10 mejores herramientas para el despliegue de modelos de ML en 2026

Mejores Herramientas para el Despliegue de Modelos ML - Selección Destacada


Las herramientas para el despliegue de modelos de ML te permiten tomar modelos de aprendizaje automático entrenados y convertirlos en servicios listos para producción que realmente puedes utilizar. Si buscas formas fiables de lanzar, monitorizar y gestionar tus aplicaciones potenciadas por IA, elegir la plataforma de despliegue correcta es esencial. La seguridad, la escalabilidad, la automatización y la transparencia pueden definir tu flujo de trabajo. En esta lista, detallo las herramientas de despliegue de ML en las que más confío y te muestro exactamente el lugar que cada una ocupa en tu stack, para que puedas elegir la plataforma que mejor se ajuste a las necesidades de tu proyecto y las expectativas de tu equipo.
Table of Contents
- Mejor software en resumen
- Por qué confiar en nosotros
- Comparar especificaciones
- Reseñas
- Otras herramientas para el despliegue de modelos de ML
- Reseñas relacionadas
- Criterios de selección
- Cómo elegir
- ¿Qué son las herramientas para el despliegue de modelos de ML?
- Características
- Beneficios
- Costes y precios
- Preguntas frecuentes
Por qué confiar en nuestras reseñas de software
Llevamos probando y revisando software desde 2023. Como líderes tecnológicos, sabemos lo crítico y difícil que es tomar la decisión correcta al seleccionar software.
Invertimos en una investigación profunda para ayudar a nuestra audiencia a tomar mejores decisiones de compra de software. Hemos probado más de 2,000 herramientas para diferentes casos de uso tecnológicos y escrito más de 1,000 reseñas de software exhaustivas. Descubre cómo mantenemos la transparencia y nuestra metodología de revisión de software.
Resumen de las Mejores Herramientas para el Despliegue de Modelos ML
Esta tabla comparativa resume los detalles de precios de mis selecciones principales de herramientas de despliegue de modelos ML para ayudarte a encontrar la mejor opción según tu presupuesto y las necesidades de tu negocio.
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | La mejor orquestación de modelos nativa para Kubernetes | Gratis para siempre | Gratis para siempre | Website | |
| 2 | Ideal para APIs de inferencia estandarizadas en Kubernetes | Gratis para siempre | Gratis para siempre | Website | |
| 3 | Ideal para empaquetar modelos como APIs de producción | Plan gratuito + demo gratuita disponible | Precio bajo solicitud | Website | |
| 4 | Ideal para alojar modelos transformer a escala | Plan gratuito + demo gratuita disponible | Desde $9/mes | Website | |
| 5 | Ideal para desplegar funciones Python sin servidor | Plan gratuito disponible | Desde $250 + cómputo/mes | Website | |
| 6 | Mejor para la gestión automatizada de modelos de extremo a extremo | Plan gratuito disponible | Desde $0.204/hora | Website | |
| 7 | Ideal para flujos de trabajo unificados de datos e IA | $300 en créditos gratis disponibles | Precio a consultar | Website | |
| 8 | Ideal para crear interfaces web personalizadas para modelos | Plan gratuito disponible | Precio disponible bajo solicitud | Website | |
| 9 | Ideal para prestación distribuida con Python y Ray | Crédito gratuito de $100 disponible | Precios bajo consulta | Website | |
