API para integraciones personalizadas.
Pros and Cons
Pros:
- Registra parámetros, datos y versiones de código por ejecución
- Puntos de control automáticos durante entrenamientos largos
- Supervisión de modelos incorporada junto al registro de experimentos
Cons:
- Los recursos no utilizados pueden acumular cargos de facturación silenciosamente
- Los artefactos de modelos usan formatos específicos de AWS, lo que limita la portabilidad
ZenML es una plataforma de orquestación de flujos de trabajo de ML de código abierto que gestiona la orquestación de flujos de trabajo, el versionado de artefactos, el linaje de modelos y el seguimiento de experimentos en cualquier infraestructura en la nube o conjunto de herramientas de ML.
¿Para quién es ideal ZenML?
ZenML es especialmente adecuado para ingenieros de ML y equipos de ciencia de datos que necesitan estandarizar y escalar pipelines de ML en múltiples entornos en la nube o infraestructuras.
Por qué elegí ZenML
ZenML se gana su lugar en mi lista porque su arquitectura basada en componentes me permite cambiar cualquier parte de mi infraestructura de ML sin reescribir el código del pipeline. Puedo conectar MLflow o Weights & Biases como el sistema de seguimiento de experimentos, intercambiar el almacén de artefactos de local a S3 y cambiar el orquestador a Kubeflow, simplemente cambiando el stack activo. Además, utilizo los sabores personalizados de componentes de ZenML para crear integraciones propias de seguimiento que encajan directamente en la misma abstracción de pipelines.
Funciones clave de ZenML
- Cacheo de pasos en pipelines: Almacena automáticamente los resultados de pasos ejecutados previamente, evitando la reejecución de pasos sin cambios durante experimentos iterativos.
- Versionado de artefactos: Realiza el seguimiento de cada artefacto producido por una ejecución del pipeline, incluidos conjuntos de datos, modelos y métricas, con linaje completo al paso de origen.
- Registro de modelos: Almacena y versiona modelos entrenados junto con sus metadatos asociados, ejecuciones de pipelines e historial de despliegue en un registro centralizado.
- Panel de ZenML: Proporciona una interfaz web para explorar ejecuciones de pipelines, comparar resultados de experimentos e inspeccionar los metadatos de artefactos a través de los stacks.
Integraciones de ZenML
ZenML ofrece 66 integraciones nativas en el ecosistema de ML, incluyendo MLflow, Weights & Biases, Neptune, Comet y TensorBoard, junto a orquestadores como Kubeflow, Apache Airflow, Kubernetes y Databricks, y soporte para la infraestructura en la nube de AWS, Google Cloud y Microsoft Azure. Hay una API disponible para integraciones personalizadas.
Pros and Cons
Pros:
- Permite cambiar infraestructura sin reescribir el código del pipeline
- Stack agnóstico en la nube que evita el bloqueo de proveedor
- Versionado automático de artefactos a lo largo de las ejecuciones del pipeline
Cons:
- Depende de herramientas de terceros para la visualización de experimentos
- La configuración inicial del stack requiere un esfuerzo considerable
Polyaxon es una plataforma de seguimiento de experimentos de ML y orquestación de flujos de trabajo que abarca el seguimiento de experimentos, la optimización de hiperparámetros, el versionado de artefactos, el registro de modelos y la programación distribuida de tareas en infraestructuras en la nube y locales.
¿Para quién es mejor Polyaxon?
Polyaxon es ideal para ingenieros de ML en empresas que operan bajo estrictos requisitos de gobernanza de datos o necesitan ejecutar cargas de trabajo en infraestructuras privadas.
Por qué elegí Polyaxon
Incluí Polyaxon en mis selecciones principales porque es una de las pocas plataformas de seguimiento de experimentos de ML diseñadas desde cero para ejecutarse completamente en tu propia infraestructura. Lo ejecuto en un clúster privado de Kubernetes, y cada registro de experimento, artefacto y modelo permanece dentro de nuestra red. Su arquitectura basada en agentes me permite conectar entornos aislados en local a un plano de control central sin exponer datos sin procesar externamente, lo cual es un requisito real en industrias reguladas.
