Die 10 besten NoSQL-Datenbanken im Test für 2026

Beste NoSQL-Datenbanken Shortlist


Die besten NoSQL-Datenbanken helfen Teams, große, unstrukturierte oder sich schnell verändernde Datensätze zu verwalten, ohne die starren Schemaanforderungen traditioneller relationaler Systeme. Sie ermöglichen schnellere Abfragen, einfacheres Skalieren und bieten bessere Unterstützung für verteilte Architekturen – unerlässlich für moderne Anwendungsfälle wie Echtzeitanalysen, Content-Management und IoT-Datenverarbeitung.
Teams beginnen oft mit der Suche nach NoSQL-Lösungen, wenn sie an die Grenzen relationaler Datenbanken stoßen: langsame Abfragen bei hoher Last, Schemaänderungen, die Arbeitsabläufe stören, oder Schwierigkeiten bei der Synchronisierung von Daten über verschiedene Regionen hinweg. Herausforderungen wie inkonsistente Performance, Probleme bei der Datenreplikation und komplexe Skalierungsanforderungen können das Wachstum ohne die richtige Plattform erheblich erschweren.
Ich habe mit Entwicklungs- und Datenteams zusammengearbeitet, die NoSQL-Datenbanken für alles mögliche evaluierten – von Analyse-Pipelines bis hin zu hoch frequentierten Webanwendungen – und dabei deren Performance, Replikations-Setups und Integration in Cloud-Umgebungen getestet.
In diesem Leitfaden erfahren Sie, welche NoSQL-Datenbanken starke Performance bieten, das Skalieren vereinfachen und die Flexibilität bei der Datenstruktur liefern, die Ihre Anwendungen tatsächlich benötigen.
Warum Sie unseren Software-Bewertungen vertrauen können
Wir testen und bewerten seit 2023 Software. Als Technologie-Führungskräfte wissen wir, wie kritisch und herausfordernd es ist, die richtige Entscheidung bei der Softwareauswahl zu treffen.
Wir investieren viel in gründliche Recherche, um unserer Zielgruppe zu helfen, bessere Kaufentscheidungen zu treffen. Wir haben über 2.000 Tools für verschiedene Technikanwendungsfälle getestet und mehr als 1.000 umfassende Softwarebewertungen geschrieben. Erfahren Sie wie wir transparent bleiben und unsere Methodik der Softwarebewertung.
NoSQL-Datenbanken im Überblick
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | Beste serverlose NoSQL-Datenbank | Kostenlose Stufe verfügbar | Ab $1/Monat | Website | |
| 2 | Beste NoSQL-Datenbank für vollwertige ACID-Transaktionen | Kostenlose Versionen verfügbar | Ab $789/Kern/Jahr | Website | |
| 3 | Beste Weitspalten-NoSQL-Datenbank | Kostenlose Version verfügbar | Kein kostenpflichtiger Tarif | Website | |
| 4 | Beste NoSQL-Datenbank in Sachen Benutzerfreundlichkeit | Kostenlose Version verfügbar | Schreiboperationen ab $1.25/Million Anfragen; Leseoperationen ab $0.25/Million Anfragen. | Website | |
| 5 | Beste spaltenorientierte Datenbank zur Speicherung sehr großer Datensätze | Kostenlose Version verfügbar | Keine kostenpflichtige Option | Website | |
| 6 | Beste dokumentenbasierte NoSQL-Datenbank | Kostenlose Version verfügbar | Dediziert ab $57/Monat oder serverlos ab $0,10/Million Lesevorgänge | Website | |
| 7 | Beste Cloud- und Grid-basierte NoSQL-Datenbank | Kostenlose Version verfügbar | Feste Lizenz ab $15.456/Jahr | Website | |
| 8 | Beste graphbasierte NoSQL-Datenbank | Kostenlose Version verfügbar | Preis auf Anfrage | Website | |
| 9 | Am besten für SQL-ähnliche Funktionalität | Kostenlose Testphase verfügbar | Ab $0,28/Stunde pro Knoten | Website | |
| 10 | Beste Key-Value-NoSQL-Datenbank | Kostenlose Version verfügbar | Ab $7/Monat oder $0.881/Stunde | Website |
-

TestDevLab
Visit Website -
Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8


NoSQL-Datenbanken im Test
Hier sind meine Empfehlungen der 12 besten NoSQL-Datenbanken und die Einsatzszenarien, in denen sie jeweils am besten abschneiden.
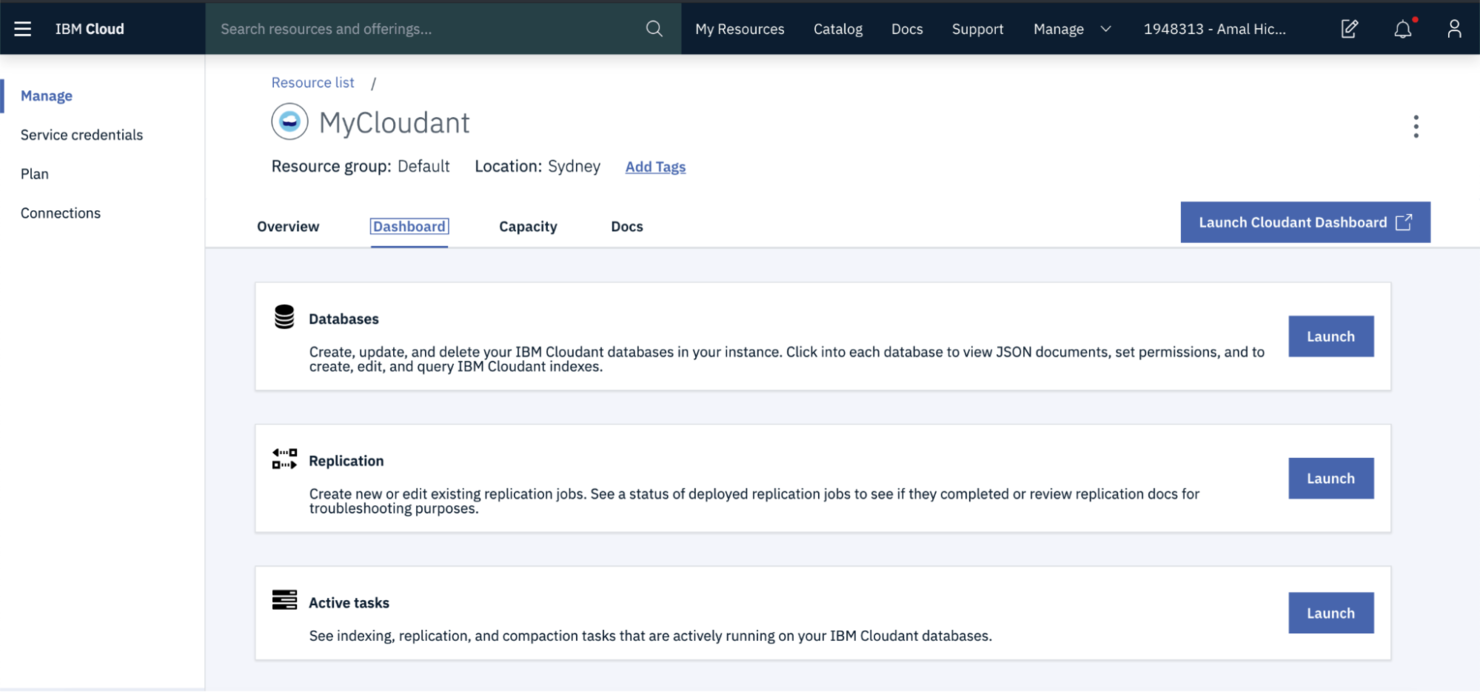
IBM Cloud ist eine vollständig verwaltete, verteilte Datenbank, die auf einem serverlosen Schema basiert. Das bedeutet, Sie müssen sich nicht um die Serverkonfiguration und Skalierung kümmern. So können Sie Datenbanken erstellen und betreiben, ohne sich um das Backend sorgen zu müssen.