| 10 | Mejor para gestionar modelos en industrias reguladas | Not available | Precios bajo solicitud | Website |
-

TestDevLab
Visit Website -
Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8


Reseñas de las Mejores Herramientas de Despliegue de Modelos ML
A continuación, encontrarás mis resúmenes detallados de las mejores herramientas para el despliegue de modelos ML que he incluido en mi selección destacada. Mis análisis ofrecen una visión detallada de las características, integraciones y los mejores casos de uso de cada plataforma para ayudarte a encontrar la mejor opción para ti.
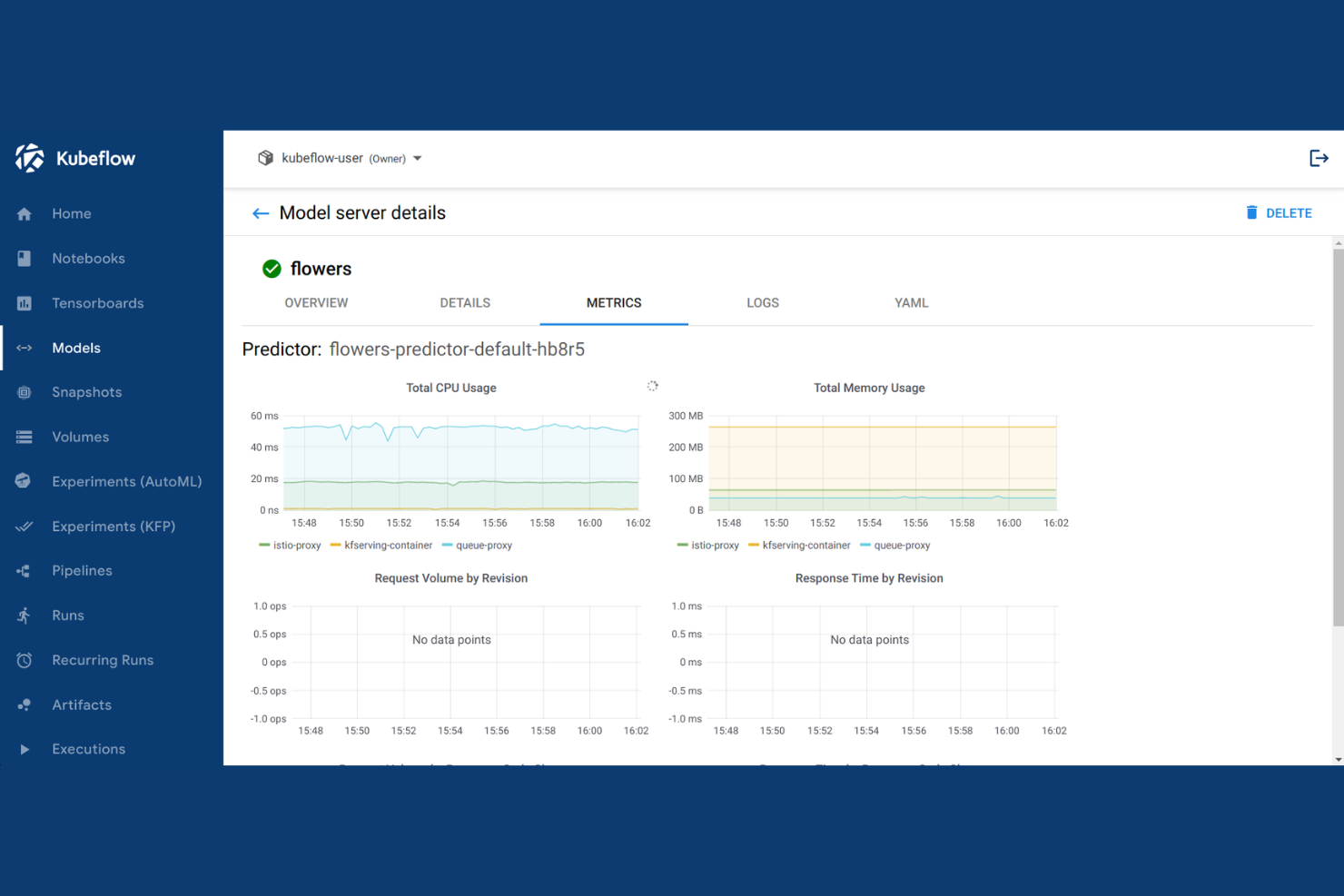
Kubeflow es una plataforma de ML de código abierto construida sobre Kubernetes que abarca la orquestación de flujos de trabajo, el entrenamiento de modelos, la optimización de hiperparámetros y el servicio de modelos de múltiples marcos tanto en infraestructura en la nube como local.
¿Para quién es mejor Kubeflow?
Kubeflow es una excelente opción para equipos de ingeniería de ML que ya utilizan Kubernetes y necesitan gestionar trabajos de entrenamiento a gran escala y la puesta en producción de modelos en su propia infraestructura.
Por qué elegí Kubeflow
Elegí Kubeflow como uno de los mejores porque está diseñado específicamente sobre Kubernetes, lo que significa que cada componente funciona como una carga de trabajo nativa de Kubernetes. Me gusta que Kubeflow Pipelines me permita definir flujos de trabajo de ML de extremo a extremo como DAGs en contenedores, de modo que cada paso escala de forma independiente. Kubeflow Trainer gestiona el entrenamiento distribuido en PyTorch, JAX y DeepSpeed sin necesidad de configurar clústeres personalizados. También puedo usar Katib para realizar búsquedas automatizadas de hiperparámetros directamente en los trabajos de entrenamiento en ejecución dentro del mismo clúster.
Características clave de Kubeflow
- KServe: Implementa modelos entrenados como servicios de inferencia escalables en Kubernetes utilizando entornos de ejecución preconstruidos para TensorFlow, PyTorch y scikit-learn.
- Registro de modelos: Almacena, versiona y rastrea modelos registrados a lo largo de las ejecuciones de entrenamiento antes de promocionarlos a entornos de servicio.
- Servidores de cuadernos: Lanza instancias de Jupyter notebook directamente en el clúster con asignaciones configurables de CPU, GPU y memoria.
- Aislamiento multiusuario: Gestiona espacios de nombres y controles de acceso separados para distintos equipos o proyectos dentro de un clúster compartido.
Integraciones de Kubeflow
Kubeflow no ofrece integraciones nativas tradicionales en el sentido SaaS, pero su arquitectura nativa de Kubernetes se conecta con un amplio ecosistema de herramientas de ML e infraestructura. Kubeflow Trainer admite entrenamiento distribuido en distintos marcos, incluidos PyTorch, HuggingFace, DeepSpeed, JAX y XGBoost. KServe es compatible con el protocolo OpenAI, lo que permite su uso con bibliotecas cliente OpenAI y herramientas como LangChain y LlamaIndex. Kubeflow Pipelines se ejecuta en Argo Workflows o Tekton como backend, y la plataforma se integra con herramientas de programación de Kubernetes como Kueue, Volcano y YuniKorn. Metaflow también se integra con Kubeflow, lo que permite desplegar flujos de Metaflow como Kubeflow Pipelines. Además, está en marcha una integración experimental con MLflow como subproyecto de Kubeflow.
