10 Meilleurs Outils ETL Open Source analysés en 2026

Meilleurs outils ETL open source : sélection


Les meilleurs outils ETL open source aident les équipes à automatiser l'extraction, la transformation et le chargement des données afin de maintenir des ensembles de données précis et cohérents entre les systèmes. Ils facilitent la gestion de sources de données complexes, permettent d'appliquer des transformations à grande échelle et réduisent l'effort manuel dans la gestion des pipelines.
Lorsque les pipelines dépendent de scripts personnalisés, que des modifications de schéma provoquent des échecs silencieux ou que les équipes n'ont pas de visibilité sur la façon dont les données circulent entre les systèmes, la qualité et la fiabilité des données peuvent en pâtir. Ces problèmes ralentissent l'analyse, augmentent le temps de maintenance et créent des frictions entre les équipes d'ingénierie et de données.
Fort de plus de 20 ans d'expérience en tant que Chief Technology Officer, j'ai testé et évalué des dizaines d'outils ETL open source pour juger de leur performance, de la qualité de leurs intégrations et de leur facilité d'utilisation. Ce guide présente les meilleures options pour des workflows évolutifs et des opérations de données plus fiables. Chaque analyse aborde en détail les fonctionnalités, avantages et inconvénients, ainsi que les cas d'usage idéaux pour vous aider à choisir le bon outil.
Pourquoi faire confiance à nos avis sur les logiciels
Nous testons et évaluons des logiciels de développement SaaS depuis 2023. En tant qu'experts techniques, nous savons combien il est crucial et difficile de faire le bon choix lors de la sélection d'un logiciel. Nous investissons dans des recherches approfondies pour aider notre audience à prendre de meilleures décisions d'achat de logiciels.
Nous avons testé plus de 2 000 outils pour différents cas d'usage en développement SaaS et rédigé plus de 1 000 avis logiciels complets. Découvrez comment nous restons transparents et consultez notre méthodologie d'évaluation logicielle.
Table of Contents
- Meilleure sélection de logiciels
- Pourquoi nous faire confiance
- Comparer les spécifications
- Avis
- Autres outils ETL open source
- Autres avis
- Critères de sélection
- Comment choisir
- Tendances des outils ETL open source
- Qu'est-ce qu'un outil ETL open source ?
- Fonctionnalités
- Avantages
- Coûts et tarification
- FAQs
Résumé des meilleurs outils ETL open source
Ce tableau comparatif résume les détails tarifaires de mes meilleurs choix d’outils ETL open source pour vous aider à trouver celui qui convient à votre budget et à vos besoins professionnels.
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | Idéal pour les tâches de données complexes | Essai gratuit disponible | À partir de $5,500/unité/an | Website | |
| 2 | Idéal pour le traitement des données de logs | Essai gratuit disponible | À partir de 95 $/mois | Website | |
| 3 | Idéal pour le scripting ETL en Python | Not available | Gratuit à utiliser | Website | |
| 4 | Idéal pour la transformation de données | Essai gratuit de 30 jours | À partir de $4/utilisateur/mois | Website | |
| 5 | Idéal pour les modèles d'intégration | Gratuit à utiliser | Website | ||
| 6 | Idéal pour l’intégration automatisée de données | Essai gratuit de 14 jours + démo gratuite | À partir de $239/mois | Website | |
| 7 | Idéal pour les modèles d'intégration | Not available | Gratuit à utiliser | Website | |
| 8 | Idéal pour le streaming de données en temps réel | Offre gratuite disponible | Gratuit | Website | |
| 9 | Idéal pour l'automatisation des flux de données | Not available | Gratuit à utiliser | Website | |
| 10 | Idéal pour des solutions ETL évolutives | Offre gratuite disponible | Gratuit | Website |
-

TestDevLab
Visit Website -
Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8


Avis sur les meilleurs outils ETL open source
Vous trouverez ci-dessous mes résumés détaillés des meilleurs outils ETL open source ayant intégré ma sélection. Mes avis offrent un aperçu complet des fonctionnalités clés, points forts et faibles, intégrations et cas d’usage idéaux pour chaque outil, afin de vous aider à choisir le mieux adapté à vos besoins.
CloverDX est une plateforme d'intégration de données qui s'adresse aux utilisateurs métier et aux équipes informatiques en automatisant, orchestrant et transformant les données. Elle prend en charge diverses options de déploiement, ce qui la rend polyvalente pour différents besoins professionnels.
Pourquoi j'ai choisi CloverDX : CloverDX est conçue pour les tâches de données complexes grâce à son interface intuitive et ses options de déploiement flexibles, incluant sur site et les services cloud tels qu'AWS, Azure et Google Cloud. Elle propose des services de données pour l'accès API et des outils de collaboration, permettant à votre équipe de travailler efficacement dans différents environnements. L'intégration d'un catalogue de données assure un accès fiable aux données, ce qui est essentiel pour maintenir l'intégrité des informations. Ces fonctionnalités font de CloverDX un choix remarquable pour les équipes traitant des processus de données complexes.