Warum ich IBM Cloudant gewählt habe: Ich habe IBM Cloudant ausgewählt, weil es äußerst sicher ist. Sie bezahlen nur für die tatsächlich genutzten Ressourcen und können je nach Datenbedarf flexibel skalieren. Besonders überzeugt hat mich IBM Key Protect, das mir vollständige Kontrolle und Transparenz über verschlüsselte Schlüssel gewährt hat.
Besondere Funktionen und Integrationen von IBM Cloudant:
Funktionen sind unter anderem die Multi-Region-Replikation, hohe Verfügbarkeit und automatisches Failover für global verteilte Anwendungen. Außerdem gibt es eine integrierte Volltextsuche auf Apache Lucene-Basis, die Abfragen und Analysen großer Datensätze effizienter macht. Darüber hinaus bietet Cloudant Offline-First-Synchronisation, sodass mobile und Web-Anwendungen auch bei wechselnder Konnektivität reibungslos funktionieren.
Integrationen bestehen mit IBM App Connect, IBM Cloud Log Analysis, IBM Watson, Apache Spark, IBM Cloud Functions, Apache CouchDB, Tableau und IBM Cognos Analytics.
Pros and Cons
Pros:
- Umfassende Sicherheit
- Serverloses Schema für einfache Konfiguration
- Kostenlose Version verfügbar
Cons:
- Teilweise veraltete Dokumentation
- Langsame Indizierung großer Datenbanken
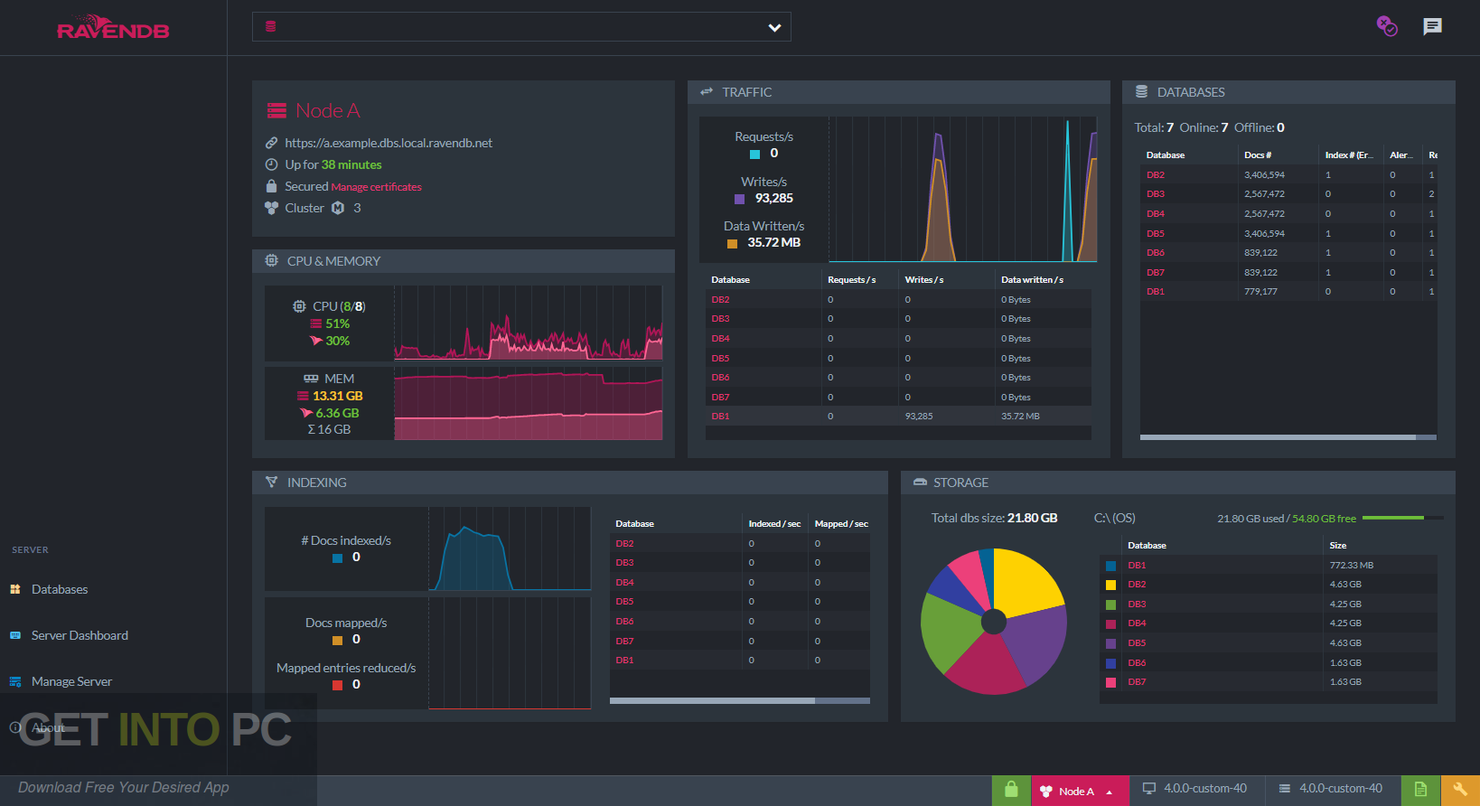
RavenDB ist eine Multi-Dokumenten-Datenbank, die ACID-Transaktionen (Atomarität, Konsistenz, Isolation und Dauerhaftigkeit) unterstützt. Dies hilft, zu verhindern, dass Daten versehentlich in einen inkonsistenten Zustand geraten. Die Plattform wird von landesweit anerkannten Unternehmen wie Toyota, Verizon und Medicaid verwendet.
Warum ich RavenDB ausgewählt habe: Neben der optisch ansprechenden Benutzeroberfläche gefällt mir, dass RavenDB ACID-Transaktionen unterstützt. Dies stellt sicher, dass Transaktionen Daten nur auf vorhersehbare Weise verändern können und dass diese Änderungen immer gespeichert werden, selbst bei einem Systemabsturz.
Hervorstechende Funktionen und Integrationen von RavenDB:
Funktionen umfassen eine integrierte Volltextsuche, die ein schnelles und effizientes Abfragen von unstrukturierten Daten ermöglicht, ohne dass eine externe Suchmaschine erforderlich ist. Zudem bietet es eine automatische Indizierung, wodurch der Bedarf an manueller Abfrageoptimierung reduziert und die Leistung im Laufe der Zeit verbessert wird. Darüber hinaus unterstützt RavenDB Multi-Master-Replikation, die eine hohe Verfügbarkeit und Echtzeit-Synchronisierung in verteilten Umgebungen gewährleistet.
Integrationen umfassen FastReport, Elasticsearch, Grafana, Power BI, Node.js, .NET, Python und Kubernetes.