Pros and Cons
Pros:
- Se implementa en todos los principales proveedores de Kubernetes en la nube
- Cada paso del pipeline se ejecuta en un contenedor aislado
- Destaca en entrenamiento distribuido y orquestación
Cons:
- La configuración inicial es compleja y demanda experiencia en Kubernetes
- Requiere un equipo dedicado a la plataforma para mantenerla
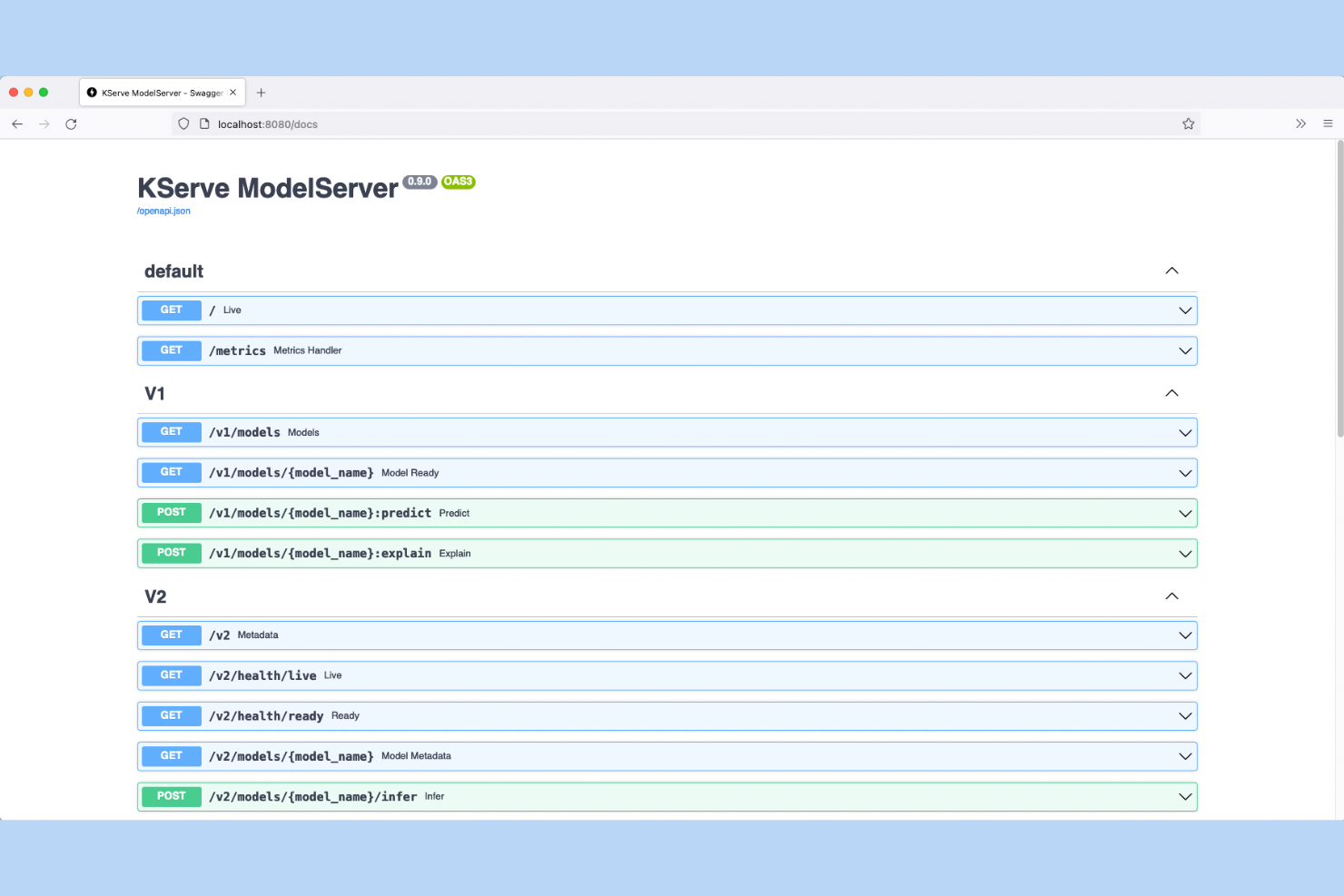
KServe es una plataforma de inferencia de modelos de código abierto y nativa de Kubernetes que gestiona el servicio de modelos de múltiples marcos, implementaciones canarias, autoescalado y explicabilidad de modelos a través de una capa API de inferencia estandarizada.
¿Para quién es mejor KServe?
KServe es ideal para equipos de ingeniería de ML en organizaciones medianas a grandes que ejecutan el servicio de modelos a escala en Kubernetes y necesitan una capa de inferencia independiente del marco.
Por qué elegí KServe
Elegí KServe como uno de los mejores porque está construido en torno al Protocolo de Inferencia Abierto (V2), una especificación de API estandarizada que permite a mi equipo intercambiar el backend de servicio, como Triton o vLLM, sin reescribir el código del cliente. También dependo de su CRD InferenceService para definir implementaciones canarias de forma declarativa, dirigiendo un porcentaje del tráfico en vivo a una nueva versión del modelo antes de su promoción total. Son compatibles tanto los endpoints de inferencia REST como gRPC, así que no estoy limitado a una sola capa de transporte.
Características clave de KServe
- Autoescalado a cero: El autoescalado impulsado por Knative apaga los pods de inferencia cuando están inactivos y los reactiva bajo demanda.
- Transformadores de solicitud/respuesta: La lógica de pre y posprocesamiento se ejecuta como un contenedor transformador independiente junto al servidor del modelo.
- Implementaciones canarias: Desvía gradualmente el tráfico hacia una nueva versión del modelo, lo que permite probar cambios en producción sin exposición completa.
- Registro de cargas útiles: Las solicitudes y respuestas de inferencia se registran en destinos configurables para seguimiento y monitoreo de modelos.
Integraciones de KServe
KServe incluye integraciones nativas con Knative, Istio y la API de Kubernetes Gateway para autoescalado sin servidor y enrutamiento de ingreso. Incluye entornos de ejecución integrados para vLLM, llm-d, NVIDIA Triton Inference Server, Seldon MLServer, TorchServe y Hugging Face, y admite almacenamiento de modelos en Amazon S3, Google Cloud Storage y Azure Blob Storage. Está disponible un SDK de Python para servicio y APIs de inferencia REST/gRPC para integraciones personalizadas.