Funciones clave de Polyaxon
- Búsqueda y optimización de hiperparámetros: Ejecuta grupos de experimentos en paralelo usando estrategias de búsqueda distribuidas para encontrar configuraciones óptimas de modelos.
- Centro de componentes: Define módulos reutilizables con entradas y salidas tipadas que se pueden compartir y versionar en los flujos de trabajo de tu equipo.
- Búsqueda potente: Filtra ejecuciones por nombre, descripción, expresiones regulares, campos específicos, métricas o configuraciones para localizar experimentos rápidamente.
- Cumplimiento de SLA: Aplica políticas de vida útil, tiempo de espera y reintentos a operaciones individuales para mantener los flujos de trabajo dentro de los límites definidos.
Integraciones de Polyaxon
Polyaxon ofrece un amplio conjunto de integraciones nativas en seguimiento de ML, orquestación e infraestructura, incluyendo TensorBoard, PyTorch, TensorFlow, Keras, XGBoost, Hugging Face, Kubeflow, Slack, GitHub y Jenkins. También se conecta con Zapier y proporciona una API para integraciones personalizadas y automatización CI/CD.
Pros and Cons
Pros:
- Programación nativa en Kubernetes para tareas de entrenamiento distribuidas
- Multiusuario incorporado con controles de acceso granulares
- Soporta implementaciones en local, en la nube y entornos híbridos
Cons:
- Requiere conocimientos avanzados de Kubernetes para operar
- Comunidad más pequeña que MLflow o W&B
Databricks
Mejor para un espacio de trabajo de análisis unificado para equipos

Otras herramientas para el seguimiento de experimentos de ML
Aquí tienes algunas opciones adicionales de herramientas para el seguimiento de experimentos de ML que no llegaron a mi lista principal, pero que aún vale la pena revisar:
- Domino Data Lab
Mejor para control centralizado en investigación colaborativa
- iguazio
Ideal para el monitoreo de modelos en tiempo real y a gran escala
- Dagster
Ideal para la creación programática de flujos de datos


{kind=link}
Cómo evalúo las herramientas de seguimiento de experimentos de ML
Divido mi evaluación en dos capas: lo que toda herramienta debe hacer (como registrar automáticamente ejecuciones de PyTorch) y lo que distingue a las mejores herramientas.
Funcionalidad principal (Requisitos básicos para esta lista)
Al seleccionar herramientas para mi lista, califico cada una en una escala de 0 (no ofrece la funcionalidad) a 5 (destaca en esta área) para cada funcionalidad principal listada a continuación. Luego, calculo la puntuación total de la herramienta como porcentaje. Cada herramienta debe alcanzar una puntuación total mínima del 65% para ser considerada para su inclusión.
- Registro de experimentos: Compruebo si la herramienta captura automáticamente métricas, hiperparámetros y telemetría del sistema de las ejecuciones de entrenamiento o si requiere la instrumentación manual del SDK para cada dato.
- Comparación y visualización de ejecuciones: Las tablas comparativas lado a lado son un punto de partida, pero busco gráficos interactivos como los de coordenadas paralelas que ayudan a identificar patrones entre decenas de ejecuciones en tus proyectos de ML.
- Versionado de artefactos y modelos: Evalúo cómo cada herramienta versiona conjuntos de datos, puntos de control de modelos y salidas, incluyendo si vincula los artefactos con la ejecución exacta que los generó.
- Compatibilidad con frameworks de ML: La herramienta debe cubrir frameworks que realmente utilice tu equipo, desde PyTorch y TensorFlow hasta Hugging Face Transformers y XGBoost, con un código envoltorio mínimo.