Fonctionnalités et intégrations remarquables :
Fonctionnalités incluent une interface intuitive pour les utilisateurs métier, des services de données pour l'accès API, et un catalogue de données pour un accès fiable aux informations. Ces éléments garantissent une gestion et un accès efficaces aux données. La plateforme propose également des outils de collaboration pour renforcer le travail d'équipe.
Intégrations incluent AWS, Azure, Google Cloud, Snowflake, Salesforce, Microsoft SQL Server, Oracle, PostgreSQL, MongoDB et Kafka.
Pros and Cons
Pros:
- Prend en charge des processus de données complexes
- Options de déploiement polyvalentes
- Capacités solides d'accès API
Cons:
- Courbe d'apprentissage potentiellement raide
- Nécessite une expertise technique
Logstash est un pipeline de traitement de données open source permettant aux développeurs et aux équipes informatiques de collecter, transformer et stocker les journaux provenant de différentes sources. Il est conçu pour gérer de grands volumes de données de journalisation, ce qui le rend idéal pour les organisations cherchant à centraliser et analyser leurs informations de logs.
Pourquoi j’ai choisi Logstash : Logstash excelle dans le traitement des données de logs, offrant une architecture de pipeline flexible qui permet d’agréger les journaux issus de sources multiples. L’outil propose des capacités de filtrage et de transformation puissantes, offrant à votre équipe la possibilité d’adapter les données selon des besoins spécifiques. Le traitement en temps réel de Logstash garantit que vos données de logs sont toujours à jour et exploitables. Sa compatibilité avec Elasticsearch et Kibana en fait un excellent choix pour les utilisateurs de la suite Elastic Stack.
Fonctionnalités et intégrations remarquables :
Fonctionnalités : architecture de pipeline flexible prenant en charge des transformations complexes, permettant de personnaliser le traitement des logs. Les capacités de traitement en temps réel assurent une actualisation constante des données de journalisation. L’outil offre également des options de filtrage robustes pour ajuster les données à vos besoins spécifiques.
Intégrations : Elasticsearch, Kibana, Beats, AWS, Azure, Google Cloud, Kafka, RabbitMQ, JDBC et Redis.
Pros and Cons
Pros:
- Gère de gros volumes de logs
- Traitement des données en temps réel
- Architecture de pipeline flexible
Cons:
- Peut être gourmand en ressources
- Analytique intégrée limitée
pygrametl est un framework open source en Python pour développer des processus ETL. Il a été conçu comme une alternative aux programmes BI graphiques tout en offrant la même facilité d'utilisation. Il prend en charge CPython et Jython, permettant ainsi aux développeurs ETL d'utiliser du code Java existant et des pilotes JDBC.
Les développeurs peuvent extraire des données à partir de nombreuses sources disponibles dans pygrametl, telles que SQL, CSV et Pandas. Les utilisateurs peuvent également définir leurs propres sources de données. La plateforme propose des filtres et des agrégateurs pour transformer les données. Parmi les agrégateurs par défaut, on trouve AVG, Count, CountDistinct, Max, Min et Sum.
pygrametl peut charger les données transformées dans tout entrepôt de données prenant en charge la modélisation dimensionnelle. Le système fournit des structures pour définir des tables de faits et des dimensions, y compris des dimensions à évolution lente et des dimensions en flocon de neige.
Les développeurs peuvent télécharger pygrametl gratuitement.
Pentaho Kettle est un outil ETL open-source destiné aux ingénieurs de données et aux analystes métiers ayant besoin d'effectuer des transformations de données complexes. Il propose une interface visuelle pour concevoir des pipelines de données, facilitant ainsi la gestion des flux de données et l'exécution efficace des transformations.
Pourquoi j'ai choisi Pentaho Kettle : Il est reconnu pour ses capacités de transformation de données, offrant une interface visuelle de type glisser-déposer qui simplifie la création de workflows complexes. Kettle propose un support étendu pour de nombreuses sources de données, permettant à votre équipe d'intégrer des données depuis de multiples origines. Son interface graphique réduit la nécessité de coder en profondeur, ce qui est avantageux pour les équipes avec peu de compétences en programmation. La flexibilité de l'outil dans la gestion de différents types et formats de données en fait un choix polyvalent pour divers besoins métiers.
Fonctionnalités remarquables & intégrations :
Fonctionnalités : interface visuelle de type glisser-déposer, simplifiant la création de workflows et permettant de construire des transformations de données complexes sans coder. L'outil accepte un large éventail de sources de données, rendant l'intégration aisée. La flexibilité de Kettle dans la gestion de multiples types et formats de données assure la compatibilité avec des environnements de données variés.
Intégrations : Oracle, MySQL, PostgreSQL, Microsoft SQL Server, MongoDB, Amazon Redshift, Google BigQuery, Salesforce, SAP et Hadoop.
Pros and Cons
Pros:
- Interface visuelle pour les transformations
- Gère différents types de données
- Support étendu des sources de données
Cons:
- Peut être gourmand en ressources
- Configuration initiale complexe
Apache Camel est un framework d'intégration open-source conçu pour les développeurs et architectes ayant besoin de mettre en œuvre des modèles d'intégration d'entreprise. Il facilite le routage et la médiation des messages entre systèmes, ce qui le rend idéal pour des scénarios d'intégration complexes.
