14 Meilleures Alternatives à Netdata pour 2026

Liste des alternatives à Netdata


Une bonne alternative à Netdata doit offrir une supervision applicative en temps réel, des intégrations flexibles ainsi qu’une visualisation claire pour les environnements complexes. Si vous cherchez une alternative à Netdata, il vous faut probablement un système de surveillance évolutif, compatible avec les pratiques d’observabilité moderne et capable d’accompagner la croissance de votre infrastructure. De nombreuses équipes recherchent des plateformes tout-en-un qui proposent une surveillance complète, des fonctionnalités avancées et des intégrations sans effort, tout en restant économiques et faciles à déployer. Cette liste compare les meilleures options pour 2026 pour vous aider à évaluer les fonctionnalités, la facilité d’utilisation et la capacité de supervision, afin de choisir une solution intuitive adaptée à vos besoins d’infrastructure et d’exploitation.
Qu’est-ce que Netdata ?
Netdata est un outil open-source de surveillance applicative qui fournit des analyses en temps réel sur les performances du système, l’utilisation des ressources et la santé des applications. Il collecte des métriques provenant des serveurs, des conteneurs et des applications, qu’il affiche via des tableaux de bord interactifs. Netdata est utilisé par les spécialistes IT et les équipes d’exploitation pour détecter les anomalies, dépanner les incidents et maintenir l’infrastructure fiable. Son architecture légère et ses nombreuses intégrations le rendent adapté à la supervision des environnements modernes comme anciens.
Résumé des meilleures alternatives à Netdata
Ce tableau comparatif résume les détails tarifaires de mes principales alternatives à Netdata pour vous aider à trouver celle qui répond le mieux à votre budget et à vos besoins professionnels.
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | Idéal pour la visibilité sur les infrastructures multi-cloud | Essai gratuit de 14 jours + offre gratuite disponible | À partir de $15/hôte/mois | Website | |
| 2 | Idéal pour la corrélation frontend et backend | Essai gratuit de 14 jours + démonstration gratuite disponible | À partir de $49/hôte/mois (facturé annuellement) | Website | |
| 3 | Idéal pour la supervision des transactions à l’échelle de l’entreprise | Essai gratuit disponible | Prix sur demande | Website | |
| 4 | Idéal pour le traçage distribué en temps réel | Offre gratuite + démo gratuite disponibles | Tarification sur demande | Website | |
| 5 | Idéal pour la collecte de métriques temporelles | Offre gratuite disponible à vie | Utilisation gratuite | Website | |
| 6 | Idéal avec des intégrations de données open source | Essai gratuit de 7 jours + formule gratuite disponible | À partir de $99/mois | Website | |
| 7 | Idéal pour des visualisations de tableaux de bord avancées | Offre gratuite disponible | À partir de $19/mois | Website | |
| 8 | Idéal pour la surveillance native des ressources AWS | Essai gratuit disponible | Tarification sur demande | Website | |
| 9 | Idéal pour la prise en charge des environnements hybrides | Essai gratuit de 30 jours disponible | À partir de $7/nœud/mois | Website | |
| 10 | Idéal pour le suivi des erreurs lors des déploiements de code | Plan gratuit + démo gratuite disponible | À partir de $26/mois (facturé annuellement) | Website |
Pourquoi faire confiance à nos avis logiciels
Nous testons et analysons des logiciels depuis 2023. En tant que dirigeants technologiques, nous savons à quel point il est crucial et difficile de faire le bon choix lors de la sélection d’un logiciel.
Nous investissons dans des recherches approfondies pour aider notre audience à prendre de meilleures décisions d’achat de logiciels. Nous avons testé plus de 2 000 outils pour différents usages technologiques et rédigé plus de 1 000 avis complets. Découvrez comment nous restons transparents & notre méthodologie d’évaluation des logiciels.
-

TestDevLab
Visit Website -
Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8


Avis sur les alternatives à Netdata
Voici mes résumés détaillés des meilleures alternatives à Netdata ayant intégré ma liste restreinte. Mes avis proposent un aperçu approfondi des fonctionnalités, intégrations et cas d’usages idéaux pour chaque plateforme de supervision afin de vous aider à trouver celle qui vous convient le mieux.
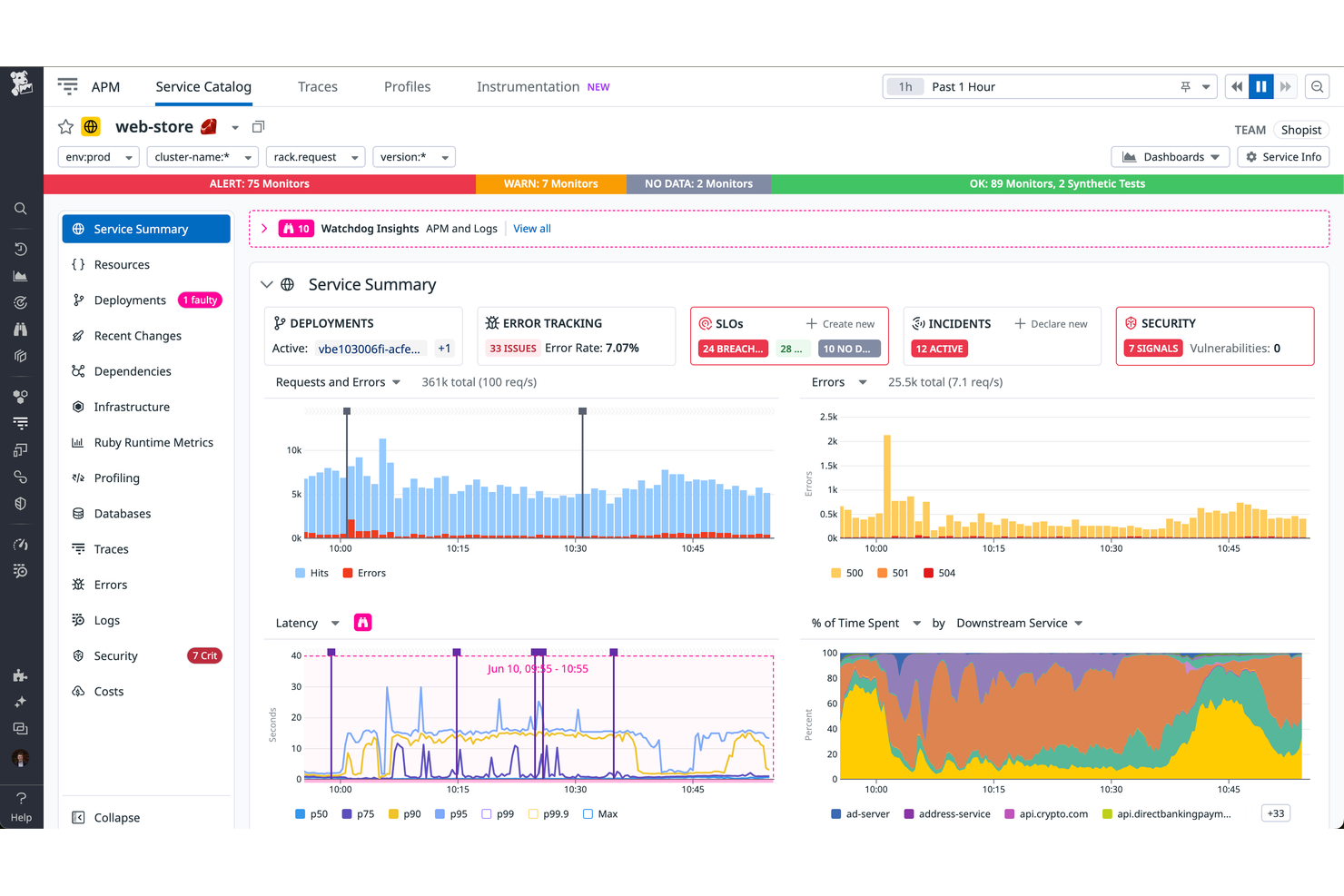
Datadog aide les équipes à surveiller les performances de l'infrastructure et les métriques système en temps réel sur l'ensemble de l'infrastructure, des applications, des services et des équipements réseau comme les routeurs. Datadog se distingue de Netdata par ses intégrations avancées, ses tableaux de bord personnalisables et sa prise en charge de la surveillance des changements de configuration (gestion de configuration) ainsi que des systèmes distribués à grande échelle.