- Reproducibilidad y linaje: Busco herramientas que capturen commits de código, snapshots de dependencias y el estado del conjunto de datos para que puedas volver a ejecutar un experimento de hace seis meses y obtener el mismo resultado.
- Colaboración y compartición: Los equipos que trabajan en diferentes husos horarios necesitan espacios de trabajo compartidos, acceso basado en roles y la posibilidad de comentar o compartir ejecuciones específicas sin exportar CSVs de un lado a otro.
Una vez que tengo una lista de herramientas que cumplen estos criterios, considero qué distingue a cada plataforma.
Factores diferenciadores (Lo que distingue a los proveedores)
Así es como comparo y contrasto diferentes proveedores:
Características destacadas
La optimización de hiperparámetros es un factor diferenciador clave. Busco funcionalidad de barrido integrada que automatice la búsqueda en ejecuciones distribuidas y visualice el rendimiento entre configuraciones en una sola vista. El monitoreo de recursos en tiempo real también aporta valor—cuando puedes seguir el uso de GPU y memoria durante el entrenamiento, detectas cuellos de botella antes de que una ejecución desperdicie horas de cómputo. Los reportes colaborativos cierran el ciclo para equipos grandes, donde tableros compartibles reemplazan hojas de cálculo manuales y permiten a los científicos de datos discutir los resultados con los interesados sin cambiar de herramienta.
Más allá de las características
La flexibilidad de despliegue importa más de lo que muchos equipos esperan. Evalúo si una herramienta permite instalaciones autogestionadas o entornos aislados para equipos que trabajan con propiedad intelectual o datos regulados. La escalabilidad es otro factor que reviso: registrar miles de ejecuciones concurrentes no debe degradar el rendimiento de consultas ni generar picos de costos imprevisibles. También destaca la experiencia de incorporación, donde una buena documentación de inicio rápido y foros comunitarios activos permiten a tu equipo instrumentar scripts de entrenamiento en horas, no semanas.
Cómo elegir herramientas para el seguimiento de experimentos de ML
Es fácil perderse entre largas listas de funciones y estructuras de precios complejas. Para ayudarte a mantenerte enfocado mientras avanzas en tu propio proceso de selección de software, aquí tienes una lista de factores a tener en cuenta:
| Factor | Qué considerar |
|---|---|
| Escalabilidad | ¿Puede la herramienta gestionar el volumen y la frecuencia de experimentos que esperas a medida que tu equipo y tus datos crecen? |
| Integraciones | ¿Se conecta directamente con tus frameworks de ML preferidos, herramientas de orquestación y sistemas de despliegue? |
| Personalización | ¿Puedes adaptar los campos de metadatos, pasos del flujo de trabajo e informes a los requerimientos únicos de tu equipo? |
| Facilidad de uso | ¿Los investigadores e ingenieros de tu equipo encontrarán la interfaz intuitiva, o existe una curva de aprendizaje pronunciada? |
| Implementación y onboarding | ¿Qué tan rápido puedes pasar de la compra al seguimiento de tu primer experimento? ¿Qué recursos se requieren para la configuración? |
| Costo | ¿Existen precios por uso, tarifas de almacenamiento o complementos requeridos que sean claros y previsibles de acuerdo a tus necesidades previstas? |
| Salvaguardas de seguridad | ¿La herramienta ofrece cifrado, permisos granulares y autenticación para proteger datos sensibles? |
| Requisitos de cumplimiento | ¿La herramienta te ayuda a cumplir con regulaciones industriales, de clientes o geográficas (SOC 2, ISO 27001, GDPR)? |
¿Qué son las herramientas para el seguimiento de experimentos de ML?
Las herramientas para el seguimiento de experimentos de ML son plataformas de software que registran, organizan y versionan experimentos de modelos de aprendizaje automático, incluyendo sus parámetros, código, conjuntos de datos y métricas. Estas herramientas ayudan a tu equipo a almacenar el historial de experimentos, comparar resultados y reproducir completamente ejecuciones pasadas, lo que facilita la colaboración y la auditoría a medida que los flujos de trabajo del proyecto se vuelven más complejos.