Pros and Cons
Pros:
- Benutzerfreundliche Oberfläche
- ACID-Transaktionen sorgen für mehr Datenkonsistenz und Zeitersparnis
- On-Premise- und Cloud-Versionen
Cons:
- Enterprise-Version ist teuer
- Geringe Community-Unterstützung und Dokumentation
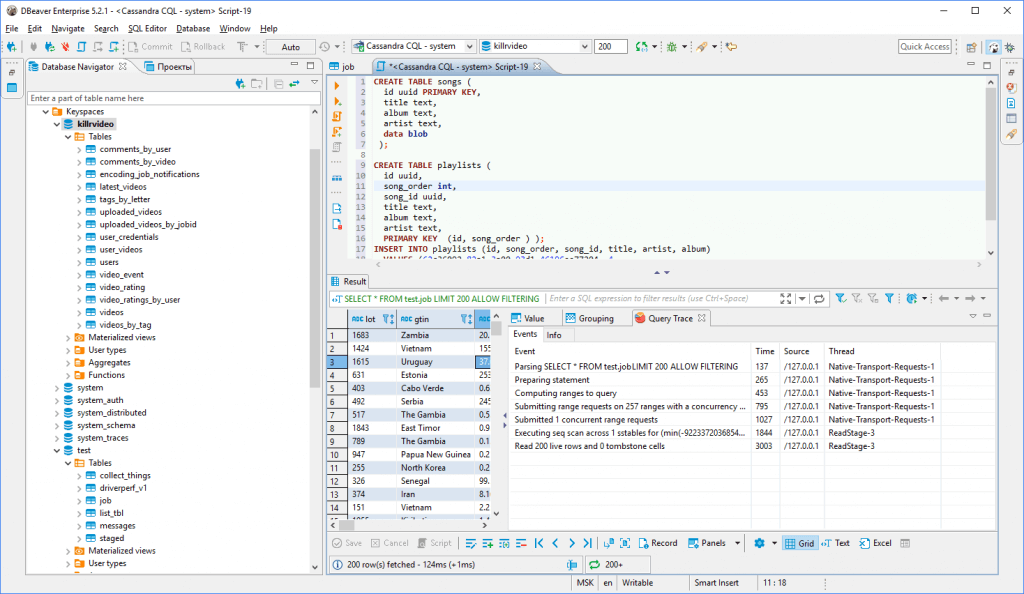
Apache Cassandra ist eine Open-Source-Weitspalten-Datenbank, die hybride Cloud- und On-Premises-Replikation sowie Audit-Logging unterstützt. Da die Plattform frei verfügbar ist und von Tausenden Unternehmen genutzt wird, halte ich sie für eine ausgezeichnete Lösung für Unternehmen, die umfangreiche, aktive Datensätze zu geringen Kosten verwalten möchten.
Warum ich Apache Cassandra gewählt habe: Cassandra hebt sich als leistungsstarke Weitspalten-Datenbank mit viel Skalierbarkeit hervor. Sie können dem Cluster horizontal weitere Server hinzufügen, wenn Ihr Datenbedarf steigt. Außerdem verwendet Cassandra ein Column-Family-Datenmodell, das für Anwender traditioneller relationaler Datenbanken zugänglich ist.
Herausragende Funktionen und Integrationen von Cassandra:
Funktionen sind u.a. eine Masterless-Architektur, die dafür sorgt, dass es keinen Single Point of Failure gibt und auch bei Knotenfehlern eine kontinuierliche Verfügbarkeit gewährleistet wird. Zudem bietet sie leichte Transaktionen (LWT) mit Paxos, wodurch bei Bedarf eine starke Konsistenz ohne Leistungseinbußen ermöglicht wird. Darüber hinaus bewältigt Cassandra schreibintensive Workloads und ist somit ideal für Anwendungen, die eine schnelle Datenaufnahme im großen Maßstab erfordern.
Integrationen umfassen New Relic, IRI Voracity, DbVisualizer, Sematext Cloud, Flex83, Retool und DbSchema.
Pros and Cons
Pros:
- Unterstützung für hybride Cloud (privat und öffentlich) sowie On-Premises
- Kann große Mengen an unstrukturierten Daten verarbeiten
- Horizontale Skalierbarkeit zur Anpassung an wachsende Datenmengen
Cons:
- Keine Ad-hoc-Abfragen
- Erfordert regelmäßige manuelle Wartung
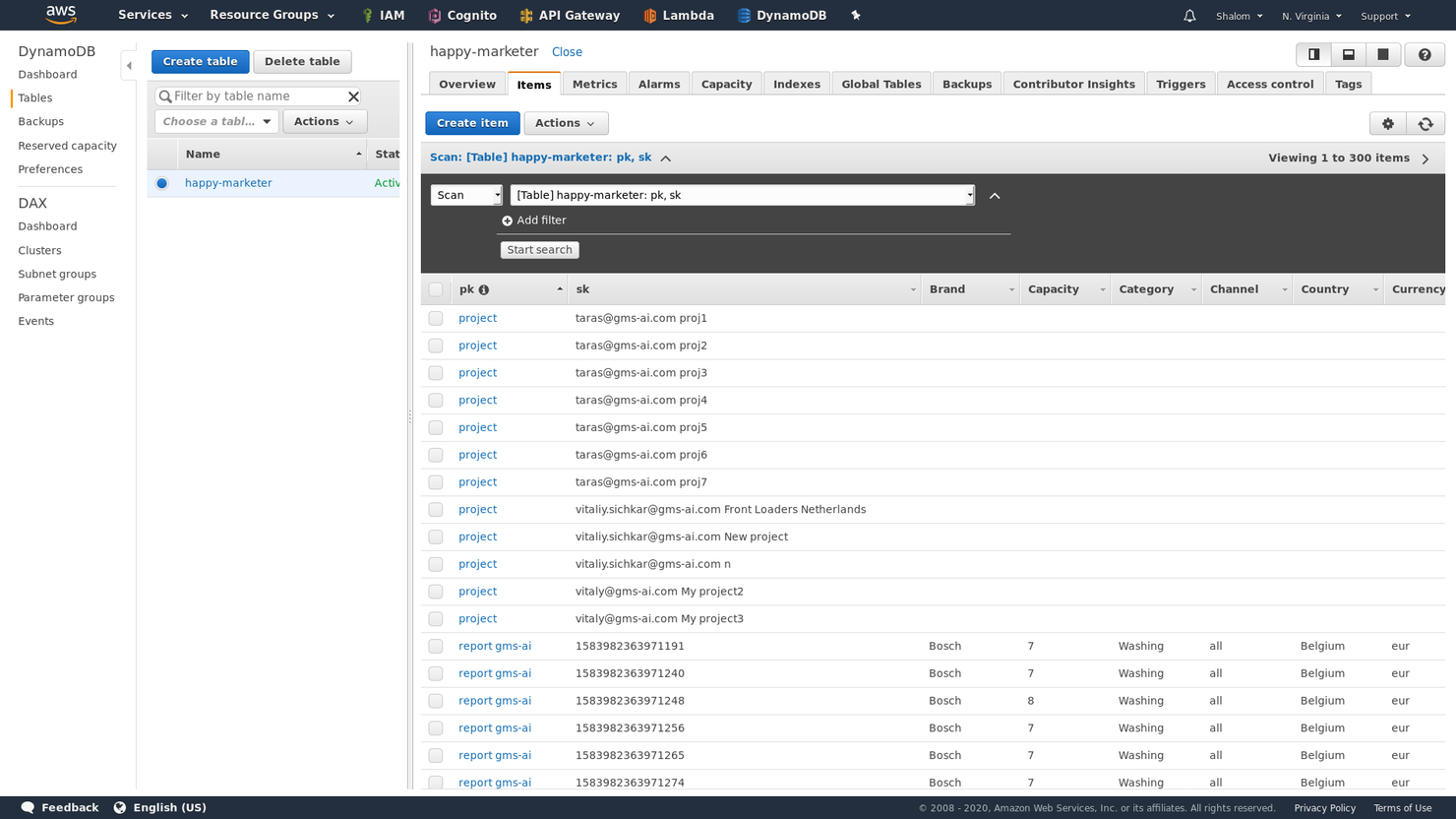
Amazon DynamoDB ist eine NoSQL-Datenbank, die sowohl Dokument- als auch Schlüssel-Wert-Datenmodelle unterstützt. Es handelt sich um einen Cloud-basierten Dienst, mit dem Sie Elemente, Tabellen und Attribute speichern können. Sie können den Service entweder im Pay-as-you-go-Modell oder mit bereitgestellter Kapazität nutzen, je nachdem, was zu Ihrer Arbeitslast passt.