Pourquoi j'ai choisi Apache Camel : Il excelle dans l'utilisation de modèles d'intégration pour simplifier la connectivité entre différents systèmes. Camel prend en charge un large éventail de protocoles et de formats de données, garantissant à votre équipe une connexion aisée entre des systèmes disparates. Son langage spécifique au domaine (DSL) offre une façon flexible de définir des règles de routage et de médiation, ce qui est crucial pour gérer des intégrations complexes. La capacité de l'outil à s'intégrer à divers points de terminaison offre une polyvalence inégalée dans la conception de solutions d'intégration.
Fonctionnalités et intégrations remarquables :
Fonctionnalités propose un ensemble riche de modèles d'intégration d'entreprise qui simplifient le processus d'intégration. Le langage spécifique au domaine de l'outil vous permet de définir facilement des règles de routage complexes. Apache Camel prend également en charge une large gamme de formats de données et de protocoles, ce qui assure la compatibilité avec de nombreux systèmes.
Intégrations incluent AWS, Apache Kafka, ActiveMQ, RabbitMQ, Salesforce, Google Cloud, Azure, JMS, File et FTP.
Pros and Cons
Pros:
- Nombreux modèles d'intégration
- Large prise en charge des formats de données
- Intégration polyvalente des points de terminaison
Cons:
- La documentation peut être limitée
- Consomme beaucoup de ressources pour les grandes installations
Hevo Data est une plateforme ETL et d’intégration de données destinée aux équipes data à la recherche de pipelines de données fiables et automatisés. Elle facilite l’ingestion de données provenant de diverses sources avec une configuration minimale et sans programmation, améliorant ainsi la précision des données et la prise de décision.
Pourquoi j’ai choisi Hevo Data : Elle se distingue par l’intégration automatisée des données, avec des fonctionnalités telles que la surveillance en temps réel des pipelines et la réplication rapide des données, garantissant à votre équipe des informations à jour avec un minimum d’efforts. Les fonctions de conformité et de sécurité de Hevo offrent une tranquillité d’esprit, en particulier pour les utilisateurs en entreprise. La tarification transparente de la plateforme signifie qu’il n’y a pas de frais cachés, ce qui est un grand avantage pour la gestion des budgets. Son interface conviviale permet de gérer facilement les données sans connaissances approfondies en programmation.
Fonctionnalités et intégrations remarquables :
Fonctionnalités : surveillance en temps réel des pipelines pour maintenir la fraîcheur des données, options de gestion avancées pour un meilleur contrôle, et fonctions de conformité et de sécurité pour protéger les données sensibles. Ces caractéristiques aident votre équipe à travailler efficacement et en toute sécurité. Hevo propose également une réplication rapide des données pour garantir la cohérence des informations.
Intégrations : incluent Salesforce, Google Analytics, Amazon Redshift, Snowflake, BigQuery, MySQL, PostgreSQL, Oracle, MS SQL Server, et HubSpot.
Pros and Cons
Pros:
- Intégration automatisée des données
- Surveillance en temps réel
- Réplication rapide
Cons:
- Options de personnalisation limitées
- Ne convient pas à tous les types de données
Apache Camel est un framework d'intégration open source conçu pour les développeurs et les architectes qui doivent mettre en œuvre des modèles d'intégration d'entreprise. Il facilite le routage et la médiation des messages entre les systèmes, ce qui le rend idéal pour des scénarios d'intégration complexes.
Pourquoi j'ai choisi Apache Camel : Il excelle dans l'utilisation de modèles d'intégration pour simplifier la connectivité entre différents systèmes. Camel prend en charge une large gamme de protocoles et de formats de données, assurant à votre équipe de pouvoir connecter facilement des systèmes disparates. Son langage spécifique au domaine (DSL) offre une manière flexible de définir les règles de routage et de médiation, ce qui est crucial pour le traitement des intégrations complexes. La capacité de l'outil à s'intégrer à divers points de terminaison offre une polyvalence inégalée dans la conception de solutions d'intégration.
Fonctionnalités phares & intégrations :
Fonctionnalités comprennent un ensemble riche de modèles d'intégration d'entreprise qui simplifient le processus d'intégration. Le langage spécifique au domaine de l'outil permet de définir facilement des règles de routage complexes. Apache Camel prend également en charge de nombreux formats de données et protocoles, garantissant la compatibilité avec plusieurs systèmes.
Intégrations comprennent AWS, Apache Kafka, ActiveMQ, RabbitMQ, Salesforce, Google Cloud, Azure, JMS, File et FTP.
Pros and Cons
Pros:
- Nombreux modèles d'intégration
- Large prise en charge des formats de données
- Intégration polyvalente des points de terminaison
Cons:
- La documentation peut être incomplète
- Consommateur de ressources pour les grandes installations
Apache Kafka est une plateforme de diffusion d'événements distribuée utilisée par les développeurs et les entreprises pour construire des pipelines de données en temps réel et des applications de streaming. Elle est conçue pour traiter de grands volumes de données rapidement et efficacement, ce qui la rend idéale pour les entreprises qui ont besoin de traitement de données en temps réel.