Pourquoi Datadog est une bonne alternative à Netdata
Lorsque je recherche un outil de surveillance qui excelle en matière de visibilité sur les infrastructures multi-cloud, Datadog se démarque. Son tableau de bord unifié permet de surveiller les ressources sur AWS, Azure, Google Cloud et les systèmes sur site depuis un seul et même endroit. Les fonctionnalités d'auto-découverte et d'étiquetage de la plateforme facilitent le suivi des actifs à mesure que votre environnement évolue. Pour les équipes qui gèrent des infrastructures hybrides ou distribuées, Datadog offre un niveau de visibilité et de contrôle qui va au-delà de ce que propose Netdata.
Fonctionnalités clés de Datadog
D'autres fonctionnalités de Datadog en font un choix flexible pour la surveillance des applications :
- Gestion des logs en temps réel : Collectez, recherchez et analysez les logs provenant de plusieurs sources pour identifier rapidement les problèmes et les tendances.
- APM (Application Performance Monitoring) : Suivez les requêtes à travers des systèmes distribués et identifiez les goulots d'étranglement dans le code applicatif.
- Supervision synthétique : Simulez les interactions des utilisateurs et surveillez les points de terminaison des applications pour garantir la disponibilité et la performance.
- Surveillance de la sécurité : Détectez les menaces et les mauvaises configurations en temps réel en corrélant les signaux de sécurité avec les données d'infrastructure et d'application.
Intégrations Datadog
Les intégrations incluent AWS, Azure, Google Cloud, Kubernetes, Docker, Slack, PagerDuty, GitHub, Jira, ServiceNow, et bien d'autres.
Pros and Cons
Pros:
- Propose des tableaux de bord personnalisables en temps réel
- Inclut des fonctionnalités de sécurité intégrées
- S'intègre aux principaux outils DevOps et IT
Cons:
- La rétention des logs est limitée sur les offres inférieures
- Nécessite l'installation d'un agent sur chaque hôte surveillé
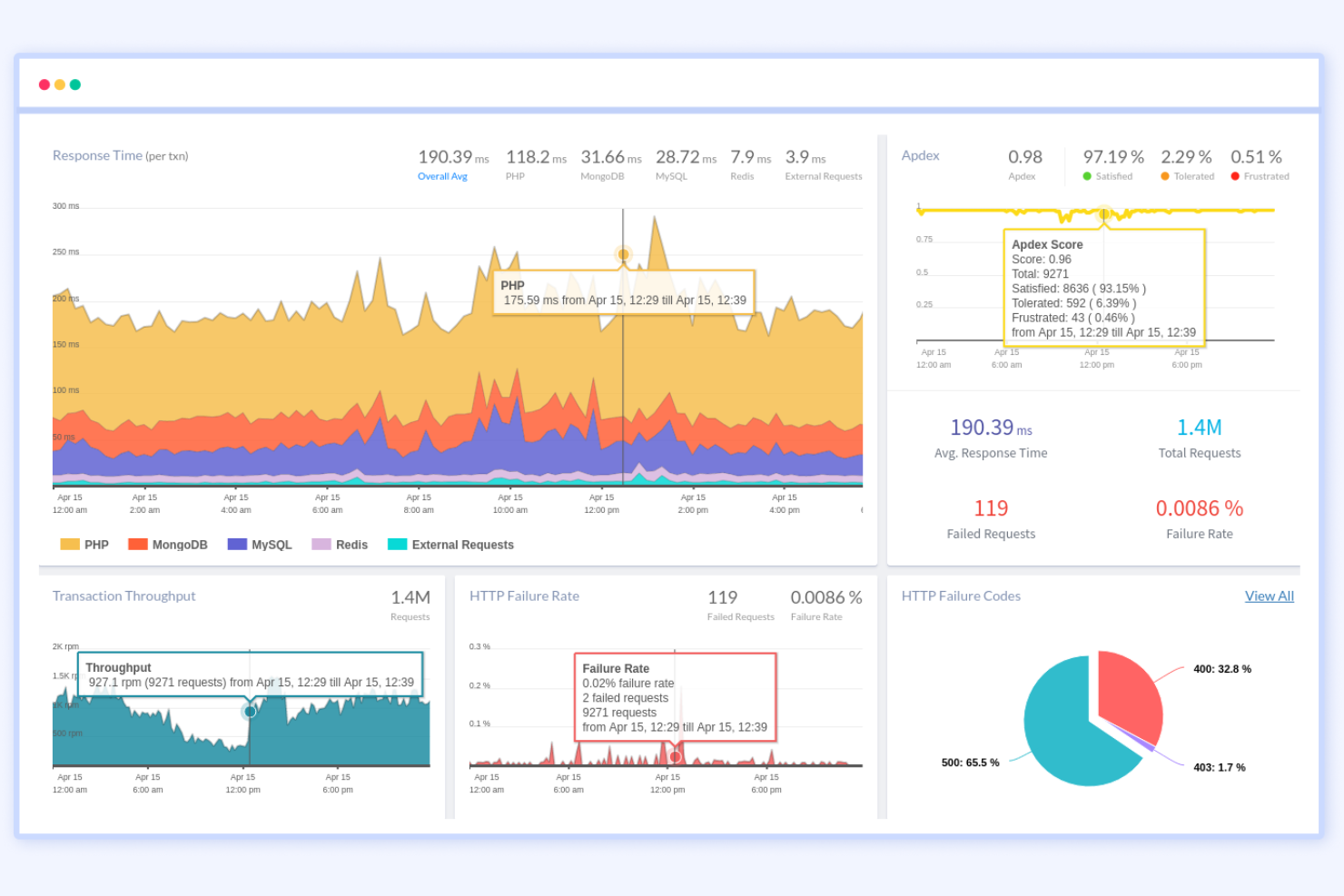
Si vous devez diagnostiquer des problèmes tant du côté frontend que backend, Atatus est conçu pour offrir ce niveau de visibilité. Cet outil s’adresse aux équipes informatiques et aux développeurs qui souhaitent corréler les problèmes d’expérience utilisateur avec les données de performance du backend en temps réel. Contrairement à Netdata, Atatus connecte la surveillance du navigateur, de l’API et du serveur afin que vous puissiez identifier précisément où commencent les problèmes et comment ils affectent les utilisateurs.