Pros and Cons
Pros:
- Autoescalado a cero reduce los costes de GPU inactiva
- Servicio independiente del marco mediante protocolo de inferencia estandarizado
- Implementaciones canarias integradas para actualizaciones seguras
Cons:
- Requiere experiencia en clústeres de Kubernetes para operar
- El modo sin servidor limita la personalización de montajes de volúmenes
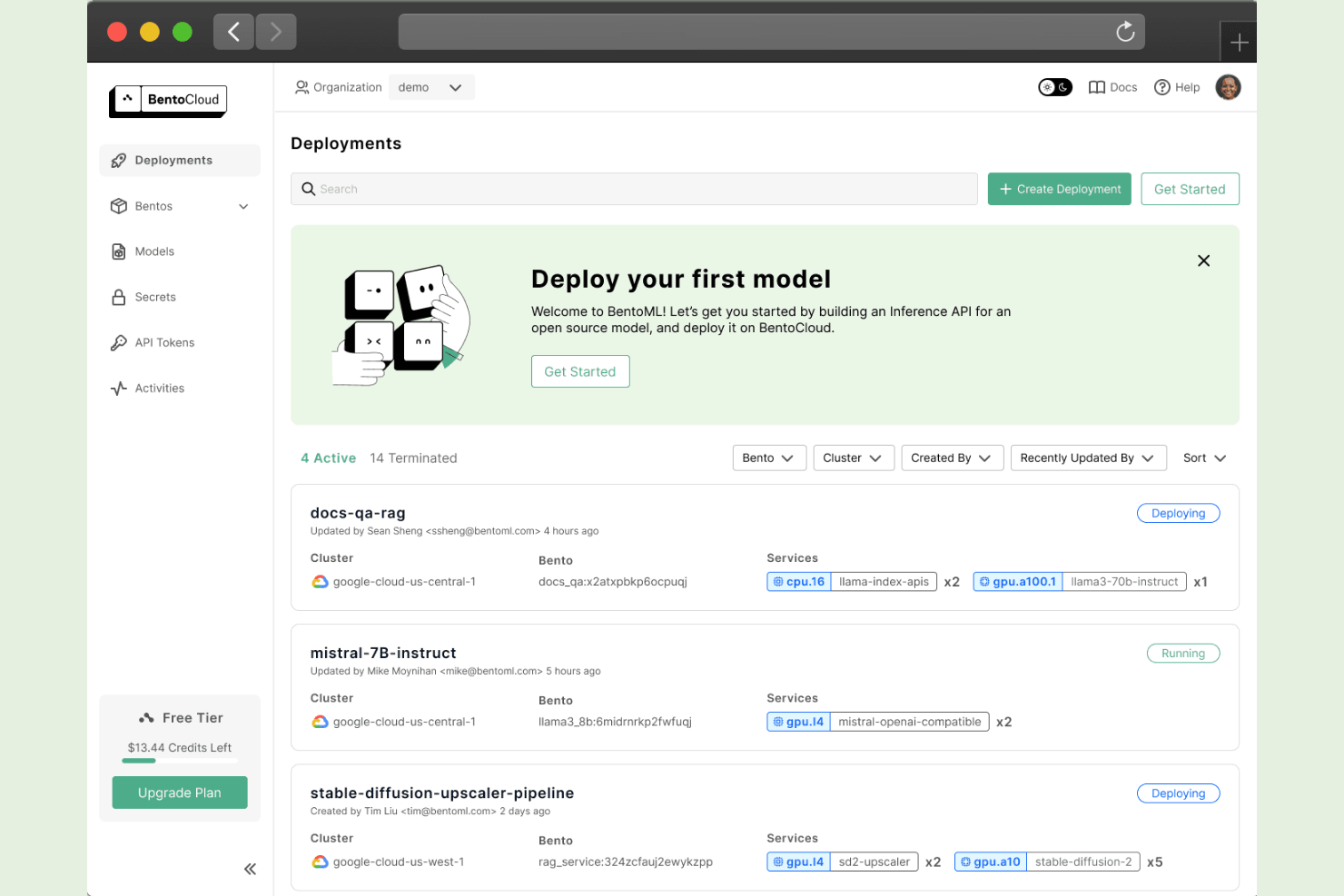
Construido en torno al concepto de un artefacto “Bento”, BentoML es un framework nativo de Python para la puesta en producción de modelos que gestiona la definición del servicio, la contenerización y el empaquetado de modelos de múltiples frameworks para su despliegue en producción.
¿Para quién es mejor BentoML?
BentoML es una excelente opción para equipos de aprendizaje automático en empresas en crecimiento que necesitan pasar rápidamente de un modelo entrenado a una API lista para producción sin una plataforma MLOps dedicada.
Por qué elegí BentoML
He incluido BentoML entre mis mejores opciones porque es uno de los pocos frameworks que trata el artefacto del modelo y la capa de servicio como una sola unidad versionada. Me gusta que BentoML genere automáticamente tanto endpoints REST como gRPC a partir de la misma definición de servicio, por lo que mi equipo no necesita mantener especificaciones de API separadas. La abstracción runner también me permite aislar cada modelo en su propio proceso, lo que significa que un paso de preprocesamiento basado en CPU no competirá por recursos con un runner de modelo en GPU.
Características clave de BentoML
- Batching adaptativo: Agrupa automáticamente solicitudes de inferencia concurrentes en un solo lote, reduciendo la sobrecarga de GPU por solicitud sin necesidad de cambios en el código.
- Métricas integradas con Prometheus: Expone un endpoint /metrics listo para usar para que puedas monitorizar la latencia de las solicitudes y el rendimiento sin instrumentación personalizada.
- Puerta de enlace LLM: Proporciona una interfaz API unificada para varios proveedores de LLM, otorgando control centralizado sobre el enrutamiento y los costes.
- Construcción de imágenes contenerizadas: Genera una imagen Docker lista para producción directamente desde un artefacto Bento usando un solo comando CLI.
Integraciones de BentoML
BentoML ofrece integraciones documentadas con herramientas del ecosistema MLOps, incluyendo Airflow, MLflow, Ray, Spark, Arize AI, Flink y Triton Inference Server. También se integra con Datadog para recopilar métricas de servicios BentoML. Hay una API disponible para integraciones personalizadas, y la salida contenerizada de BentoML funciona de forma nativa con Kubernetes y Docker para ofrecer flexibilidad de despliegue.