Pourquoi j'ai choisi Apache Kafka : Il est conçu pour le streaming de données en temps réel, prenant en charge un traitement à haut débit et à faible latence, ce qui est essentiel pour les applications modernes axées sur les données. L'architecture distribuée de Kafka garantit une haute disponibilité et une tolérance aux pannes, de sorte que vos données sont toujours accessibles. La scalabilité de la plateforme vous permet de gérer des besoins croissants en données sans compromettre les performances. Kafka offre également de fortes garanties de durabilité des données, assurant l'intégrité des données dans le temps.
Fonctionnalités et intégrations clés :
Fonctionnalités comprenant une architecture distribuée qui garantit une haute disponibilité, une réplication de données intégrée pour la tolérance aux pannes, et un système de messagerie robuste pour un traitement de données évolutif. Ces fonctionnalités le rendent particulièrement adapté à la gestion efficace de grands volumes de données. Le système de stockage basé sur les journaux (log) de Kafka garantit la durabilité et la fiabilité des données.
Intégrations : Confluent, AWS, Azure, Google Cloud, MongoDB, Cassandra, Elasticsearch, Splunk, Hadoop et MySQL.
Pros and Cons
Pros:
- Gère un haut débit de données
- Traitement à faible latence
- Forte durabilité des données
Cons:
- Surveillance intégrée limitée
- La configuration peut être complexe
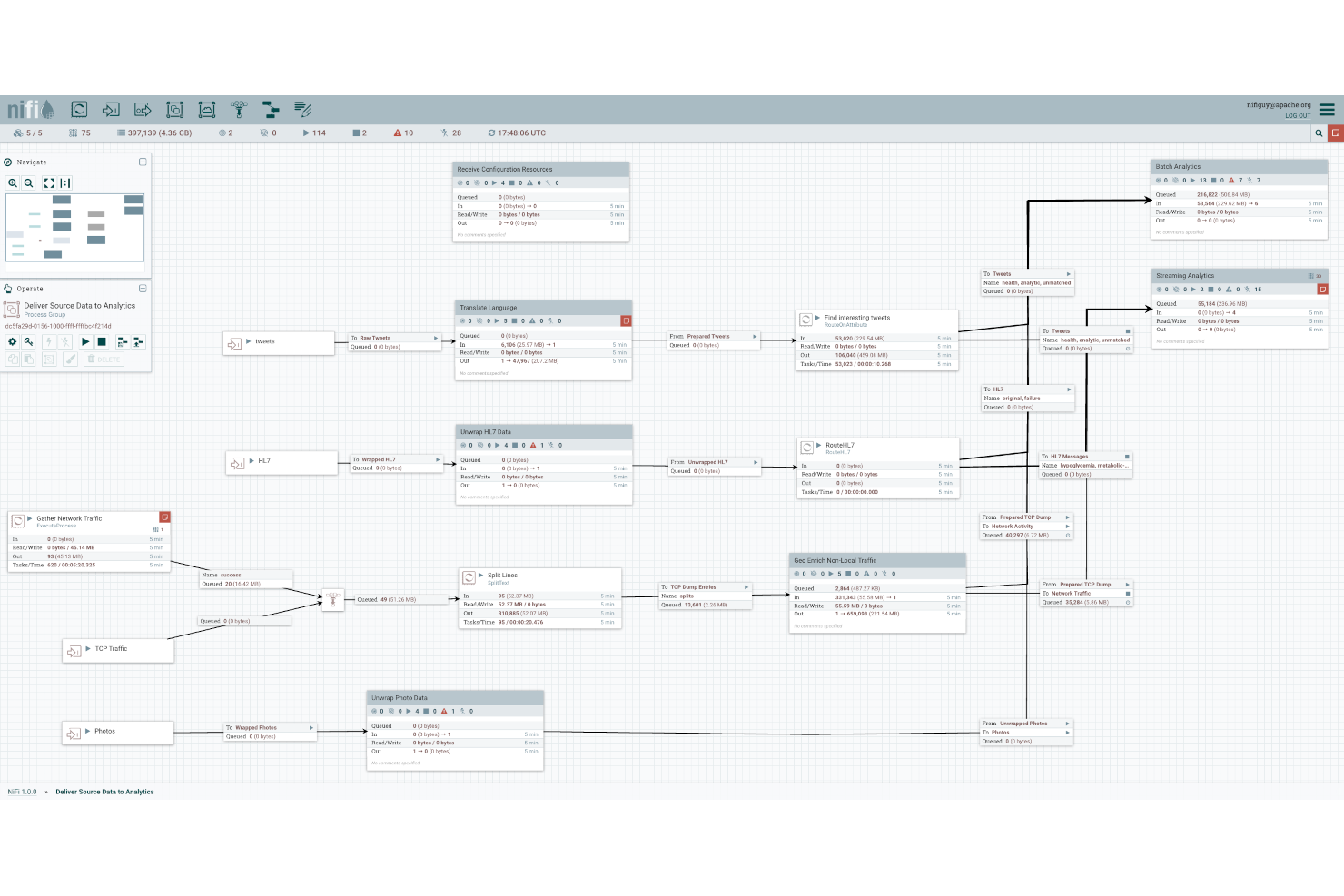
Apache NiFi est un outil d'intégration de données open-source conçu pour les développeurs et ingénieurs de données ayant besoin d'automatiser les flux de données. Il permet la collecte, le traitement et la distribution des données entre différents systèmes, ce qui le rend idéal pour la gestion de données en temps réel.