Warum ich Amazon DynamoDB gewählt habe: Abgesehen davon, dass es sich um eine vollständig verwaltete NoSQL-Datenbank mit hoher Verfügbarkeit und Haltbarkeit handelt, gefällt mir an Amazon DynamoDB besonders die Integration mit Amazon Web Services (AWS). Dadurch können Sie mehr mit Ihren Daten machen, zum Beispiel indem Sie Daten aus Ihren S3-Buckets importieren und exportieren. Außerdem habe ich die Benutzerfreundlichkeit geschätzt, die durch ausgezeichnete Dokumentation und eine aufgeräumte, intuitive Benutzeroberfläche ermöglicht wird.
Herausragende Funktionen und Integrationen von Amazon DynamoDB:
Funktionen beinhalten On-Demand- und Kapazitätsplanungsmodi, die es den Nutzern ermöglichen, Kosten und Leistung je nach Arbeitslastanforderungen zu optimieren. Es werden auch globale Tabellen unterstützt, die eine Multi-Region-Replikation mit automatischer Synchronisierung für weltweit verteilte Anwendungen ermöglichen. Zusätzlich bietet DynamoDB Streams das Erfassen von Ereignissen in Echtzeit, wodurch es einfach ist, AWS Lambda-Funktionen auszulösen und sich in ereignisgesteuerte Architekturen zu integrieren.
Integrationen umfassen AWS Lambda, Amazon S3, Amazon Kinesis, AWS Glue, Apache Spark, Kubernetes, Grafana und Elasticsearch.
Pros and Cons
Pros:
- Einfach einzurichten und zu verwenden
- Ausführliche Dokumentation und Support
- AWS-Integration zur Erweiterung der Funktionalität
Cons:
- Keine lokale Bereitstellungsoption
- Nur in der AWS-Cloud verfügbar
HBase ist eine spaltenorientierte NoSQL-Datenbank auf dem Hadoop Distributed File System (HDFS). Die HBase-Plattform eignet sich besonders gut für das Management umfangreicher Daten, da das System nahezu vollständig fehlertolerant ist.
Warum ich HBase ausgewählt habe: HBase fiel mir besonders auf, weil es äußerst gut mit großen Datenmengen umgehen kann. Es lässt sich auf Tausende von Servern skalieren und kann Daten im Terabyte-Bereich aufnehmen. Außerdem hat mir gefallen, dass HBase HDFS nutzt, um Fehler auf allen Servern zu erkennen und sich schnell und automatisch zu erholen. Es überzeugte beim Minimieren von Ausfallzeiten für große Systeme.
Herausragende Funktionen und Integrationen von HBase:
Funktionen umfassen die tiefe Integration mit dem Hadoop Distributed File System (HDFS), was eine effiziente Speicherung und Verarbeitung von riesigen Datensätzen über verteilte Cluster hinweg ermöglicht. Es verfügt über eine automatische Sharding-Funktion, die Daten gleichmäßig verteilt und eine nahtlose horizontale Skalierung ohne manuellen Aufwand erlaubt. Darüber hinaus unterstützt HBase Echtzeit-Lese- und Schreibzugriffe mit starker Konsistenz und ist somit ideal für Anwendungen, die geringe Latenz bei großen Datenmengen benötigen.
Integrationen umfassen Hive, Apache Hadoop, Apache Spark, Apache Kafka, Apache Hive, Zookeeper, Flink und Grafana.
Pros and Cons
Pros:
- Kostenlos nutzbar
- Integration mit Apache Hadoop
- Horizontal skalierbar über Tausende von Servern
Cons:
- Weniger integrierte Funktionen als Cassandra – ist auf Drittanbieter-Integrationen angewiesen
- CPU- und speicherintensiv
MongoDB ist eine Open-Source-Datenbank auf Dokumentenbasis. Sie kann strukturierte Daten im gängigen JavaScript Object Notation (JSON)-Format oder im proprietären Binary JSON (BSON)-Format speichern. BSON kann mehr Datentypen als JSON speichern und codiert den Typ und die Länge einer Information, was es Maschinen erleichtert, die Daten zu parsen (formatierten Text in eine bestimmte Datenstruktur umzuwandeln).
Warum ich MongoDB gewählt habe: Ich habe MongoDB ausgewählt, weil es besonders stark in dem ist, was dokumentenbasierte Datenbanken am besten können: flexible Datenmodelle bereitzustellen, die sich zusammen mit den Anforderungen Ihrer Anwendung weiterentwickeln können. Da MongoDB horizontal skalierbar ist, können Sie schnell neue Server hinzufügen, um größere Datenmengen in Clustern zu bewältigen. Es eignet sich besonders gut für Anwendungen mit hohen Leistungsanforderungen.
Herausragende Funktionen und Integrationen von MongoDB:
Funktionen beinhalten ein flexibles, dokumentenbasiertes Datenmodell, mit dem Entwickler Daten so speichern und abfragen können, dass sie realen Objekten entsprechen. Außerdem bietet es native Unterstützung für Sharding, wodurch eine nahtlose horizontale Skalierung über verteilte Umgebungen hinweg ermöglicht wird. Zusätzlich enthält MongoDB ein Aggregations-Framework, das komplexe Datenumwandlungen und Analysen vereinfacht, ohne dass externe Verarbeitungstools benötigt werden.
Integrationen umfassen Netlify, SAML SSO-Anbieter, HashiCorp Terraform und HashiCorp Fault. APIs sind ebenfalls verfügbar.
Pros and Cons
Pros:
- BSON erweitert den Datentyp-Support und erleichtert das Parsen
- Umfassende Dokumentation und große Community-Unterstützung
- Kein festgelegtes Schema verbessert Flexibilität und Skalierbarkeit
Cons:
- BSON benötigt mehr Speicherplatz als JSON
- Einige Performanceprobleme bei größeren Datenbanken
Oracle Coherence ist eine In-Memory-Key-Value-Datenbank, die starke Skalierbarkeit und Leistung für Unternehmensanwendungen bietet. Durch die Speicherung von Daten mit niedriger Latenz für Lese-, Schreib- und Abfragevorgänge können Unternehmen – die mehrere Anwendungen in verschiedenen Programmiersprachen betreiben – Datenkonsistenz in Echtzeit schnell aufrechterhalten.
Warum ich Oracle Coherence gewählt habe: Was mir an Oracle Coherence besonders gefällt, ist die Unterstützung für asynchrones Event-Streaming. Das bedeutet, dass Sie Ereignismodelle in Ihre ereignisgesteuerte Architektur integrieren können, wodurch eine effiziente Kommunikation zwischen Microservices wie Servern und Clients möglich ist.