Pourquoi Atatus est une bonne alternative à Netdata
Contrairement à Netdata, Atatus propose une vue unifiée des performances frontend et backend, facilitant ainsi le suivi des incidents sur l’ensemble de la pile. Vous pouvez surveiller les erreurs du navigateur, les appels API et les métriques serveur dans un seul et même endroit, ce qui aide les équipes à relier rapidement les problèmes d’expérience utilisateur aux causes backend. J’apprécie la façon dont Atatus visualise tout le chemin de la transaction, afin que vous puissiez voir exactement où se produisent les goulets d’étranglement ou les défaillances. Ce niveau de corrélation est particulièrement utile aux équipes informatiques et aux développeurs ayant besoin de résoudre des incidents complexes et interdépendants.
Fonctionnalités clés d’Atatus
D’autres fonctionnalités d’Atatus aident les équipes à couvrir une grande variété de besoins en surveillance et dépannage :
- Real User Monitoring (RUM) : Suivi des véritables sessions utilisateurs et des métriques de performance issues des navigateurs.
- Gestion des logs : Collecte, recherche et analyse des logs provenant de sources multiples depuis un tableau de bord unifié.
- Tableaux de bord personnalisés : Permet de créer des vues personnalisées avec des widgets pour les métriques les plus pertinentes pour votre équipe.
- Alertes et notifications : Envoie des alertes via des canaux comme Slack, PagerDuty et e-mail lorsque des seuils sont dépassés.
Intégrations Atatus
Les intégrations incluent Slack, Jira, Asana, PagerDuty, OpsGenie, VictorOps, BigPanda, Flowdock, HipChat, Campfire, et plus encore.
Pros and Cons
Pros:
- Gestion et recherche des logs intégrées
- Prend en charge l'envoi d'alertes vers plusieurs outils de gestion d'incident
- Tableaux de bord personnalisés pour les métriques propres à l'équipe
Cons:
- Pas d'option de déploiement sur site
- Absence de plugins communautaires open source
Idéal pour la supervision des transactions à l’échelle de l’entreprise
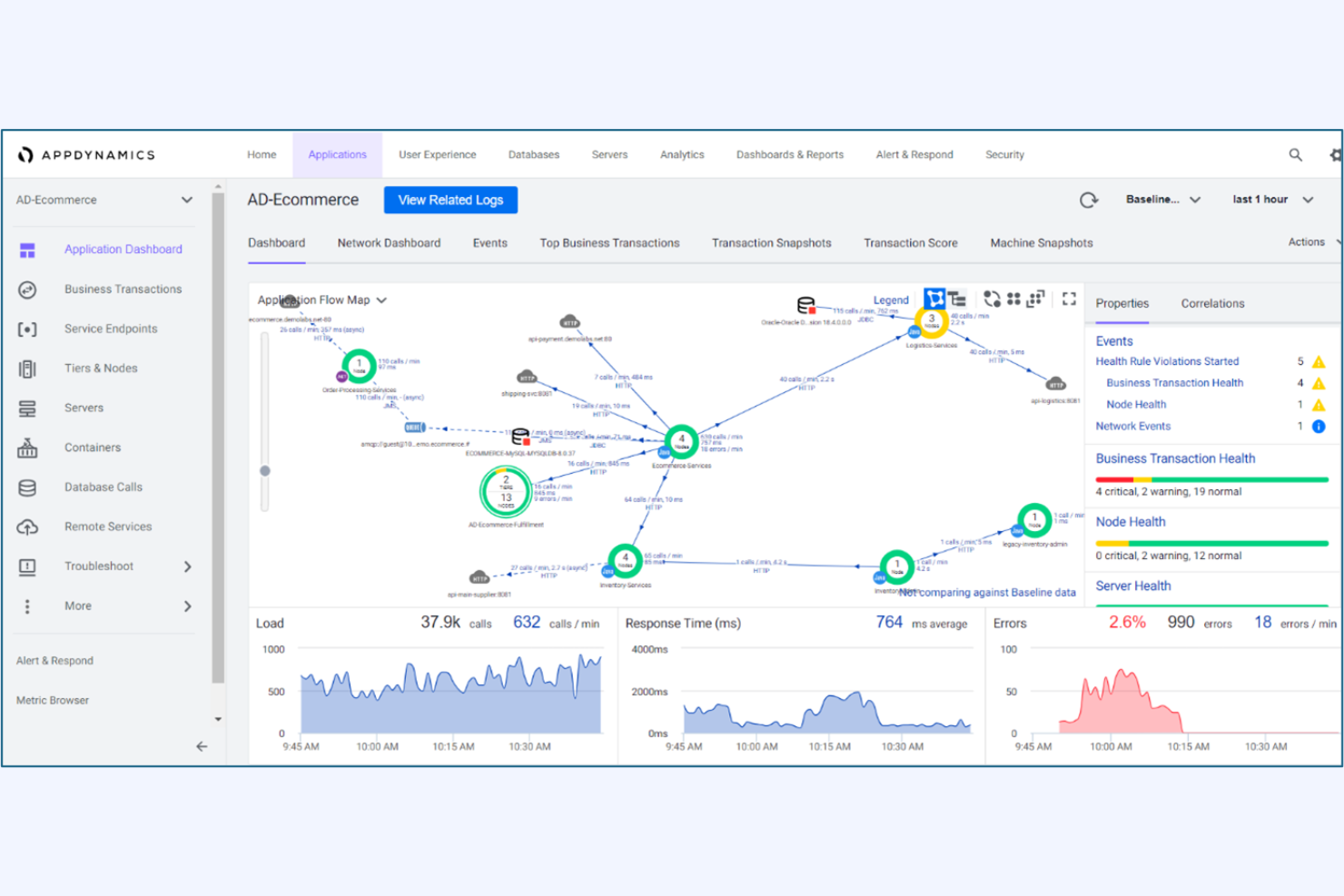
Pour les organisations qui ont besoin d’une visibilité approfondie sur les transactions critiques pour l’entreprise, AppDynamics offre une surveillance et une analyse à l’échelle de l’entreprise. C’est une solution idéale pour les équipes informatiques des grandes entreprises qui doivent tracer des transactions complexes et distribuées à travers plusieurs services. Contrairement à Netdata, AppDynamics fournit une traçabilité de bout en bout des transactions ainsi qu’une analyse de l’impact métier, afin d’aider les équipes à identifier et résoudre rapidement les goulets d’étranglement des performances.