Pourquoi j'ai choisi Apache NiFi : Il est spécialement conçu pour l'automatisation des flux de données et propose une interface conviviale pour concevoir des workflows complexes. L'interface glisser-déposer de NiFi simplifie la création de pipelines de données, ce qui est essentiel pour les équipes qui ne disposent pas d'une vaste expérience en programmation. L'outil prend en charge la gestion des flux de données en temps réel, garantissant que vos données restent à jour et pertinentes. Ses fonctionnalités de sécurité intégrées offrent une couche de protection supplémentaire pour les données sensibles.
Fonctionnalités et intégrations remarquables :
Fonctionnalités comprennent une interface glisser-déposer qui simplifie la conception de workflows, permettant de créer facilement des pipelines de données. La gestion des flux de données en temps réel de NiFi garantit que vos informations sont toujours à jour. L'outil propose également des fonctionnalités de sécurité intégrées pour protéger vos informations sensibles.
Intégrations incluent AWS, Azure, Google Cloud, Kafka, HDFS, MongoDB, Elasticsearch, MySQL, PostgreSQL et JMS.
Pros and Cons
Pros:
- Automatise efficacement les flux de données
- Interface conviviale avec glisser-déposer
- Gestion des données en temps réel
Cons:
- Peut être gourmand en ressources
- Configuration initiale complexe
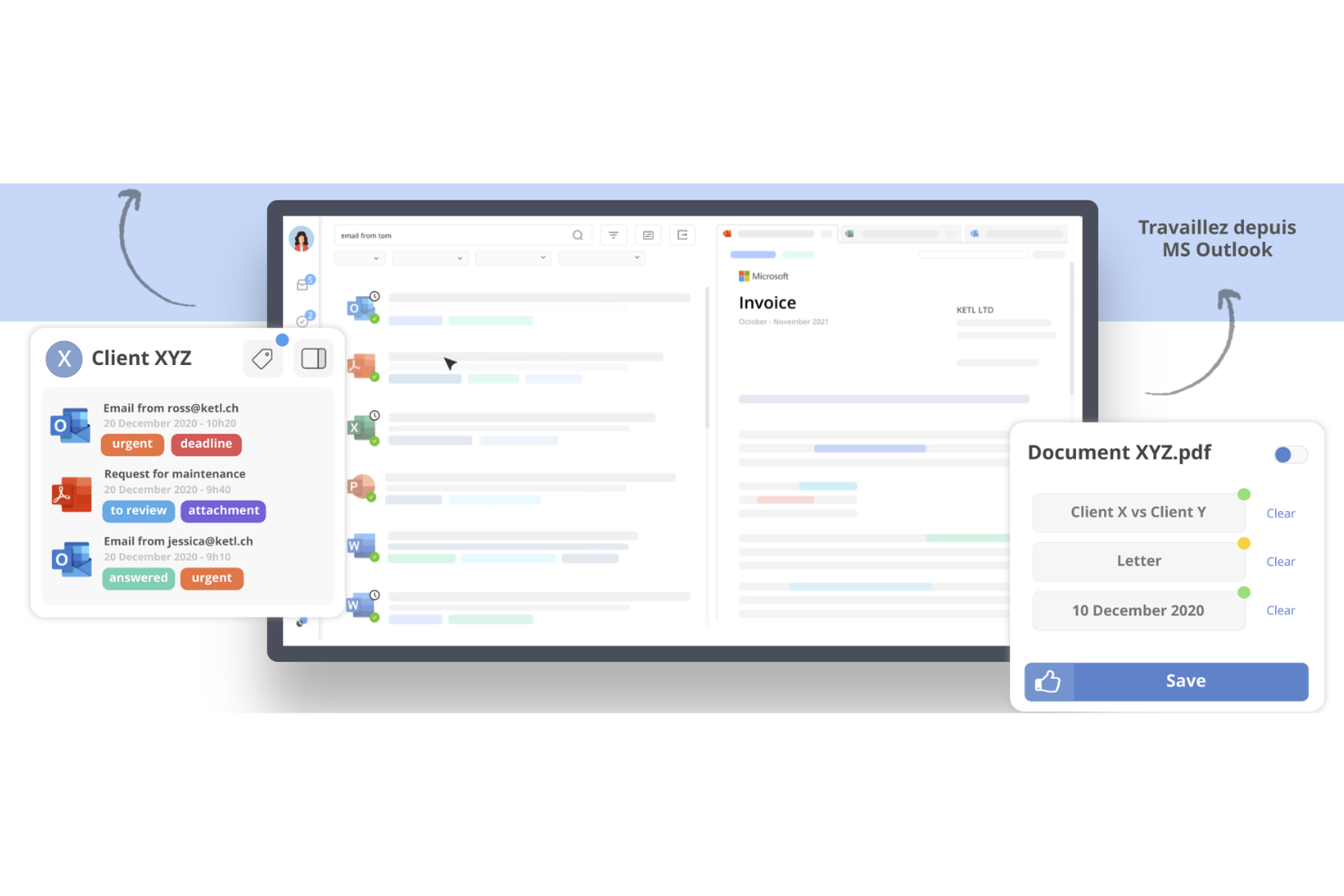
KETL est une plateforme ETL open-source conçue pour les ingénieurs de données et les professionnels de l'informatique qui ont besoin de solutions d'intégration et d'ordonnancement des données à grande échelle. Elle fournit une architecture multi-thread basée sur XML qui prend en charge des manipulations de données complexes, la rendant adaptée aux tâches de traitement de données volumineuses.