Características de las herramientas para el seguimiento de experimentos de ML
Al seleccionar herramientas de seguimiento de experimentos de ML, presta atención a las siguientes características clave:
- Registro de experimentos: Registra los parámetros de cada ejecución de entrenamiento, configuraciones, referencias al código fuente y métricas para mantener una clara trazabilidad de auditoría.
- Comparación de ejecuciones: Permite visualizar y analizar varios experimentos en paralelo para entender cómo diferentes ajustes o cambios afectan los resultados.
- Versionado de artefactos: Versiona automáticamente los conjuntos de datos, modelos de ML versionados y otros resultados para que siempre puedas reproducir o construir sobre trabajos anteriores.
- Integraciones con frameworks: Se conecta directamente con marcos de trabajo de ML populares, facilitando el inicio del seguimiento con cambios mínimos en tu flujo de trabajo.
- Seguimiento de linaje: Traza toda la cadena desde los datos en bruto hasta el modelo final, apoyando la reproducibilidad y los requisitos de cumplimiento normativo.
- Herramientas de colaboración: Permite a varios usuarios comentar, documentar hallazgos y compartir resultados dentro de tu equipo.
- Metadatos personalizados: Te permite añadir campos o etiquetas específicas del proyecto, de modo que puedas categorizar los experimentos según las necesidades de tu flujo de trabajo.
- Control de acceso basado en roles: Restringe el acceso a datos y acciones sensibles, respaldando la gobernancia y los estándares de seguridad a nivel organizacional.
- Tableros y visualizaciones: Genera informes personalizables y visualizaciones de datos para destacar rápidamente tendencias y anomalías en los datos de tus experimentos.
- Búsqueda y filtrado: Permite que tu equipo encuentre fácilmente experimentos, ejecuciones y artefactos relevantes por parámetro, fecha u otro criterio, ahorrando tiempo a medida que crece el proyecto.
Funciones de IA Comunes en Herramientas de Seguimiento de Experimentos de ML
Además de las características estándar mencionadas arriba, muchas de estas soluciones incorporan IA con funciones como:
- Detección automatizada de anomalías: Utiliza IA para monitorear las métricas de los experimentos y señalar patrones inusuales o valores atípicos, ayudando a los equipos a detectar deriva de datos o comportamientos inesperados del modelo de manera temprana.
- Sugerencias inteligentes de hiperparámetros: Aplica aprendizaje automático para recomendar valores óptimos de hiperparámetros basándose en los datos históricos de experimentos, reduciendo el trabajo manual y acelerando el ajuste del modelo.
- Búsqueda de experimentos en lenguaje natural: Permite a los usuarios buscar y filtrar experimentos usando lenguaje conversacional, facilitando el acceso y la comprensión de resultados a las partes interesadas no técnicas.
- Asignación predictiva de recursos: Utiliza IA para predecir las necesidades de cómputo y memoria de próximas ejecuciones, ayudando a planificar recursos y evitar cuellos de botella.
- Resúmenes automatizados de experimentos: Aprovecha IA para generar resúmenes concisos de los resultados de los experimentos, destacando hallazgos clave y tendencias para informes y toma de decisiones más rápidas.
Beneficios de las Herramientas de Seguimiento de Experimentos de ML
Implementar herramientas de seguimiento de experimentos de ML ofrece varios beneficios para tu equipo y tu negocio. Aquí tienes algunos a los que puedes aspirar:
- Reproducibilidad de experimentos: Rastrea parámetros, conjuntos de datos y detalles del entorno para recrear y validar fácilmente experimentos anteriores.
- Colaboración optimizada: Tableros compartidos, comentarios y documentación de proyectos ayudan a los equipos a trabajar juntos y comunicar resultados de manera efectiva.