Pourquoi AppDynamics est une bonne alternative à Netdata
AppDynamics est conçu spécifiquement pour surveiller les transactions complexes, à grande échelle, qui couvrent plusieurs applications et services. Sa fonctionnalité de traçage vous permet de suivre chaque étape d’un processus métier, de l’interaction utilisateur jusqu’aux systèmes backend, ce que Netdata ne propose pas avec autant de profondeur. J’apprécie la façon dont AppDynamics fait le lien entre la performance applicative et les indicateurs métier, permettant ainsi aux équipes informatiques de prioriser les problèmes qui ont un impact sur le chiffre d’affaires ou l’expérience client. Cela en fait un choix pertinent pour les organisations qui doivent relier la supervision technique aux résultats métiers.
Fonctionnalités clés d’AppDynamics
D’autres fonctionnalités d’AppDynamics aident les équipes à gérer et optimiser leurs environnements :
- Alertes avec seuils dynamiques : Établit automatiquement des bases de référence pour les performances et déclenche des alertes lorsque les métriques s’écartent des schémas normaux.
- Diagnostics au niveau du code : Offre une visibilité détaillée sur l’exécution du code pour identifier les méthodes lentes et les appels de base de données problématiques.
- Tableaux de bord personnalisés : Permet aux utilisateurs de créer des visualisations sur mesure pour des équipes, applications ou entités métier spécifiques.
- Supervision cloud-native : Prend en charge la supervision de Kubernetes, AWS, Azure et d’autres plateformes cloud.
Intégrations AppDynamics
Les intégrations incluent Splunk Platform, Splunk Observability Cloud, Splunk IT Service Intelligence, ThousandEyes, SAP Solutions, Log Observer Connect, et plus encore.
Pros and Cons
Pros:
- Corrélation de l’impact métier lors des incidents
- Diagnostics au niveau du code pour les problèmes applicatifs
- Établissement dynamique des seuils pour la détection d’anomalies
Cons:
- Support limité pour les exportateurs open source
- La rétention des métriques personnalisées est limitée selon le plan
Si vous avez besoin d'une visibilité approfondie et en temps réel sur des applications distribuées, New Relic est conçu pour relever ce défi. C’est une solution idéale pour les équipes informatiques et les ingénieurs fiabilité des sites qui souhaitent tracer les requêtes à travers des microservices et des environnements cloud natifs. Contrairement à Netdata, New Relic se spécialise dans le traçage distribué de bout en bout et l’analyse granulaire des transactions dans des architectures complexes et modernes.
Pourquoi New Relic est une bonne alternative à Netdata
Pour les équipes qui doivent suivre chaque requête en temps réel à travers des systèmes distribués, New Relic offre un niveau de traçabilité que Netdata n’atteint pas. Sa fonction de traçage distribué vous permet de visualiser et d'analyser les transactions alors qu'elles circulent à travers les microservices, les API et les fonctions serverless. J’apprécie le fait que les données de traçage de New Relic soient liées directement aux journaux et aux métriques, ce qui facilite l’identification de la cause profonde des problèmes de performance. Cette focalisation sur la visibilité en temps réel et de bout en bout est particulièrement précieuse dans les environnements modernes et cloud natifs.
Fonctionnalités principales de New Relic
D’autres fonctionnalités dans New Relic complètent ses capacités de supervision :
- Surveillance de l’infrastructure : Suivez la santé et les performances des serveurs, des conteneurs et des ressources cloud en temps réel.
- Surveillance synthétique : Lancez des tests utilisateurs automatisés et simulés pour contrôler la disponibilité de l’application et la réactivité des points de terminaison.
- Tableaux de bord personnalisés : Créez et partagez des visualisations à partir d’un large éventail de métriques et de sources de données.
- Alertes et gestion des incidents : Mettez en place des politiques d’alerte flexibles et intégrez-vous à des outils de gestion des incidents pour traiter les problèmes dès leur apparition.
Intégrations New Relic
Les intégrations incluent AWS, Azure, Google Cloud, Kubernetes, Docker, Jenkins, PagerDuty, Slack, ServiceNow, Prometheus, et bien plus.
Pros and Cons
Pros:
- Traçage distribué en temps réel à travers les microservices
- Analyse granulaire des transactions pour les apps cloud natives
- Surveillance synthétique automatisée des points de terminaison API
Cons:
- Limites de rétention des données sur les offres basiques
- Un grand nombre de métriques peut augmenter les coûts
Prometheus est conçu spécifiquement pour les équipes qui doivent collecter et interroger des métriques de séries temporelles à grande échelle. Il est particulièrement apprécié des spécialistes IT et des ingénieurs SRE qui recherchent une solution open-source flexible pour superviser l'infrastructure et les applications. Contrairement à Netdata, Prometheus offre un langage de requête puissant ainsi qu'une prise en charge native des données multidimensionnelles, ce qui en fait un excellent choix pour les environnements aux exigences complexes en matière de métriques.
Pourquoi Prometheus est une bonne alternative à Netdata
Pour les équipes axées sur la collecte et l'analyse de métriques temporelles, Prometheus propose une approche spécialisée qui le distingue de Netdata. J'ai choisi Prometheus car il utilise un modèle d'extraction (pull) pour la collecte des métriques, ce qui permet un contrôle précis sur les données collectées et le moment de la collecte. Son langage de requête PromQL offre des possibilités avancées de découpage, d'agrégation et de visualisation des métriques. Cela rend Prometheus particulièrement utile aux spécialistes IT qui doivent surveiller des environnements complexes et dynamiques, et souhaitent créer des tableaux de bord ou des règles d'alerte personnalisés.