Pourquoi j'ai choisi KETL : Elle offre des solutions ETL évolutives grâce à sa capacité à gérer de grands volumes de données sur plusieurs serveurs et processeurs. Le gestionnaire d'exécution et d'ordonnancement des tâches de la plateforme garantit une gestion efficace des flux de travail, essentielle pour les opérations à grande échelle. Son référentiel centralisé pour les définitions des tâches aide à maintenir l'organisation et le contrôle des processus de données. De plus, les capacités de suivi des performances de KETL permettent à votre équipe de surveiller et optimiser efficacement les flux de données.
Fonctionnalités et intégrations remarquables :
Fonctionnalités : incluent une architecture multi-thread qui améliore la scalabilité et la performance. KETL prend en charge un large éventail de types de tâches, y compris SQL, OS et XML, offrant une flexibilité dans le traitement de différents formats de données. Le référentiel centralisé des définitions de tâches de la plateforme aide à rationaliser la gestion des flux de travail et à garantir la cohérence.
Intégrations : incluent Oracle, MySQL, PostgreSQL, Microsoft SQL Server, MongoDB, Amazon Redshift, Google BigQuery, Salesforce, SAP et Hadoop.
Pros and Cons
Pros:
- Scalable sur plusieurs serveurs
- Prise en charge de manipulations complexes de données
- Référentiel centralisé des tâches
Cons:
- Soutien communautaire limité
- Documentation parfois limitée
Autres outils ETL open source
Voici quelques autres options d’outils ETL open source qui n’ont pas été retenues dans ma sélection, mais qui méritent tout de même le détour :
- Singer
Idéal pour les scripts d'extraction de données
- Scriptella
Idéal pour le scripting ETL simple
- Bubbles
Cadriciel ETL Python pour le traitement, l'audit et l'inspection des données


{kind=link}
Critères de sélection des outils ETL open source
Pour sélectionner les meilleurs outils ETL open source à inclure dans cette liste, j'ai pris en compte les besoins courants des acheteurs et leurs difficultés, comme la complexité des outils d'intégration de données et leur scalabilité. J'ai aussi utilisé le cadre suivant pour garantir une évaluation structurée et équitable :
Fonctionnalité principale (25 % de la note finale)
Pour figurer dans cette liste, chaque solution devait répondre à ces cas d'usage communs :
- Extraction de données à partir de plusieurs sources
- Transformation et nettoyage des données
- Chargement des données vers des systèmes cibles
- Traitement des données en temps réel
- Traitement des données par lots
Fonctionnalités supplémentaires remarquables (25 % de la note finale)
Pour affiner encore la sélection, j'ai aussi recherché des fonctionnalités uniques, telles que :
- Prise en charge des workflows de données complexes
- Fonctionnalités de sécurité avancées pour les données
- Intégration avec les services cloud
- Connecteurs de données personnalisables
- Gestion automatisée des erreurs
Facilité d’utilisation (10 % du score total)
Pour évaluer la facilité d’utilisation de chaque système, j’ai pris en compte les aspects suivants :
- Interface utilisateur intuitive
- Navigation aisée
- Courbe d’apprentissage minimale
- Documentation claire
- Conception responsive
Intégration des utilisateurs (10 % du score total)
Pour évaluer l’expérience d’intégration sur chaque plateforme, j’ai pris en compte les critères suivants :
- Disponibilité de vidéos de formation
- Tours produits interactifs
- Accès à des modèles
- Webinaires en direct pour l’accompagnement
- Chatbots d’assistance
Support client (10 % du score total)
Pour évaluer le service d’assistance de chaque éditeur de logiciel, j’ai pris en compte les éléments suivants :
- Disponibilité 24/7
- Multiples canaux de support
- Centre d’aide réactif
- FAQs complètes
- Accès aux forums communautaires
Rapport qualité/prix (10 % du score total)
Pour évaluer le rapport qualité/prix de chaque plateforme, j’ai pris en compte les critères suivants :
- Niveaux de tarification compétitifs
- Disponibilité d’une période d’essai gratuite
- Coût par rapport aux fonctionnalités
- Scalabilité des forfaits tarifaires
- Réductions pour un engagement à long terme
Avis clients (10 % du score total)
Pour obtenir une idée de la satisfaction globale des clients, j’ai tenu compte des éléments suivants lors de la lecture des avis :
- Avis positifs des utilisateurs
- Problèmes fréquemment signalés
- Cohérence des performances des fonctionnalités
- Notes de satisfaction globale
- Tendances des réclamations des utilisateurs
Comment choisir des outils ETL open source
Il est facile de se perdre dans de longues listes de fonctionnalités et des structures tarifaires complexes. Pour vous aider à rester concentré(e) lors de votre propre processus de sélection de logiciel, voici une checklist des critères à garder à l’esprit :
| Critère | À considérer |
| Scalabilité | S’assurer que l’outil peut gérer la croissance du volume de vos données. Pensez aux besoins futurs et vérifiez si l’outil prend efficacement en charge à la fois les traitements par lot et en temps réel. |