Pros and Cons
Pros:
- Versionado de modelos y seguimiento de rollback integrado
- Genera contenedores Docker a partir de configuración YAML
- Gestiona solicitudes concurrentes mediante escalado de workers
Cons:
- Los archivos de configuración pueden resultar innecesariamente complejos
- Los cargadores de modelos personalizados requieren configuración adicional
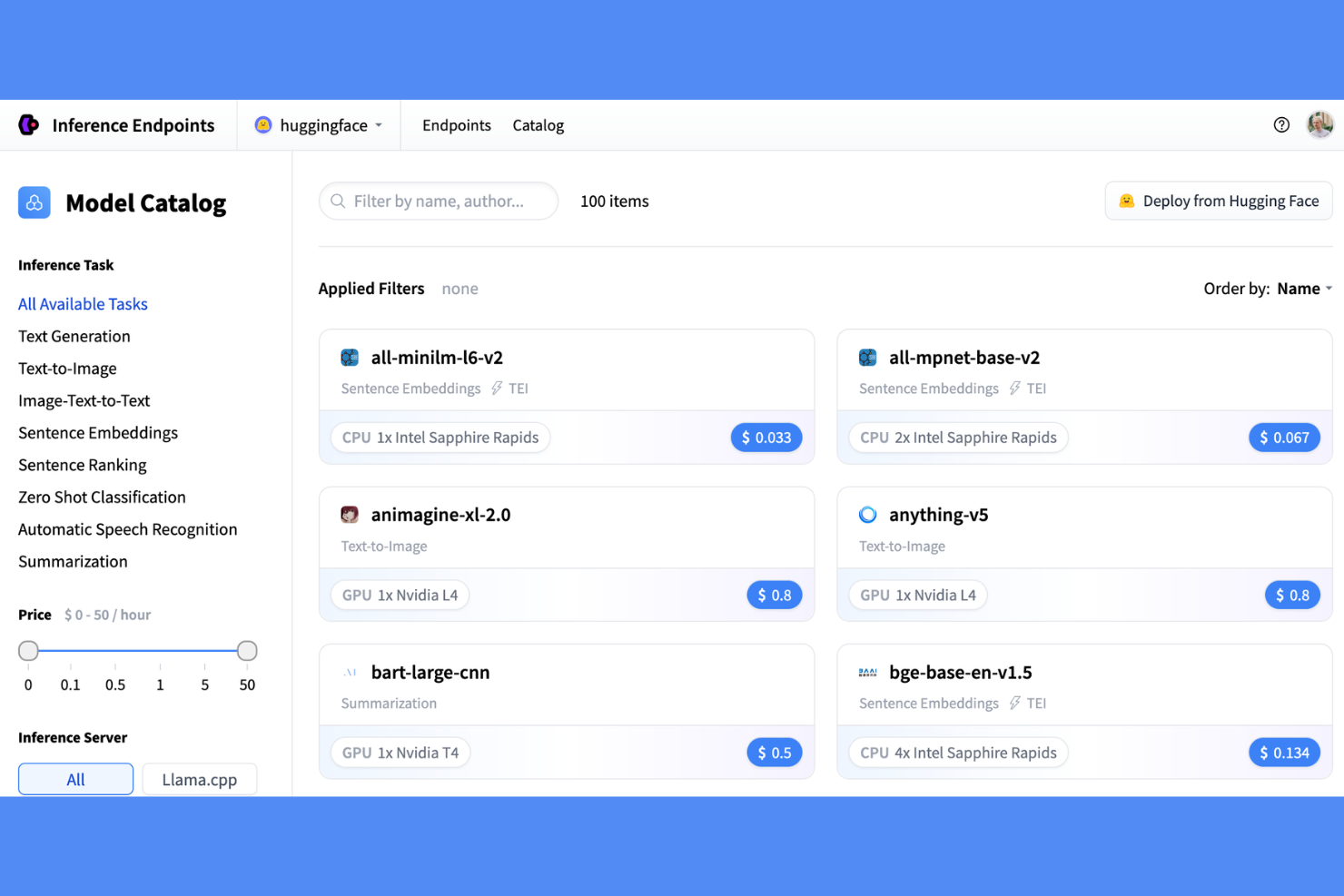
Una plataforma de inferencia gestionada construida sobre Hugging Face Hub, Hugging Face Inference Endpoints se encarga del despliegue dedicado en la nube, la configuración de los endpoints y la selección de hardware para modelos de ML en AWS, Azure y Google Cloud.
¿Para quién es ideal Hugging Face Inference Endpoints?
Es ideal para startups orientadas a la IA y empresas tecnológicas medianas que necesitan alojamiento de modelos listo para producción sin tener que construir y mantener su propia infraestructura de servicio.
Por qué elegí Hugging Face Inference Endpoints
Hugging Face Inference Endpoints se gana un lugar en mi lista porque está diseñado específicamente para el ecosistema de modelos transformer como ninguna otra plataforma de despliegue. Mi equipo puede tomar cualquier modelo del Hub, incluidos LLMs a gran escala y transformers multimodales, y servirlo a escala de producción con reglas de autoescalado configurables que responden al tráfico real. También me gusta la rapidez de pasar de cero al endpoint: un modelo que podría tardar días en contenerizar y desplegarse manualmente está activo en minutos.
Características clave de Hugging Face Inference Endpoints
- Despliegue multi-nube: Elige desplegar tu endpoint en AWS, Azure o Google Cloud sin gestionar cuentas independientes en la nube.
- Red privada: Aísla los endpoints dentro de una VPC dedicada para que solo tus sistemas internos puedan acceder a la API del modelo.
- Autenticación basada en tokens: Protege cada endpoint con un token de API para controlar qué servicios o usuarios pueden enviar solicitudes de inferencia.
- Monitorización de uso: Supervisa el volumen de solicitudes, la latencia y las tasas de error directamente desde el panel del endpoint en tiempo real.