Fonctionnalités clés de Prometheus
D'autres fonctionnalités de Prometheus aident les équipes à gérer et à étendre leur dispositif de surveillance :
- Intégration avec Alertmanager : Dirige les alertes selon des règles personnalisées et permet la mise en sourdine ou l'inhibition.
- Découverte de services : Détecte automatiquement les cibles dans des environnements dynamiques comme Kubernetes ou les plateformes cloud.
- Configuration de la rétention des données : Permet de contrôler la durée de stockage local des métriques.
- Écosystème d'exportateurs : Propose un large éventail d'exportateurs pour collecter des métriques de systèmes et de services tiers.
Intégrations Prometheus
Les intégrations incluent Kubernetes, Docker, Grafana, Alertmanager, Etcd, Consul, RabbitMQ, MySQL, Apache, HAProxy, et bien d'autres.
Pros and Cons
Pros:
- PromQL permet des requêtes avancées sur les métriques
- Modèle à extraction adapté aux environnements dynamiques
- Grand écosystème d'exportateurs pour systèmes tiers
Cons:
- Pas de visualisation en temps réel à la seconde près
- Nécessite des outils externes pour l'affichage des tableaux de bord
Idéal avec des intégrations de données open source
Pour les équipes souhaitant unifier la surveillance des applications avec des sources de données open source, Elastic Observability propose une approche flexible. Cet outil convient particulièrement aux spécialistes IT et aux équipes DevOps qui ont besoin d’ingérer, d’analyser et de corréler des données provenant d’une grande variété de sources open source et personnalisées. Contrairement à Netdata, Elastic Observability s’intègre en profondeur à Elastic Stack, facilitant la combinaison des journaux, métriques et traces issus d’environnements divers.
Pourquoi Elastic Observability est une bonne alternative à Netdata
Si vous souhaitez rassembler des données issues d’outils open source et de sources personnalisées, Elastic Observability se distingue par sa flexibilité. J’ai choisi Elastic Observability car il permet d’ingérer et de corréler journaux, métriques et traces provenant de quasiment n’importe quelle source via Elastic Stack. Vous pouvez utiliser des agents open source et des intégrations pour surveiller aussi bien des applications cloud natives que des systèmes hérités. Cette approche est particulièrement utile aux équipes IT qui veulent construire une plateforme d’observabilité unifiée et adaptée à leur environnement.
Fonctionnalités clés d’Elastic Observability
D’autres fonctionnalités d’Elastic Observability aident les équipes à gérer et analyser la performance applicative à grande échelle :
- Traçabilité distribuée : Visualise les flux de requêtes de bout en bout à travers microservices et infrastructures.
- Cartographie des services : Génère automatiquement des cartes interactives des dépendances et de l’état de santé des services.
- Détection d’anomalies : Utilise l’apprentissage automatique pour identifier des schémas inhabituels dans la performance applicative.
- Tableaux de bord personnalisés : Permet de créer et partager des tableaux de bord adaptés aux besoins de surveillance de votre équipe.
Intégrations APM Elastic Observability
Les intégrations incluent Amazon CloudWatch, Azure Monitor, Google Cloud, Kubernetes, Prometheus, Jaeger, OpenTelemetry, PagerDuty, ServiceNow, Slack, et bien plus.
Pros and Cons
Pros:
- Prise en charge de l'association d'agents open source et de l'ingestion de données
- Offre la traçabilité distribuée pour les microservices
- Apprentissage automatique intégré pour la détection d’anomalies
Cons:
- Nécessite une infrastructure séparée pour l’hébergement en propre
- Consommation de ressources plus élevée que les agents légers
Grafana Cloud se distingue pour les équipes ayant besoin de visualisations de tableaux de bord avancées et personnalisables à partir de multiples sources de données. C’est un excellent choix pour les spécialistes informatiques, les ingénieurs DevOps et les analystes qui souhaitent centraliser métriques, journaux et traces en un seul endroit. Contrairement à Netdata, Grafana Cloud vous permet de créer des tableaux de bord hautement adaptés en s’appuyant sur un large éventail d’outils de surveillance et d’observabilité.
Pourquoi Grafana Cloud est une bonne alternative à Netdata
Si vous recherchez des visualisations de tableaux de bord avancées qui vont au-delà de ce que propose Netdata, Grafana Cloud est un excellent choix. J’ai sélectionné Grafana Cloud car il permet de créer des tableaux de bord hautement personnalisables rassemblant des données issues de plusieurs sources, y compris des métriques, des journaux et des traces. Son éditeur de panneaux supporte un large éventail de types de visualisation, des graphiques chronologiques aux cartes thermiques en passant par les cartes géographiques. Cette flexibilité permet aux équipes informatiques et aux ingénieurs de construire des vues de surveillance adaptées à leurs infrastructures et applications spécifiques.
Principales fonctionnalités de Grafana Cloud
D’autres fonctionnalités de Grafana Cloud aident les équipes à étendre leurs capacités de supervision et de visualisation :
- Moteur d’alertes : Prend en charge les notifications multi-canaux et des règles d’alerte personnalisées.
- Contrôles d’accès utilisateur : Permet de gérer les permissions et les rôles des différents membres de l’équipe.
- Marketplace de plugins : Propose un vaste choix de plugins pour sources de données et visualisations.
- Partage de snapshots : Permet de partager l’état des tableaux de bord pour collaborer ou résoudre des incidents.
Intégrations de Grafana Cloud
Les intégrations incluent Prometheus, Loki, Tempo, Mimir, Graphite, InfluxDB, Elasticsearch, MySQL, AWS CloudWatch, Zabbix, et bien d’autres.
Pros and Cons
Pros:
- Large marketplace de plugins pour des extensions
- Possibilité de partager des tableaux de bord via des liens de snapshot
- S’intègre nativement aux principaux outils de surveillance cloud
Cons:
- Pas de surveillance native au niveau système ou processus
- Rétention de données historiques limitée sans forfait payant
AWS CloudWatch est conçu spécifiquement pour les équipes qui gèrent des charges de travail sur AWS et qui ont besoin d’une visibilité approfondie et native sur leurs ressources cloud. Il est particulièrement utile pour les spécialistes IT et les ingénieurs cloud souhaitant surveiller, enregistrer les journaux et automatiser les réponses sur EC2, Lambda, RDS et d’autres services AWS. Contrairement à Netdata, CloudWatch propose une intégration directe avec l’infrastructure AWS, facilitant ainsi le suivi de l’état et des performances des ressources sans configuration supplémentaire.