Herausragende Funktionen und Integrationen von Oracle Coherence:
Funktionen umfassen Echtzeit-Data-Grid-Fähigkeiten, die eine ultraschnelle In-Memory-Datenverarbeitung für Hochleistungsanwendungen ermöglichen. Zudem wird dynamisches Skalieren geboten, sodass Cluster sich automatisch je nach Arbeitslast erweitern oder verkleinern können. Darüber hinaus unterstützt Coherence föderiertes Caching, das durch die Synchronisierung von Caches in Echtzeit die Datenkonsistenz über mehrere geografische Regionen hinweg sicherstellt.
Integrationen beinhalten Spring, Oracle WebLogic Server und die Oracle NoSQL-Datenbank.
Pros and Cons
Pros:
- Kostenlos nutzbar
- Viele Funktionen zur Wahrung der Datenkonsistenz
- Starke Community-Unterstützung und Dokumentation
Cons:
- Begrenzte Standardsicherheit
- Schwieriger Upgrade-Prozess
Neo4j ist eine graphbasierte NoSQL-Datenbank, die zur Entwicklung von Anwendungen, zur Erstellung und Bereitstellung von Künstlicher Intelligenz (KI)- und Machine-Learning (ML)-Pipelines sowie zur Durchführung detaillierter Analysen verwendet wird. Sie eignet sich besonders für Datenwissenschaftler, Anwendungsentwickler und ähnliche Unternehmen. Mit der intuitiven, graphbasierten Benutzeroberfläche lassen sich Muster und Beziehungen in großen Datenmengen einfach erkennen.
Warum ich Neo4j gewählt habe: Neo4j hat mein Interesse durch seine klare Benutzeroberfläche und fortschrittlichen Diagrammfunktionen geweckt. Ich fand es hilfreich, um verborgene Erkenntnisse in komplexen Datenbeziehungen aufzudecken, bei denen Trends und Muster nicht sofort ersichtlich sind. Außerdem hat mich beeindruckt, wie einfach die Plattform horizontal skaliert werden kann. Dafür sorgt das autonome Clustering, das Ihre Datensätze automatisch anhand Ihrer Vorgaben und Regeln auf die optimalen Server verteilt.
Herausragende Funktionen und Integrationen von Neo4j:
Funktionen beinhalten die native Graphdatenbank-Architektur, die besonders effiziente Abfragen von Beziehungen ermöglicht und klassische relationale Datenbanken bei verknüpften Daten übertrifft. Außerdem steht Cypher zur Verfügung, eine leistungsfähige Abfragesprache für Graphdatenbanken, die besonders für intuitive und komplexe beziehungsbasierte Recherchen entwickelt wurde. Darüber hinaus bietet Neo4j fortschrittliche Visualisierungstools, mit denen Nutzer Datenbeziehungen erkunden und Erkenntnisse gewinnen können, ohne fundierte SQL-Kenntnisse zu benötigen.
Integrationen beinhalten Apache Spark, Kafka Connect und den Neo4j Data Warehouse Connector.
Pros and Cons
Pros:
- ACID-Transaktionen gewährleisten Datenbankoperationen über alle Knoten hinweg
- Starke Community und Dokumentation
- Überraschend einfach zu erlernen und zu verwenden
Cons:
- Individuelle Preisgestaltung für die Enterprise Edition
- Neue Versionen können neue Fehler einführen
Couchbase Capella ist eine Cloud-Datenbankplattform, die die Geschwindigkeit und Flexibilität einer NoSQL-Datenbank mit den Vorteilen einer SQL-Datenbank kombiniert. Sie verfügt außerdem über eine Anwendungsentwicklungslösung namens Capella App Services, mit der Sie IoT-, Mobile- und Edge-Anwendungen entwerfen und bereitstellen können.
Warum ich Couchbase Capella ausgewählt habe: Ich habe Couchbase Capella ausgewählt, weil es für Anwender zugänglich ist, die bereits mit SQL-Datenbanken vertraut sind. Es verwendet die Abfragesprache SQL++ für Operationen und Analysen. Mir gefällt, wie dies den Übergang von traditionellen relationalen Datenbanken zu nicht-relationalen Datenbanken mit vertrauten Funktionen wie ACID-Transaktionen und hierarchischen Schemata vereinfacht.
Herausragende Funktionen und Integrationen von Couchbase Capella:
Funktionen umfassen die integrierte Memory-First-Architektur, die eine geringe Latenz für Hochgeschwindigkeitsanwendungen gewährleistet. Außerdem bietet sie fortschrittliche mobile Synchronisation mit Couchbase Lite und Sync Gateway, was sie zur ausgezeichneten Wahl für 'Offline-First'-Anwendungen macht. Zusätzlich unterstützt Capella Multi-Model-Fähigkeiten, sodass Benutzer mit Schlüssel/Wert-, Dokument- und Graphdaten in einem einzigen Datenbanksystem arbeiten können.
Integrationen umfassen Apache Kafka, Kubernetes, Confluent Cloud, Workato und Microsoft Azure.
Pros and Cons
Pros:
- Vereint die Vorteile von SQL- und NoSQL-Datenbanken auf einer Plattform
- Integrierte Lösung für App-Entwicklung und -Bereitstellung
- Sehr gutes Preis-Leistungs-Verhältnis
Cons:
- Hohe Lernkurve
- Begrenzte Integrationen
Redis ist eine Open-Source-In-Memory-Key-Value-Datenbank. Sie liefert Antwortzeiten im Sub-Millisekundenbereich, was sie ideal für alle Arten von Echtzeitanwendungen macht, wie etwa das Aktualisieren von Ranglisten in einem Online-Multiplayer-Videospiel oder das Bereitstellen von Echtzeit-Versandinformationen für einen Kunden, der auf eine Lieferung wartet.
Warum ich Redis ausgewählt habe: Mich hat die schnelle Performance von Redis beeindruckt. Es speichert Daten im Arbeitsspeicher statt auf einer physischen Festplatte oder Solid-State-Drive (SSD), sodass beim Abrufen von Daten der Umweg über den Datenträger entfällt, was es effizienter als viele Mitbewerber macht.
Herausragende Funktionen und Integrationen von Redis
Funktionen beinhalten die In-Memory-Datenspeicherung, die extrem niedrige Latenzzeiten und schnelle Datenabrufe ermöglicht und sich somit ideal für Echtzeitanwendungen eignet. Zudem unterstützt Redis Datenpersistenz durch Snapshot-Erstellung und den Append-only-File-Modus (AOF), was es Nutzern erlaubt, Geschwindigkeit und Datensicherheit auszubalancieren. Zusätzlich bietet Redis integrierte Unterstützung für Pub/Sub-Messaging, womit es eine starke Wahl für ereignisgesteuerte Architekturen und Echtzeit-Benachrichtigungen ist.
Integrationen umfassen RediSearch, RedisJSON, RedisGraph, RedisBloom, redis-cell, RedisTimeSeries und RedisAI.
Pros and Cons
Pros:
- In-Memory-Datenspeicherung sorgt für schnelle Performance
- Nützlich für Echtzeitanwendungen wie Gaming-Ranglisten und Analysen
- Automatisches Failover gewährleistet hohe Verfügbarkeit
Cons:
- Keine grafische Benutzeroberfläche (GUI)
- Mangelnde Dokumentation
Weitere NoSQL-Datenbanken
Im Folgenden finden Sie eine Liste alternativer NoSQL-Datenbanken, die ich ebenfalls empfehle:
- OrientDB
E Multi-Model-NoSQL-Datenbank
- AstraDB
Am besten für die Entwicklung und Skalierung von Echtzeit-Anwendungen
- DataStax Enterprise
Am besten für null Serverausfallzeiten
- Dgraph
Am besten geeignet für Fehlertoleranz
- Apache Drill
E schemafreie Datenbank


{kind=link}
Weitere Software- & Tool-Bewertungen
Falls Sie hier noch nicht das Passende gefunden haben, werfen Sie einen Blick auf diese weiteren getesteten und bewerteten Tool-Kategorien.