- Desarrollo de modelos más rápido: Comparaciones paralelas de ejecuciones y versionado automatizado de artefactos aceleran los ciclos de experimentos y la toma de decisiones.
- Gestión centralizada del conocimiento: Todo el historial del proyecto y los metadatos de los experimentos se almacenan en un solo sitio, preservando el conocimiento institucional mientras el equipo crece.
- Mejor cumplimiento y auditabilidad: El seguimiento de linaje y los registros de auditoría integrados respaldan las necesidades regulatorias y los estándares de gobernanza empresarial.
- Control de costos de recursos: El monitoreo de recursos en vivo y la asignación predictiva permiten a los equipos optimizar el uso del hardware y evitar gastos innecesarios.
- Soporte de flujo de trabajo personalizable: Campos de metadatos flexibles y opciones de flujo de trabajo se adaptan a los procesos y preferencias existentes de tu equipo.
Costos y Precios de las Herramientas de Seguimiento de Experimentos de ML
Seleccionar herramientas de seguimiento de experimentos de ML requiere comprender los distintos modelos y planes de precios disponibles. Los costes varían según las características, el tamaño del equipo, complementos y más. La siguiente tabla resume los planes más comunes, sus precios promedio y las características típicas incluidas en las soluciones de herramientas de seguimiento de experimentos de ML:
Tabla Comparativa de Planes para Herramientas de Seguimiento de Experimentos de ML
| Tipo de plan | Precio medio | Características comunes |
|---|---|---|
| Plan gratuito | $0 | Seguimiento básico de experimentos, usuarios limitados, soporte comunitario y proyectos públicos. |
| Plan personal | $5-$25/usuario/mes | Experimentos ilimitados, aumento de almacenamiento, proyectos privados e integraciones básicas. |
| Plan empresarial | $30-$70/usuario/mes | Herramientas de colaboración, acceso según el rol, integraciones avanzadas, seguridad mejorada y registros de auditoría. |
| Plan para empresas | $80-$150/usuario/mes | Opciones de implementación personalizadas, SSO/SAML, herramientas de cumplimiento, soporte premium y personalización avanzada. |
Preguntas frecuentes sobre herramientas de seguimiento de experimentos de ML
Aquí tienes respuestas a preguntas frecuentes sobre herramientas de seguimiento de experimentos de ML:
¿Requieren estas herramientas mucha configuración o cambios de código?
No, la mayoría de las herramientas ofrecen SDKs o plugins ligeros que te permiten comenzar a registrar experimentos con cambios mínimos de código. Generalmente puedes integrar el seguimiento en tus scripts con solo unas pocas líneas.
¿Cómo ayudan estas herramientas con el cumplimiento del equipo y las auditorías?
Registran los parámetros, el código y los resultados de cada ejecución, crean historiales trazables de experimentos y mantienen pistas de auditoría—facilitando la documentación del cumplimiento y el intercambio de evidencia durante revisiones o auditorías.
¿Funcionan estas soluciones con Jupyter notebooks?
Sí, la mayoría de las herramientas de seguimiento de experimentos de ML están diseñadas para funcionar directamente en Jupyter notebooks, así como en scripts y pipelines, por lo que no tienes que cambiar tu flujo de trabajo.
¿Qué pasa si mi equipo supera el plan gratuito?
Puedes actualizar a una opción de pago para más usuarios, mayores límites de almacenamiento, integraciones avanzadas y funciones empresariales. Revisa bien los precios para que la transición no te tome por sorpresa.
¿Puedo almacenar datos sensibles o propietarios con estas herramientas?
Sí, pero deberías revisar las medidas de seguridad del proveedor, como cifrado, controles de acceso y certificaciones de cumplimiento para garantizar que tus datos permanezcan protegidos. Las opciones on-premise o en nube privada pueden ofrecer aún más control.