Pourquoi AWS CloudWatch est une bonne alternative à Netdata
Pour les équipes qui gèrent l’infrastructure AWS, CloudWatch offre une surveillance native, parfaitement intégrée aux services AWS. J’ai choisi CloudWatch car il collecte automatiquement des métriques et des journaux provenant de ressources AWS telles qu’EC2, Lambda, RDS, sans configuration supplémentaire. Son tableau de bord unifié permet de visualiser l’état des ressources, de configurer des alarmes et d’automatiser des actions sur la base de données en temps réel. Ce lien direct avec les services AWS fait de CloudWatch une solide alternative à Netdata pour les environnements axés sur le cloud.
Fonctionnalités principales d’AWS CloudWatch
D’autres fonctionnalités d’AWS CloudWatch aident les équipes à gérer et analyser plus en profondeur leurs environnements AWS :
- Métriques personnalisées : vous permet de publier et de suivre vos propres métriques applicatives ou métiers en parallèle des données de ressources AWS.
- Log Insights : fournit un moteur de requêtes pour rechercher et analyser les journaux en temps réel.
- Détection d’anomalies : utilise l’apprentissage automatique pour détecter automatiquement des modèles de métriques inhabituels.
- Partage de tableaux de bord : vous permet de partager des tableaux de bord interactifs avec d’autres utilisateurs ou équipes AWS.
Intégrations AWS CloudWatch
Les intégrations incluent Amazon EC2, Amazon RDS, AWS Lambda, Amazon S3, Amazon ECS, Amazon EKS, Amazon DynamoDB, Amazon SNS, Amazon SQS, Amazon Kinesis, et bien d’autres.
Pros and Cons
Pros:
- Intégration native avec tous les services AWS
- Collecte automatisée des métriques et des journaux pour les ressources AWS
- Prend en charge la détection des anomalies grâce au machine learning
Cons:
- Visibilité limitée pour l’infrastructure non-AWS
- Les métriques personnalisées peuvent augmenter les coûts mensuels
Idéal pour la prise en charge des environnements hybrides
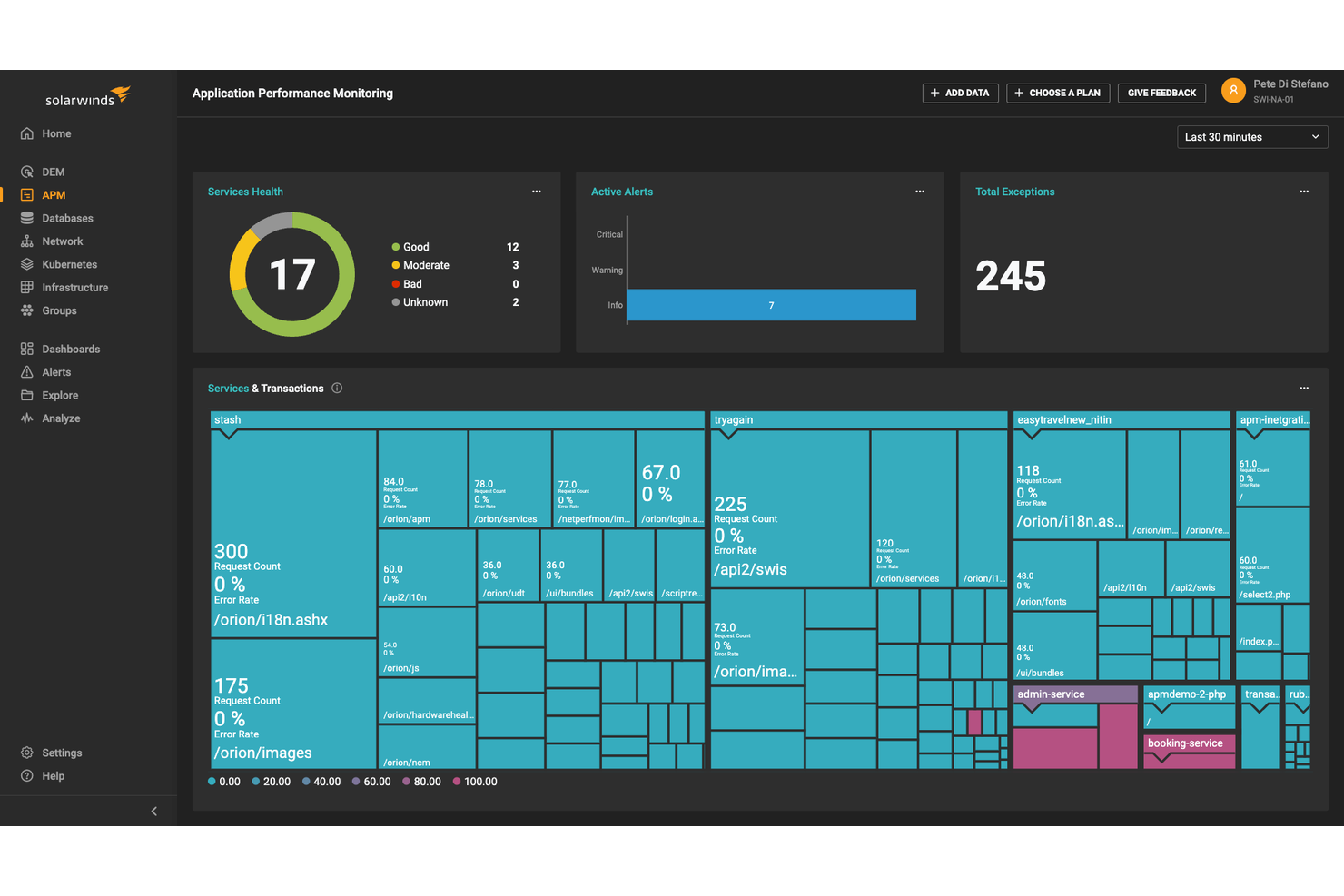
Les équipes informatiques qui gèrent à la fois des infrastructures sur site et dans le cloud trouveront dans SolarWinds Observability SaaS une solution conçue pour offrir une visibilité sur les environnements hybrides. La plateforme séduit les organisations ayant besoin d'une supervision unifiée de leurs serveurs, conteneurs et services cloud, sans avoir à jongler avec plusieurs outils. Contrairement à Netdata, AppOptics propose une surveillance intégrée de l’infrastructure et des applications, avec prise en charge du traçage distribué dans des environnements mixtes.
Pourquoi SolarWinds Observability SaaS est une bonne alternative à Netdata
Pour les organisations opérant à la fois dans le cloud et sur site, SolarWinds Observability SaaS se distingue par sa gestion des environnements hybrides. L’outil propose une surveillance unifiée des serveurs, conteneurs et services cloud natifs, ce que Netdata ne prend pas en charge de façon native dans les environnements mixtes. J’apprécie le fait qu’AppOptics intègre le traçage distribué et la surveillance de l’infrastructure sur une seule plateforme, ce qui facilite l’analyse des performances de toute votre pile. Cette approche aide les équipes IT à garder une visibilité complète et à diagnostiquer les problèmes, quelle que soit la localisation de leurs charges de travail.