- Netzwerküberwachungssoftware
- Serverüberwachung
- SD-Wan-Lösungen
- Infrastruktur-Monitoring-Tools
- Packet Sniffer
- Anwendungsüberwachung
Wie ich NoSQL-Datenbanken bewerte
Ich teile meine Bewertung in grundlegende Anforderungen – wie horizontale Skalierbarkeit und flexible Datenmodelle – und die Differenzierungsmerkmale auf, welche die für Echtzeit- und Hochdurchsatz-Workloads entwickelten Tools voneinander unterscheiden.
Kernfunktionen (Mindestanforderungen für diese Liste)
Wenn ich Tools für meine Liste auswähle, bewerte ich jedes einzelne auf einer Skala von 0 (bietet diese Funktion nicht) bis 5 (hervorragend in diesem Bereich) für jede der unten aufgelisteten Kernfunktionen. Anschließend berechne ich die Gesamtpunktzahl des Tools als Prozentsatz. Jedes Tool muss eine Mindestgesamtpunktzahl von 75% erreichen, um für die Aufnahme in Betracht gezogen zu werden.
- Flexibles Datenmodell: Ich prüfe, ob eine Datenbank Dokument-, Key-Value-, Wide-Column- oder Graphstrukturen unterstützt – und ob sie die Weiterentwicklung des Schemas ohne erzwungene Migrationen ermöglicht.
- Horizontale Skalierbarkeit: Die Verteilung von Daten auf verschiedene Nodes ist für wachsende Workloads entscheidend, daher bewerte ich, wie jedes Tool Sharding, Partitionierung und elastische Cluster-Erweiterung handhabt.
- Hohe Verfügbarkeit & Replikation: Ich betrachte das Failover-Verhalten und Replikationsoptionen, insbesondere für Multi-Region-Setups, bei denen ein Ausfall in einer Zone nicht die gesamte Anwendung lahmlegen darf.
- Abfrage- & Indexierungsfunktionen: Über die Basissuche per Schlüssel hinaus bewerte ich sekundäres Indexing, Aggregationspipelines und Filterung – Funktionen, auf die Sie sich beispielsweise für Analyse-Dashboards oder Suche verlassen.
- Performance im großen Maßstab: Latenz und Durchsatz unter hoher gleichzeitiger Last sagen viel aus, daher vergleiche ich dokumentierte Benchmarks und das Verhalten bei großen Datenmengen in realen Szenarien.
- APIs & SDK-Support für Entwickler: Gute Sprachabdeckung für Python, Java, Node.js, Go und andere erleichtert die Einführung, deshalb untersuche ich die Qualität der offiziellen SDKs und die Tiefe der API-Dokumentation.
Sobald ich eine Liste der Tools habe, die diese Kriterien erfüllen, schaue ich mir an, was jede Plattform besonders macht.
Differenzierende Faktoren (Was Anbieter unterscheidet)
So vergleiche und kontrastiere ich die verschiedenen Anbieter:
Herausragende Eigenschaften
Fein justierbare Konsistenz ist ein bedeutender Unterschied. Ich prüfe, ob eine Datenbank erlaubt, die Konsistenz auf Abfrageebene einzustellen – nützlich, wenn Echtzeitabfragen und Hintergrundanalysen nebeneinander stattfinden. Eingebaute Vektorensuche ist wichtig für Teams, die KI-gestützte Funktionen wie Empfehlungssysteme oder semantische Suche ohne zusätzliche Tools entwickeln wollen. Ich achte zudem auf native Change Data Capture, da das Streamen von Datenänderungen zu Plattformen wie Kafka für ereignisbasierte Architekturen essenziell ist.
Mehr als nur Funktionen
Flexibilität beim Deployment bewerte ich früh – ob eine Datenbank als verwalteter Cloud-Service, On-Premises oder über mehrere Anbieter hinweg betrieben werden kann, bestimmt maßgeblich, wie gut sie zu Ihrer Infrastrukturstrategie passt. Sicherheit und Compliance spielen ebenfalls eine große Rolle; ich prüfe nach RBAC, Verschlüsselung im Ruhezustand und bei der Übertragung sowie nach Zertifizierungen wie SOC 2 oder HIPAA für Teams, die mit sensiblen Daten arbeiten. Die Tiefe des Ökosystems rundet das Gesamtbild ab. Konnektoren für Kafka, Terraform-Provider und Kubernetes-Operatoren zeigen, wie reibungslos sich eine Datenbank in vorhandene DevOps-Workflows einfügt.
So wählen Sie eine NoSQL-Datenbank aus
Wenn Sie NoSQL-Datenbanken vergleichen, testen und auswählen, sollten Sie Folgendes berücksichtigen:
- Welches Problem wollen Sie lösen - Beginnen Sie damit, die Lücke in den NoSQL-Datenbankfunktionen zu identifizieren, die Sie schließen möchten, um die benötigten Funktionen und Merkmale des Tools zu klären.
- Wer wird es nutzen müssen - Um Kosten und Anforderungen einzuschätzen, überlegen Sie, wer die Plattform nutzen wird und wie viele Lizenzen Sie benötigen. Sie sollten prüfen, ob nur das Datenteam oder die gesamte Organisation Zugriff benötigt. Ist das geklärt, sollten Sie abwägen, ob Benutzerfreundlichkeit für alle oder Geschwindigkeit für Ihre technischen Power-User prioritär ist.
- Mit welchen anderen Tools muss es funktionieren - Klären Sie, welche Tools ersetzt werden, welche Tools bleiben und welche integriert werden müssen. Dazu zählen Ihre bestehende Dateninfrastruktur, verschiedene Datenquellen und Ihr gesamter Technologie-Stack. Sie müssen auch entscheiden, ob die Tools miteinander integriert werden sollen oder ob Sie mehrere Tools durch eine konsolidierte NoSQL-Datenbank ersetzen können.
- Welche Ergebnisse sind wichtig - Überlegen Sie, welches Ergebnis das Tool liefern muss, um als Erfolg zu gelten. Denken Sie darüber nach, welche Fähigkeiten Sie gewinnen oder was Sie verbessern wollen, und wie Sie den Erfolg messen werden. Sie können NoSQL-Datenbankfunktionen ewig vergleichen, aber wenn Sie nicht an die gewünschten Ergebnisse denken, könnten Sie viel wertvolle Zeit verschwenden.
- Wie es in Ihrem Unternehmen funktioniert - Erwägen Sie Lösungen im Zusammenhang mit Ihren Arbeitsabläufen und Ihrer Datenmanagement-Methodik. Bewerten Sie, was gut funktioniert und welche Bereiche Probleme verursachen, die behoben werden müssen. Denken Sie daran: Jedes Unternehmen ist anders – gehen Sie nicht davon aus, dass ein Tool nur wegen seiner Popularität auch in Ihrem Unternehmen funktioniert.