Integraciones de Hugging Face Inference Endpoints
Hugging Face Inference Endpoints funciona con un ecosistema creciente de herramientas de desarrollo, frameworks y plataformas, y las herramientas sin soporte explícito suelen ser compatibles a través de su API compatible con OpenAI. Las integraciones documentadas incluyen AWS Bedrock y SageMaker, Google Gemini Enterprise Agent Platform y Azure AI Foundry, junto con frameworks de LLM como LangChain, LlamaIndex, Haystack, CrewAI y PydanticAI. Inference Endpoints puede gestionarse completamente mediante API, con endpoints documentados a través de Swagger, lo que permite crear integraciones personalizadas. El soporte con Zapier no está claramente documentado.
Pros and Cons
Pros:
- Despliegue con un clic desde el Hugging Face Hub
- Soporta múltiples motores de inferencia
- Autoescalado con facturación scale-to-zero
Cons:
- Arranques en frío cuando escala desde cero
- El coste del cómputo GPU aumenta rápidamente a escala
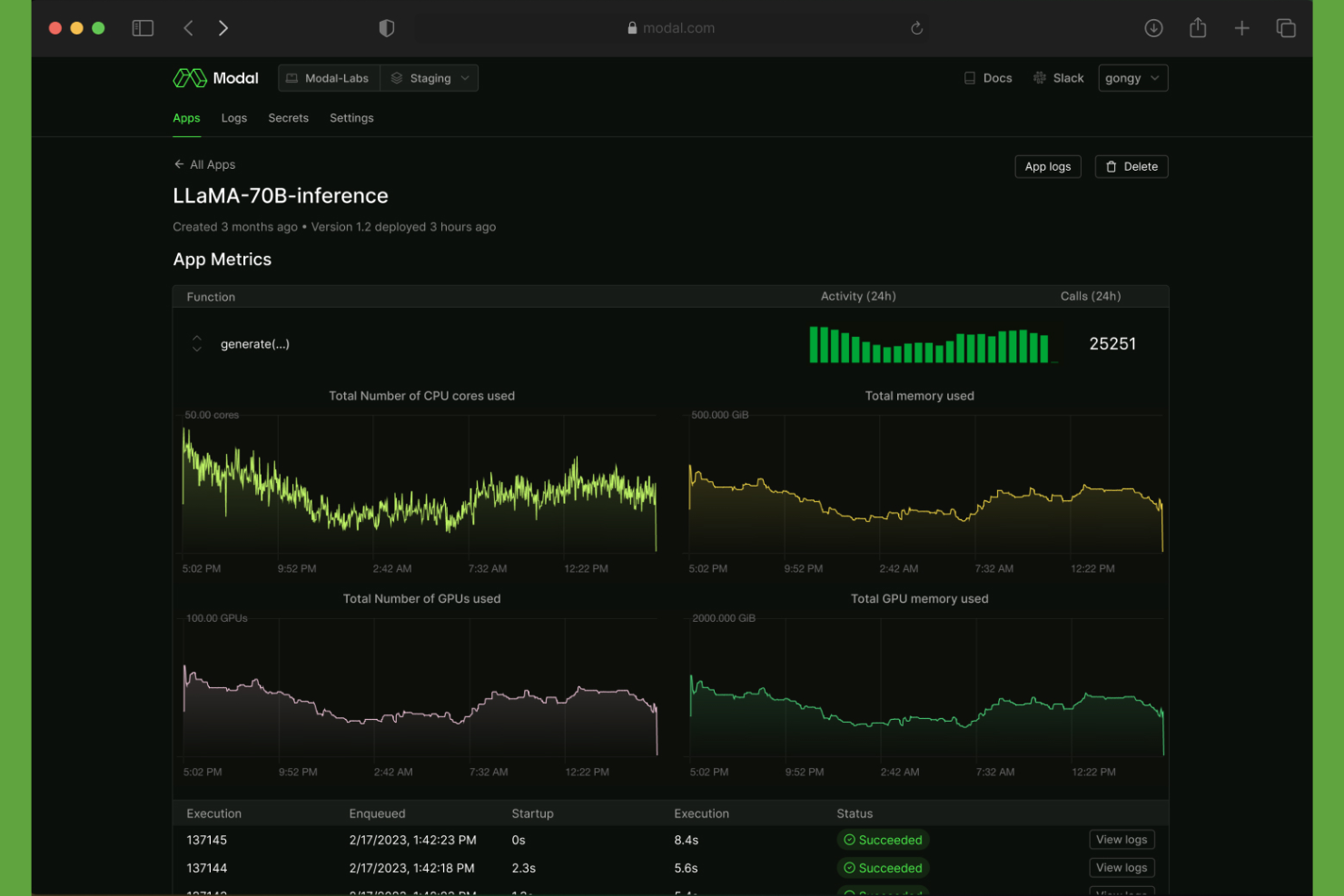
Modal es una plataforma en la nube sin servidor para ejecutar cargas de trabajo de aprendizaje automático basadas en Python, que abarca inferencias aceleradas por GPU, trabajos por lotes, ejecuciones de entrenamiento y tareas programadas sin necesidad de gestionar contenedores o infraestructura.
¿Para quién es ideal Modal?
Es una opción natural para startups y equipos en etapa de crecimiento que necesitan implementar modelos de aprendizaje automático rápidamente sin contratar ingenieros de infraestructura dedicados.
Por qué elegí Modal
He incluido Modal en mis mejores selecciones porque elimina la brecha entre escribir Python y ejecutarlo a escala en GPUs. Puedo solicitar hardware específico, como una A100 o H100, directamente en mi definición de función y Modal lo aprovisiona bajo demanda. No hay clústeres que gestionar ni archivos YAML que escribir. También me gusta que la misma función se ejecute de forma idéntica localmente y en producción, lo que reduce drásticamente el tiempo destinado a depuración.
Características clave de Modal
- Imágenes de contenedor personalizadas: Define dependencias, variables de entorno y paquetes de sistema directamente en el código, garantizando entornos de ejecución coherentes en todos los despliegues.