Principales fonctionnalités de SolarWinds Observability SaaS
D’autres fonctionnalités d’AppOptics permettent aux équipes de tirer le meilleur parti de leur système de supervision :
- Prise en charge des métriques personnalisées : collecte et visualise les métriques applicatives et métiers personnalisées en plus de la télémétrie standard.
- Bibliothèque d’intégrations prêtes à l’emploi : propose un large éventail d’intégrations prêtes à l’emploi pour les bases de données, serveurs web et systèmes de messagerie populaires.
- Profilage du code en direct : fournit des informations en temps réel au niveau du code pour identifier les goulets d’étranglement en production.
- Règles d’alerte et de notification : permet aux utilisateurs de configurer des politiques d’alerte flexibles et de router les notifications vers l’e-mail, Slack ou d’autres canaux.
Intégrations SolarWinds Observability SaaS
Les intégrations incluent AWS, Azure, Cisco, Slack, Java, MySQL, MongoDB, PostgreSQL, Amazon Aurora, Redis, et bien d’autres.
Pros and Cons
Pros:
- Offre un profilage du code en direct pour les applications
- Inclut des intégrations prêtes à l’emploi pour les principales bases de données
- Propose des tableaux de bord et visualisations personnalisables
Cons:
- Pas d’option de déploiement uniquement sur site
- Ne possède pas de fonctionnalités intégrées de gestion des logs
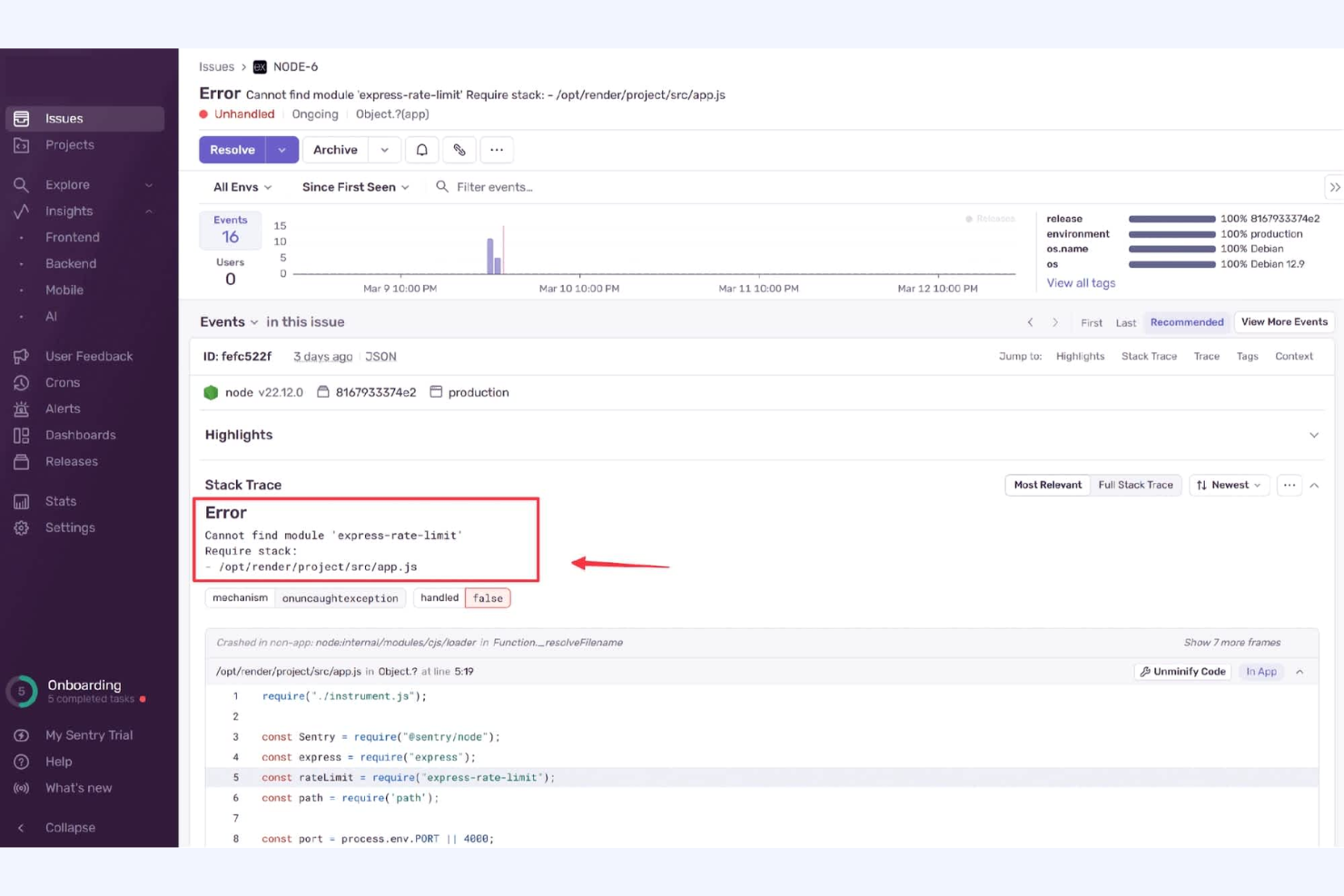
Les développeurs et les équipes d’ingénierie cherchant une visibilité approfondie sur les erreurs dans leurs déploiements de code se tournent souvent vers Sentry. La plateforme est spécialisée dans le suivi en temps réel des erreurs et la surveillance des performances des applications sur de nombreux langages et frameworks. Contrairement à Netdata, Sentry détecte précisément les problèmes au niveau du code et les régressions de versions, aidant les équipes à résoudre les bugs avant qu’ils n’affectent les utilisateurs.
Pourquoi Sentry est une bonne alternative à Netdata
Si votre principale préoccupation est de détecter et corriger les erreurs lors des déploiements de code, Sentry propose une solution ciblée que Netdata n’offre pas. Sentry suit les exceptions et les problèmes de performances au niveau du code, en fournissant des traces détaillées de la pile d’appels et un suivi des versions pour identifier rapidement la cause première des défaillances. J’apprécie la manière dont Sentry met en avant les nouvelles erreurs introduites lors des dernières versions, permettant d’identifier rapidement les régressions. Cela en fait un excellent choix pour les équipes qui doivent surveiller la santé de leur application du point de vue des développeurs.
Fonctionnalités clés de Sentry
D’autres fonctionnalités de Sentry aident les équipes à optimiser leurs processus de surveillance :
- Surveillance des performances : Suit les temps de transaction et la latence des applications pour repérer les ralentissements.