Trends bei NoSQL-Datenbanken
Während meiner Recherche habe ich zahlreiche Produktankündigungen, Pressemitteilungen und Release-Logs von verschiedenen NoSQL-Datenbankanbietern ausgewertet. Hier sind einige der wichtigsten Trends, die ich beobachte:
- Edge-fähige Datenbanken: Einige NoSQL-Tools unterstützen jetzt Edge-Computing-Setups, bei denen Daten näher am Nutzer gespeichert und verarbeitet werden. Das ist nützlich für Anwendungen mit sehr geringen Latenzanforderungen oder Einsätzen an entfernten Standorten.
- Multi-Modell-Unterstützung: Immer mehr NoSQL-Datenbanken unterstützen mehrere Datenmodelle wie Key-Value, Dokument, Graph und Spalte in einem System. Das gibt Teams die Flexibilität, verschiedene Workloads auszuführen, ohne Plattformen wechseln zu müssen.
- Serverlose Architektur: Einige Anbieter bieten jetzt serverlose NoSQL-Datenbanken, die automatisch skalieren und nutzungsbasiert abgerechnet werden. Das ist eine gute Option für Teams, die keine Infrastruktur verwalten möchten, wie etwa bei Amazon DynamoDB oder Azure Cosmos DB.
- Stärkere Konsistenzoptionen: Traditionell haben NoSQL-Datenbanken die Verfügbarkeit gegenüber Konsistenz priorisiert, aber nun bieten Tools einstellbare Konsistenzniveaus. Das ist hilfreich, wenn Sie mehr Kontrolle darüber brauchen, wie aktuell oder exakt Ihre Daten sind.
- Eingebaute Volltextsuche: Anbieter integrieren zunehmend Suchfunktionen direkt, sodass Sie keine separate Engine wie Elasticsearch zusätzlich benötigen. Das spart Einrichtungszeit und hält alles an einem Ort.
Was sind NoSQL-Datenbanken?
No Structured Query Language (SQL)-Datenbanken sind nicht-relationale Datenbanken, die die Speicherung, den Abruf und die Verwaltung von Daten ohne ein festes Schema ermöglichen. Diese Tools werden vorwiegend von Softwareentwicklern, Datenarchitekten und IT-Fachleuten genutzt, die mit großen Mengen an strukturierten, semi-strukturierten oder unstrukturierten Daten arbeiten.
Der Wechsel hin zu NoSQL-Datenbanken ist motiviert durch die Notwendigkeit, die Einschränkungen traditioneller relationaler Datenbanken bei der Bewältigung von Volumen, Geschwindigkeit und Vielfalt heutiger Daten zu adressieren. Der Gesamtnutzen dieser Tools liegt in ihrer Fähigkeit, robuste, flexible und kosteneffiziente Lösungen für komplexe Datenmanagement-Anforderungen in verschiedenen Branchen bereitzustellen.
Funktionen von NoSQL-Datenbanken
Dies sind die wichtigsten Merkmale, auf die ich achte, wenn ich NoSQL-Datenbanken bewerte:
- Skalierbarkeit: Diese Funktion ermöglicht es der Datenbank, sich an wachsende Datenanforderungen anzupassen. Die Fähigkeit zum Ausweiten mithilfe verteilter Architektur ist essenziell, um große Datenmengen nahtlos zu verarbeiten, ohne dabei die Leistung zu beeinträchtigen.
- Flexible Datenmodelle: NoSQL-Datenbanken bieten flexible Datenmodelle für die Speicherung und Verwaltung unterschiedlicher Datentypen. Diese Flexibilität ist entscheidend, um der vielfältigen und dynamischen Natur unstrukturierter Daten gerecht zu werden, ohne dass vordefinierte Schemata erforderlich sind.
- Hohe Performance: Für spezifische Datenmodelle und Zugriffsmuster optimiert, wodurch eine schnelle Datenabfrage und hoher Datendurchsatz gewährleistet werden. Hohe Performance ist entscheidend in Szenarien, in denen zeitkritischer Datenzugriff für Entscheidungsfindung und operative Effizienz unerlässlich ist.
- Hohe Verfügbarkeit: Diese Funktion stellt sicher, dass die Datenbank auch bei Hardware-Ausfällen oder Wartungsarbeiten zugänglich bleibt. Hohe Verfügbarkeit ist kritisch für Anwendungen, die kontinuierliche Betriebsbereitschaft und Echtzeitzugriff auf Daten erfordern.
- Datenreplikation: Ermöglicht das Kopieren von Daten über mehrere Server hinweg und verbessert damit die Datenverfügbarkeit sowie die Notfallwiederherstellung. Datenreplikation ist wichtig, um die Datenintegrität aufrechtzuerhalten und kontinuierlichen Datenzugriff in geografisch verteilten Systemen zu ermöglichen.
- Partitionstoleranz: Die Fähigkeit, auch bei Netzwerk- oder Partitionierungsfehlern weiter zu arbeiten. Partitionstoleranz ist in verteilten Systemen essenziell, da so der Betrieb auch dann gewährleistet ist, wenn Teile des Systems nicht effektiv kommunizieren.
- Multi-Model-Unterstützung: Unterstützung verschiedener Datenmodelle wie Dokument, Schlüssel-Wert, Graph und Spaltenfamilie innerhalb einer einzelnen Datenbank. Multi-Model-Unterstützung bietet die Vielseitigkeit, verschiedene Datentypen und Zugriffsmuster zu verwalten, wodurch die Datenarchitektur vereinfacht wird.
- Schemalos: Ermöglicht die Speicherung von Daten ohne vordefiniertes Schema und bietet Flexibilität im Umgang mit Änderungen an Datenstrukturen. Schemalose Datenbanken sind ideal für Anwendungen, die schnelle Entwicklungen ermöglichen müssen, ohne eine häufige Neugestaltung der Datenbank zu erfordern.
- Integriertes Caching: Verbessert die Performance durch das Speichern häufig abgerufener Daten im Arbeitsspeicher. Integriertes Caching reduziert die Datenzugriffszeiten erheblich und steigert so die Nutzererfahrung und Systemeffizienz.
- Sicherheitsfunktionen: Umfassende Sicherheitsmaßnahmen inklusive Verschlüsselung, Zugriffskontrolle und Auditierung. Robuste Sicherheitsfunktionen schützen sensible Daten vor unautorisiertem Zugriff und Datenlecks, was für Vertrauen und Compliance entscheidend ist.
Vorteile von NoSQL-Datenbanken
NoSQL-Datenbanken bieten eine flexible, skalierbare und effiziente Möglichkeit zur Verwaltung von Daten und sind damit eine attraktive Option für Organisationen und Entwickler, die mit großen Mengen unterschiedlicher Datentypen arbeiten. Im Gegensatz zu traditionellen relationalen Datenbanken sind NoSQL-Datenbanken darauf ausgelegt, unstrukturierte und semi-strukturierte Daten zu verarbeiten und bieten einzigartige Vorteile, die Geschäftsprozesse und Datenmanagementstrategien erheblich verbessern können. Nachfolgend sind fünf Hauptvorteile von NoSQL-Datenbanken für Nutzer und Unternehmen aufgeführt:
- Skalierbarkeit: Müheloses Datenwachstum durch verteilte Architektur. NoSQL-Datenbanken sind von Natur aus so konzipiert, dass sie sich über mehrere Server und Rechenzentren skalieren lassen. So können Unternehmen wachsende Datenmengen problemlos handhaben, Wachstum unterstützen und dabei die Leistung sicherstellen.