- Volúmenes persistentes: Monta volúmenes en la nube para almacenar en caché los pesos del modelo entre ejecuciones, reduciendo los tiempos de inicio en frío en implementaciones repetidas.
- Gestión de secretos: Almacena e inyecta claves API y credenciales de forma segura en tiempo de ejecución sin tener que codificarlas en tu base de código.
- Ejecución paralela por lotes: Utiliza .map() para ejecutar inferencia en grandes conjuntos de datos en paralelo a través de múltiples contenedores simultáneamente.
Integraciones de Modal
Modal ofrece un pequeño conjunto de integraciones documentadas centradas en la observabilidad y notificaciones, incluyendo Datadog, cualquier proveedor compatible con OpenTelemetry, Slack y Okta SSO. También es compatible con el montaje de buckets en la nube para AWS S3, Google Cloud Storage y Cloudflare R2, además de flujos de trabajo CI/CD a través de GitHub Actions. El soporte para Zapier no está documentado, pero Modal proporciona un SDK de Python y endpoints web que permiten integraciones personalizadas.
Pros and Cons
Pros:
- No se necesitan archivos Dockerfile ni configuración de Kubernetes
- Gestiona entrenamiento, procesamiento por lotes e inferencia
- Dirige cargas de trabajo a través de nubes y regiones
Cons:
- El código basado en decoradores crea dependencia de proveedor
- Las funciones empresariales requieren un precio de nivel premium

Amazon SageMaker (también conocido como AWS Sagemaker) es una plataforma de aprendizaje automático de AWS que abarca todo el ciclo de vida del modelo, desde el entrenamiento y ajuste fino hasta el despliegue, monitoreo y gobierno, dentro de un entorno de desarrollo unificado basado en arquitectura lakehouse.
¿Para Quién es Mejor Amazon SageMaker?
Amazon SageMaker es una excelente opción para equipos de ciencia de datos e ingeniería de ML que ya trabajan en el ecosistema de AWS.
Por Qué Elegí Amazon SageMaker
Amazon SageMaker se gana su lugar como uno de los mejores en mi lista porque cubre la gestión automatizada del modelo de extremo a extremo sin requerir la integración de herramientas separadas. Me gusta especialmente SageMaker MLOps, que gestiona la orquestación de pipelines, el registro de modelos y el seguimiento de despliegues en un solo lugar. También confío en las capacidades integradas de inferencia, operaciones de IA y observabilidad de SageMaker AI para monitorear los modelos después del despliegue y detectar desviaciones antes de que se conviertan en un problema en producción.
Funciones Clave de Amazon SageMaker
- SageMaker JumpStart: Accede a más de 1,000 modelos de IA preconstruidos de proveedores líderes y despliega o ajusta directamente en SageMaker.
- SageMaker HyperPod: Escala tareas de entrenamiento y ajuste fino a través de clústeres con cientos o miles de aceleradores de IA con gestión automatizada de clústeres.
- Inferencia multimodal: Despliega modelos usando inferencia en tiempo real, sin servidor, asíncrona o por lotes en más de 70 tipos de instancias.
- MLflow gestionado: Haz seguimiento, organiza y compara experimentos iterativos sin aprovisionamiento de infraestructura ni gestión de servidores.
Integraciones de Amazon SageMaker
Amazon SageMaker se integra de forma nativa en todo el ecosistema de AWS, incluyendo Amazon S3, Amazon Redshift, Amazon Athena, Amazon EMR y AWS Glue, junto con Amazon Bedrock y Amazon Q Developer. También funciona con herramientas de terceros como Datadog, Hugging Face, MLflow y Pinecone. Hay disponible una API para integraciones personalizadas.
Pros and Cons
Pros:
- Múltiples modos de inferencia para diferentes cargas de trabajo
- AutoML y ajuste de hiperparámetros integrados
- Pruebas en sombra para despliegues de modelos seguros
Cons:
- Está muy acoplado al ecosistema de AWS
- Es difícil depurar trabajos de entrenamiento fallidos
Ideal para flujos de trabajo unificados de datos e IA
Gemini Enterprise Agent Platform (anteriormente Vertex AI) es la plataforma de aprendizaje automático de extremo a extremo de Google Cloud que abarca el entrenamiento de modelos, ajuste fino, evaluación, implementación y el desarrollo de agentes de IA dentro de un solo entorno gestionado.
¿Para quién es mejor Gemini Enterprise Agent Platform?
Gemini Enterprise Agent Platform es ideal para equipos de ingeniería de aprendizaje automático y ciencia de datos que ya operan infraestructura de datos en Google Cloud Platform.
Por qué elegí Gemini Enterprise Agent Platform
Incluí Gemini Enterprise Agent Platform en mis principales opciones porque realmente elimina la brecha entre la gestión de datos y modelos. Me gusta particularmente cómo Gemini Enterprise Agent Platform Pipelines se conecta directamente a BigQuery, permitiendo a mi equipo construir flujos de trabajo de entrenamiento sobre datos en vivo del almacén sin tener que exportar nada. El Feature Store de Gemini Enterprise Agent Platform también nos permite definir, servir y monitorear características de manera consistente tanto en entrenamiento como en inferencia, lo que elimina una fuente importante de desviación entre entrenamiento y servicio.
Características clave de Gemini Enterprise Agent Platform
- Registro de modelos de Gemini Enterprise Agent Platform: Un repositorio centralizado para versionar, organizar y gestionar modelos a lo largo de su ciclo de vida completo antes y después de la implementación.
- Puntos finales de predicción en línea: Implementa modelos en puntos finales dedicados que ofrecen predicciones en tiempo real con recursos computacionales configurables y división de tráfico entre versiones de modelos.
- Monitoreo de modelos de Gemini Enterprise Agent Platform: Detecta la desviación de características y el desplazamiento de predicciones en los modelos implementados comparando el tráfico en vivo contra una línea base de datos de entrenamiento.