- Analyse de l’impact sur les utilisateurs : Indique quels utilisateurs sont affectés par des erreurs ou des soucis de performance spécifiques.
- Suivi de la santé des versions : Surveille l’adoption, les sessions sans crash et la stabilité de chaque version.
- Intégrations tierces : Se connecte à des outils comme GitHub, Jira et Slack pour une gestion simplifiée des incidents.
Intégrations Sentry
Les intégrations incluent GitHub, Slack, Jira, GitLab, Azure DevOps, Vercel, Bitbucket, PagerDuty, Microsoft Teams, Datadog, et d'autres.
Pros and Cons
Pros:
- Suit les erreurs jusqu’aux commits de code spécifiques
- Offre des alertes en temps réel pour les nouveaux problèmes
- Fournit des indicateurs de santé des versions pour les déploiements
Cons:
- La rétention des données d’événement dépend du forfait
- Nécessite l’intégration du SDK pour chaque application
New Product Updates from Sentry

Sentry Adds Heatmaps to Application Metrics
Sentry introduced heatmaps for Application Metrics to visualize metric value distributions over time, helping teams spot patterns like latency bursts and use heatmaps in Custom Dashboards. For more information, visit Sentry's official site.
 .
.Autres alternatives à Netdata
Voici quelques alternatives supplémentaires à Netdata qui n’ont pas été retenues dans ma sélection principale, mais qui méritent tout de même votre attention :
- Dynatrace
Idéal pour la détection des anomalies alimentée par l’IA
- ManageEngine Applications Manager
Idéal pour des workflows d’alertes personnalisables
- Riverbed
Idéal pour obtenir des informations sur les performances du réseau


{kind=link}
Critères de sélection des alternatives à Netdata
Pour choisir les meilleures alternatives à Netdata à inclure dans cette liste, j’ai pris en compte les besoins courants des acheteurs et les difficultés fréquemment rencontrées avec les outils de supervision applicative, comme la gestion d’environnements cloud distribués ou la réduction de la fatigue liée aux alertes. J’ai aussi appliqué le cadre suivant pour garder mon évaluation structurée et équitable :
Fonctionnalités principales (25 % de la note finale)
Pour figurer dans cette sélection, chaque solution devait répondre à ces cas d’usages essentiels :
- Surveiller la santé applicative et l’infrastructure
- Collecter et visualiser des métriques en temps réel
- Générer et gérer des alertes
- Stocker et rechercher les données de logs
- Assurer l’intégration avec les plateformes populaires
Fonctionnalités différenciantes (25 % de la note finale)
Pour départager les solutions, j’ai aussi recherché des fonctionnalités uniques, telles que :
- Analyse automatisée des causes racines
- Détection d’anomalies basée sur l’IA
- Traçabilité distribuée
- Création de métriques personnalisées et de tableaux de bord
- Workflows intégrés de gestion des incidents
Facilité d’utilisation (10 % de la note finale)
Pour estimer l’ergonomie de chaque système, j’ai pris en compte les éléments suivants :
- Navigation du tableau de bord simple et intuitive
- Options de visualisation des données claires
- Procédure de configuration des alertes logique
- Interface réactive et accessible
- Nombre d’étapes de configuration minimal pour les fonctionnalités essentielles
Intégration initiale (10 % du score total)
Pour évaluer l’expérience d’intégration de chaque plateforme, j’ai pris en compte les critères suivants :
- Disponibilité de guides d’installation étape par étape
- Accès à des vidéos de formation et à la documentation
- Visites interactives du produit ou démonstrations guidées
- Modèles préconçus pour des cas d’usage courants
- Prise en charge de la migration de données à partir d’autres outils
Service client (10 % du score total)
Pour évaluer la qualité du service client de chaque éditeur de logiciel, j’ai examiné les points suivants :
- Multiples canaux de support, dont chat et e-mail
- Délai de réponse rapide en cas de problème technique
- Accès à une base de connaissances ou un centre d’aide
- Disponibilité de forums communautaires ou groupes d’utilisateurs
- Possibilité de gestion de compte dédiée
Rapport qualité/prix (10 % du score total)
Pour évaluer le rapport qualité/prix de chaque plateforme, j’ai pris en considération les éléments suivants :
- Structure tarifaire transparente et prévisible
- Forfaits flexibles selon la taille des équipes
- Fonctionnalités incluses dans les abonnements d’entrée de gamme
- Coût de montée en charge avec des données ou des utilisateurs supplémentaires
- Disponibilité d’une offre d’essai ou d’un forfait gratuit
Avis des clients (10 % du score total)
Pour avoir un aperçu de la satisfaction générale des utilisateurs, j’ai tenu compte des critères suivants lors de la lecture des avis clients :
- Cohérence des retours positifs entre les différentes plateformes
- Commentaires signalant la fiabilité et la disponibilité
- Retours concernant le support et l’expérience d’intégration
- Commentaires utilisateurs sur l’utilité des fonctionnalités
- Fréquence des mises à jour et des améliorations
Pourquoi chercher une alternative à Netdata ?
Bien que Netdata soit un bon choix d’outil de surveillance applicative, il existe de nombreuses raisons pour lesquelles certains utilisateurs recherchent des solutions alternatives. Vous pouvez être à la recherche d’une alternative à Netdata parce que…
- Vous avez besoin d’une intégration plus poussée avec AWS ou d’autres plateformes cloud
- Vous souhaitez une prise en charge native du traçage distribué
- Vous exigez une détection avancée des anomalies par l’intelligence artificielle
- Vous cherchez un suivi centralisé sur des environnements hybrides ou multi-cloud
- Vous voulez une rétention des logs prolongée sans configuration supplémentaire
- Vous avez besoin de contrôles d’accès et de fonctions de conformité de niveau entreprise
Si l’un de ces points vous concerne, vous êtes au bon endroit. Ma sélection répertorie plusieurs solutions de surveillance applicative mieux adaptées aux équipes confrontées à ces besoins avec Netdata et en quête d’alternatives.
Fonctionnalités clés de Netdata
Voici quelques-unes des fonctionnalités principales de Netdata, pour vous aider à comparer ce que proposent les autres alternatives :
- Surveillance en temps réel des indicateurs systèmes et applicatifs
- Tableaux de bord interactifs avec visualisations personnalisables
- Détection automatique de centaines de métriques et services
- Agent léger pour une consommation de ressources minimale
- Surveillance de la santé système avec alarmes préconfigurées
- Streaming et stockage longue durée des métriques
- Collecte distribuée des données à partir de multiples nœuds
- Accès API pour des intégrations personnalisées
- Granularité à la seconde pour des données ultra-détaillées
- Architecture open-source avec une communauté active