| Intégrations | Vérifiez si l’outil s’intègre à vos systèmes et sources de données existants comme les bases de données, services cloud et applications tierces pour fluidifier vos workflows. |
| Personnalisation | Vérifiez la possibilité d’adapter les workflows de données à vos processus spécifiques. Plus c’est personnalisable, mieux l’outil s’adapte à vos besoins évolutifs. |
| Facilité d’utilisation | Évaluez l’ergonomie de l’interface. Un outil facile à utiliser réduira la courbe d’apprentissage pour vos équipes et accélérera la mise en œuvre. |
| Budget | Comparez les prix à votre budget. Prenez en compte le coût total de possession, y compris les coûts cachés, pour garantir une bonne adéquation avec vos contraintes financières. |
| Protection des données | Assurez-vous que l’outil offre des fonctionnalités de sécurité solides pour protéger vos données sensibles. Recherchez le chiffrement, le contrôle d’accès utilisateur et la conformité réglementaire. |
| Support | Vérifiez la disponibilité du service client. Une assistance réactive peut s’avérer cruciale lors de l’implémentation et du dépannage. |
| Performance | Évaluez la rapidité de traitement et la fiabilité de l’outil. Il doit livrer vos données à temps et sans erreur pour soutenir les activités de votre entreprise. |
Tendances des outils ETL open source
Lors de mes recherches, j’ai passé en revue de nombreuses mises à jour de produits, communiqués de presse et journaux de publication de différents éditeurs d’outils ETL open source. Voici quelques tendances émergentes que je surveille actuellement :
- Traitement en temps réel : De plus en plus d’outils se concentrent sur le traitement des données en temps réel, permettant aux entreprises de réagir rapidement aux changements et de prendre des décisions éclairées. Par exemple, Apache Kafka a renforcé ses capacités de streaming pour prendre en charge l’analyse en temps réel.
- Observabilité des données : Les fournisseurs ajoutent des fonctionnalités pour améliorer la visibilité et la surveillance des données, aidant les équipes à identifier et résoudre les problèmes plus rapidement. Des outils comme Apache NiFi offrent désormais des fonctionnalités avancées de suivi et de traçabilité des données afin de garantir l’intégrité des données.
- Architecture cloud-native : Avec la transition vers l’informatique en nuage, les outils ETL sont conçus pour exploiter efficacement les ressources cloud. Talend Open Studio, par exemple, propose des capacités cloud-native pour optimiser les performances et l’évolutivité.
- Interfaces low-code : La demande croissante pour des plateformes low-code ou no-code rend les outils ETL accessibles aux utilisateurs non techniques. Des solutions comme Pentaho Kettle adoptent des interfaces visuelles afin de simplifier la création de pipelines de données.
- Gouvernance des données : Alors que les réglementations sur la confidentialité des données se renforcent, les outils ETL intègrent davantage de fonctionnalités de gouvernance. Cela inclut des options de masquage et de chiffrement des données, qui deviennent la norme dans des solutions comme Hevo Data pour garantir la conformité et la sécurité des données.
Que sont les outils ETL open source ?
Les outils ETL open source facilitent l’extraction, la transformation et le chargement des données depuis diverses sources vers un emplacement centralisé. Les ingénieurs data, analystes et professionnels IT utilisent généralement ces outils pour gérer et traiter efficacement de grands volumes de données.
Le traitement en temps réel, l’observabilité des données et les capacités cloud-native favorisent la prise de décisions rapide, la résolution des problèmes et l’utilisation efficace des ressources. De manière générale, ces outils offrent la flexibilité et l’évolutivité nécessaires pour gérer des workflows de données complexes et soutenir des stratégies axées sur les données. Pour garantir la fiabilité à grande échelle, les équipes devraient compléter leurs outils ETL avec des outils d’automatisation des tests ETL performants.
Fonctionnalités des outils ETL open source
Lors du choix d’un outil ETL open source, portez attention aux fonctionnalités clés suivantes :
- Traitement en temps réel : Traite les données dès leur arrivée, vous aidant à prendre des décisions opportunes et à réagir rapidement aux changements.
- Observabilité des données : Offre une visibilité sur les flux de données, permettant une surveillance efficace et une résolution rapide des problèmes.
- Architecture cloud-native : Exploite efficacement les ressources cloud pour améliorer l’évolutivité et les performances.
- Interfaces low-code : Simplifie la création des pipelines de données, rendant les outils accessibles même aux débutants.
- Gouvernance des données : Garantit la conformité et la sécurité grâce à des fonctions telles que le masquage et le chiffrement des données.
- Intégration multi-sources : Se connecte à diverses sources pour centraliser et rationaliser le traitement des données.
- Scalabilité : Gère la croissance des volumes de données et prend en charge à la fois les traitements par lots et en temps réel.
- Personnalisation : Permet d’adapter les workflows de données aux besoins spécifiques de l’entreprise.