- Flexibilität: Anpassung an sich ändernde Datenmodelle ohne Ausfallzeiten. Die schemalose Natur von NoSQL-Datenbanken ermöglicht das Speichern unstrukturierter und semi-strukturierter Daten. Dies bietet die Flexibilität, Anwendungen rasch zu entwickeln, ohne ein starres Datenbankschema anpassen zu müssen, wodurch Entwicklungszyklen beschleunigt werden.
- Hohe Performance: Schnelleren Datenzugriff und -verarbeitung erreichen. NoSQL-Datenbanken können für bestimmte Operationen, etwa bei großen Datenmengen und Echtzeitanwendungen, überlegene Leistung liefern, indem sie optimierte Speicherungs-, Caching- und Abrufmechanismen nutzen, die auf bestimmte Datenmodelle zugeschnitten sind.
- Kosteneffizienz: Kostenersparnis durch effiziente Datenspeicherung und -verarbeitung. Die verteilte Struktur von NoSQL-Datenbanken, kombiniert mit der Fähigkeit, große Mengen unterschiedlicher Daten effizient zu verwalten, kann im Vergleich zu traditionellen Datenbanksystemen zu beträchtlichen Einsparungen bei Hardware, Speicherung und Wartung führen.
- Umgang mit Datenvielfalt: Speicherung und Abfrage verschiedenster Datentypen. NoSQL-Datenbanken unterstützen mehrere Datenmodelle – darunter Schlüssel-Wert, Dokument, Wide-Column und Graph-Formate. Damit können Organisationen eine einzige Datenbank für verschiedene Datentypen und Anwendungen nutzen, das Datenmanagement vereinfachen und die analytischen Fähigkeiten stärken.
Kosten & Preise für NoSQL-Datenbanken
NoSQL-Datenbanken bieten eine Vielzahl von Tarif- und Preismodellen, die auf die Bedürfnisse von Unternehmen jeder Größe zugeschnitten sind – von Start-ups bis zu Großunternehmen. Diese Datenbanken sind darauf ausgelegt, große Mengen strukturierter und unstrukturierter Daten effizient zu verwalten und stellen Skalierbarkeit, Flexibilität und hohe Performance bereit.
Die Preismodelle unterscheiden sich erheblich je nach NoSQL-Datenbank-Anbieter und basieren in der Regel auf Faktoren wie Datenspeicherung, Lese-/Schreibdurchsatz, Anzahl der Transaktionen und dem benötigten Support-Level.
Tarifvergleichstabelle für NoSQL-Datenbanken
Hier ist eine zusammenfassende Übersicht über die verschiedenen Preismodelle und typische Kostenbereiche, die für diese Tools üblicherweise angeboten werden:
| Tarifart | Durchschnittlicher Preis | Übliche Funktionen |
|---|---|---|
| Kostenlos | $0 | Basiszugriff, begrenzter Speicher und Durchsatz, Community-Support |
| Standard | $100 - $1,000/Monat | Erhöhter Speicher und Durchsatz, technischer Support, grundlegende Sicherheitsfunktionen |
| Professional | $1,000 - $10,000/Monat | Erweiterte Sicherheitsfunktionen, höhere Durchsatz- und Speicherkapazitäten, 24/7-Support |
| Enterprise | Individuelle Preisgestaltung | Individuelle Lösungen, dedizierter Support, unbegrenzter Speicher und Durchsatz |
NoSQL-Datenbank FAQs
Hier finden Sie die am häufigsten gestellten Fragen zu NoSQL-Datenbanken.
Wie entscheide ich, welchen NoSQL-Datenbanktyp ich für meinen Tech-Stack verwenden soll?
Beginnen Sie damit, Ihre wichtigsten Anwendungsfälle wie Echtzeitanalysen, Content-Management oder verteiltes Caching den Kategorien von NoSQL-Datenbanken (Dokumenten-, Key-Value-, Spalten-, Graphdatenbanken usw.) zuzuordnen. Prüfen Sie die Datenstruktur, die Anforderungen an die Skalierbarkeit und die Integration in Ihre bestehende Architektur. Vergleichen Sie führende Tools hinsichtlich der Kompatibilität mit Ihrer Programmiersprache und Cloud-Infrastruktur. Wenn Sie unsicher sind, erstellen Sie Proofs-of-Concepts mit der engeren Auswahl und beziehen Sie frühzeitig Ihre Technikleitung ein.
Welche Skalierungsgrenzen haben NoSQL-Datenbanken im Unternehmenseinsatz?
NoSQL-Datenbanken skalieren in der Regel horizontal, aber Beschränkungen ergeben sich durch Faktoren wie Netzwerklatenz, Datenaufteilung und Managementkomplexität in großem Maßstab. Einige Systeme haben harte Grenzen bei der Clustergröße, den sekundären Indizes oder der Konsistenz geografisch verteilter Daten. Testen Sie vor der Wahl einer Datenbank deren Skalierungsverhalten unter Enterprise-Lasten und analysieren Sie Praxisbeispiele anderer Unternehmen mit ähnlichen Anforderungen.
Können NoSQL-Datenbanken ACID-Transaktionen für kritische Workloads unterstützen?
Ja, einige NoSQL-Datenbanken bieten ACID-konforme Transaktionen an, jedoch variiert die Unterstützung je nach Plattform und Konfiguration. Dokumenten- und Graphdatenbanken ermöglichen oft lokale oder clusterweite Transaktionen, während Key-Value-Stores meist auf Eventual Consistency setzen. Wenn Sie unternehmensweit strikte ACID-Garantien benötigen, prüfen Sie das Transaktionsmodell jedes Tools sorgfältig und testen Sie mit echten Workloads.
Welche Sicherheitspraktiken sollten CTOs beim Einsatz von NoSQL-Datenbanken beachten?
Erzwingen Sie stets Authentifizierung und rollenbasierte Zugriffe. Aktivieren Sie Verschlüsselung für gespeicherte und übertragene Daten. Aktualisieren Sie regelmäßig die Datenbanksoftware, um Sicherheitslücken zu schließen. Begrenzen Sie die Netzwerkanbindung – betreiben Sie Dienste in privaten Subnetzen oder nutzen Sie VPNs. Überwachen Sie Logs und richten Sie Alarme für verdächtige Aktivitäten ein. Prüfen Sie die Sicherheitsrichtlinien des Anbieters im Hinblick auf Ihre Compliance-Anforderungen und auditieren Sie Ihre Systeme vierteljährlich.
Wie kann ich ohne Unterbrechungen von einer relationalen Datenbank zu NoSQL migrieren?
Eine erfolgreiche Migration beginnt mit sorgfältiger Zuordnung der Schemata und schrittweisen Rollouts. Führen Sie parallele Systeme und synchronisieren Sie die Daten in Echtzeit während der Umstellung. Automatisieren Sie die Datentransformation mithilfe spezialisierter Migrations-Tools oder individueller Skripte. Testen Sie das neue System mit realen Workloads, um Ausfallzeiten zu minimieren. Halten Sie Ihr Team stets auf dem Laufenden und stellen Sie Rückfallpläne bereit, falls Probleme auftreten.
Wie geht es weiter?
Wenn Sie sich gerade mit der Recherche zu NoSQL-Datenbanken beschäftigen, nehmen Sie Kontakt zu einem SoftwareSelect-Berater für kostenlose Empfehlungen auf.
Sie füllen ein Formular aus und führen ein kurzes Gespräch, in dem Ihre spezifischen Anforderungen besprochen werden. Anschließend erhalten Sie eine Shortlist von Softwarelösungen zur Überprüfung. Sie werden sogar während des gesamten Kaufprozesses unterstützt – einschließlich Preisverhandlungen.