- Suivi des performances : Surveille et optimise les workflows de données afin de maintenir leur efficacité et leur précision.
- Gestionnaire de planification : Automatise l’exécution des tâches et gère les workflows pour améliorer la productivité.
Avantages des outils ETL open source
L’adoption d’outils ETL open source offre de nombreux avantages à votre équipe et à votre organisation. Voici quelques points forts :
- Rentabilité : Puisqu’ils sont open source, ces outils ne nécessitent souvent aucun frais de licence, ce qui réduit les coûts globaux pour votre entreprise.
- Flexibilité : Des workflows personnalisables permettent d’adapter les processus de données à vos besoins spécifiques et de faire évoluer ces processus au fil du temps.
- Scalabilité : Prend en charge à la fois le traitement par lots et le temps réel, permettant à votre structure de faire face à la croissance des volumes de données sans perte de performance.
- Aide à la prise de décision : Le traitement en temps réel assure à vos équipes un accès à des informations actualisées pour des décisions rapides et éclairées.
- Qualité des données améliorée : Des fonctionnalités comme l’observabilité et la gouvernance maintiennent la précision et la conformité des données, renforçant la confiance dans vos informations.
- Soutien communautaire : Une large communauté de développeurs soutient souvent ces outils, offrant ressources et expertise pour le dépannage et l’amélioration continue.
- Capacités d’intégration : Se connecte facilement à différents systèmes et sources de données afin de faciliter la gestion des données à l’échelle de l’entreprise.
Coûts et tarification des outils ETL open source
Sélectionner des outils ETL open source nécessite de comprendre les différents modèles et plans tarifaires disponibles. Les coûts varient selon les fonctionnalités, la taille de l'équipe, les modules complémentaires et plus encore. Le tableau ci-dessous résume les plans courants, leurs prix moyens et les fonctionnalités typiques incluses dans les solutions d'outils ETL open source :
Tableau comparatif des plans pour les outils ETL open source
| Type de plan | Prix moyen | Fonctionnalités courantes |
| Plan gratuit | $0 | Extraction de données de base (extraction de données), intégrations limitées et support communautaire. |
| Plan personnel | $5-$25/utilisateur/mois | Transformations de données avancées, support personnalisé et personnalisation limitée. |
| Plan Business | $50-$100/utilisateur/mois | Traitement avancé des données, multiples intégrations et outils de collaboration en équipe. |
| Plan Entreprise | $100-$500/utilisateur/mois | Personnalisation complète, support de niveau entreprise et fonctionnalités de sécurité complètes. |
Outils ETL open source (FAQs)
Voici des réponses à des questions fréquentes sur les outils ETL open source :
Quelles sont les limites des outils ETL ?
Les outils ETL n’assurent souvent pas le stockage permanent des données, ce qui implique la nécessité de solutions de stockage supplémentaires. Ils peuvent également introduire une latence de données, entraînant des retards de disponibilité. Leur prise en main peut être complexe et le passage à l’échelle pour traiter de grands volumes de données peut demander des ressources supplémentaires. De plus, ils peuvent rencontrer des difficultés avec les données non structurées.
Quel est le meilleur outil ETL open source ?
Le meilleur outil ETL open source dépend de vos besoins spécifiques. Des outils comme Apache NiFi sont idéaux pour les flux de données en temps réel, tandis que Talend Open Studio est excellent pour l’intégration de données à grande échelle. Tenez compte de l’expertise de votre équipe, de la complexité des données et des besoins d’intégration au moment du choix.
Que peuvent charger et convertir les outils ETL avancés en données structurées et non structurées ?
Les outils ETL avancés peuvent charger et convertir aussi bien les données structurées que non structurées dans des formats compatibles avec des systèmes comme Hadoop. Ils gèrent de multiples fichiers en parallèle, simplifiant ainsi la fusion de données diverses dans un flux de transformation unifié.
Quelle est la différence entre une API et un outil ETL ?
Les API sont idéales pour l’échange de données en temps réel et la communication entre applications. À l’inverse, les outils ETL sont mieux adaptés aux traitements batch, où des données issues de multiples sources doivent être consolidées, transformées et chargées dans une cible d’analyse.
Comment les outils ETL gèrent-ils la sécurité des données ?
Les outils ETL garantissent la sécurité des données grâce au chiffrement, à des contrôles d’accès et à des mesures de conformité. Ils veillent à la protection des données sensibles lors des processus d’extraction, de transformation et de chargement. Certains proposent également des fonctions d’audit intégrées pour contrôler l’accès et les modifications apportées aux données.
Les outils ETL peuvent-ils s'intégrer aux services cloud ?
Oui, de nombreux outils ETL s’intègrent parfaitement aux services cloud. Ils permettent le transfert de données vers et depuis des plateformes comme AWS, Google Cloud et Azure, vous permettant ainsi de tirer parti du stockage et du traitement dans le cloud pour vos workflows de données.
Et ensuite ?
Développez la croissance de votre SaaS et vos compétences en leadership technologique. Abonnez-vous à notre newsletter pour découvrir les dernières analyses des CTOs et futurs leaders tech.
Nous vous aidons à évoluer intelligemment et à diriger avec force grâce à des guides, des ressources et des stratégies d'experts reconnus !