- Experimentos de Gemini Enterprise Agent Platform: Rastrea, compara y visualiza ejecuciones de entrenamiento iterativo para ayudar a los equipos a identificar las configuraciones de modelos con mejor desempeño.
Integraciones de Gemini Enterprise Agent Platform
Gemini Enterprise Agent Platform se integra de manera nativa en todo el ecosistema de Google Cloud, incluyendo BigQuery, Cloud Storage, Dataflow y Pub/Sub, además de soporte para Kubeflow Pipelines y contenedores preconstruidos para TensorFlow, scikit-learn, XGBoost y PyTorch. Sus almacenes de datos también admiten conectores de datos de terceros para herramientas como Jira y Shopify. Está disponible en Zapier, y hay una API disponible para integraciones personalizadas.
Pros and Cons
Pros:
- Model Garden ofrece más de 200 modelos desplegables
- La implementación basada en endpoints desde Model Garden es sencilla
- Integración nativa con BigQuery para flujos de datos
Cons:
- Los endpoints dedicados inactivos siguen generando cargos
- Las discrepancias de región generan mensajes de error poco claros

Baseten es una plataforma de inferencia de modelos que permite a los equipos de aprendizaje automático (ML) implementar modelos personalizados, de código abierto y ajustados finamente con servicio acelerado por GPU, escalado automático y herramientas de optimización del rendimiento integradas directamente en la plataforma.
¿Para quién es ideal Baseten?
Baseten es adecuado para equipos de productos de IA en empresas en etapa de crecimiento que necesitan control total sobre el rendimiento de inferencia para implementaciones de modelos sensibles a la latencia o de alto rendimiento.
Por qué elegí Baseten
Baseten se gana su lugar en mi lista porque permite construir e implementar interfaces web personalizadas sobre tus modelos dentro de la misma plataforma, sin necesidad de una pila frontend independiente. Uso el generador de aplicaciones de Baseten para crear interfaces interactivas que llaman directamente a los endpoints de los modelos, lo que resulta útil para herramientas internas o demostraciones a partes interesadas. El modelo y su interfaz permanecen bajo control de versiones e implementados juntos.
Funciones clave de Baseten
- Empaquetado de modelos Truss: Empaqueta cualquier modelo personalizado o ajustado finamente como un artefacto de Python reproducible con gestión de dependencias incorporada y recarga en vivo para pruebas locales.
- Baseten Chains: Construye flujos de trabajo de IA compuestos de varios pasos donde cada paso se ejecuta en hardware configurado independientemente con su propia política de escalado automático.
- Gestión de secretos: Almacena e inyecta claves API y credenciales de entorno directamente en las implementaciones de modelos sin tener que incluirlas en el código de servicio.
- División de tráfico A/B: Deriva tráfico de inferencia en vivo entre varias versiones de modelos simultáneamente para comparar el rendimiento antes de promover completamente un nuevo despliegue.
Integraciones de Baseten
Baseten permite exportar métricas a Prometheus, Datadog, Grafana Cloud y New Relic a través de su endpoint de métricas basado en OpenTelemetry. Es totalmente compatible con OpenAI, por lo que puedes conectarlo a cualquier cliente o pasarela que utilice el SDK de OpenAI, incluyendo LiteLLM, LlamaIndex y Cloudflare AI Gateway. Hay una API disponible para integraciones personalizadas.
Pros and Cons
Pros:
- El empaquetado open-source Truss simplifica el despliegue de modelos
- Implementación con un clic desde checkpoints de entrenamiento
- Inicios en frío en menos de un segundo en instancias de GPU
Cons:
- La tarifa basada en uso puede variar de forma impredecible
- Requiere experiencia en ingeniería de ML para operar

Construido sobre el framework de código abierto Ray, Anyscale es una plataforma administrada para la prestación de modelos de ML que gestiona inferencias distribuidas, escalado automático y despliegues de múltiples modelos en clústeres de GPU y CPU.
¿Para quién es ideal Anyscale?
Anyscale es especialmente adecuado para ingenieros de ML y equipos de ciencia de datos en organizaciones medianas y grandes que ejecutan cargas de trabajo basadas en Python a escala y necesitan gestión de clústeres de GPU sin la sobrecarga manual de infraestructura.
Por qué elegí Anyscale
Elegí Anyscale como uno de los mejores porque es la única plataforma administrada construida directamente sobre Ray, lo que significa que mi equipo puede escribir Python estándar para definir la lógica distribuida de prestación sin aprender un DSL de orquestación separado. Me gusta especialmente la API de gráficos de despliegue de Ray Serve, que me permite componer múltiples modelos en una única canalización de inferencia con rutas de solicitud explícitas. La asignación fraccionaria de GPU es otra característica que uso habitualmente para empaquetar modelos ligeros en hardware compartido sin tener que iniciar instancias dedicadas.
Características clave de Anyscale
- Escalado automático: Escala automáticamente el número de réplicas hacia arriba o hacia abajo según el rendimiento de solicitudes en tiempo real y la profundidad de la cola.
- División de tráfico: Dirige un porcentaje configurable del tráfico en vivo a nuevas versiones de modelos para implementaciones graduales sin tiempo de inactividad.
- Agrupación de solicitudes: Agrupa las solicitudes de inferencia entrantes en lotes para maximizar el uso de GPU entre llamadas concurrentes.
- Prestación de modelos multi-nodo: Distribuye un solo modelo grande entre varios nodos cuando este supera los límites de memoria de una sola GPU.
Integraciones de Anyscale
Anyscale se integra con las bibliotecas y frameworks de IA/ML más populares, con más de 50 integraciones que abarcan plataformas de datos, orquestación, frameworks de ML, observabilidad y frameworks para aplicaciones LLM. Entre ellas se incluyen MLflow, Weights & Biases, MongoDB, Snowflake, Databricks, Hugging Face, PyTorch y TensorFlow, además de Airflow, Prefect, Dagster, Datadog, LangChain y LlamaIndex. Hay una API disponible para integraciones personalizadas, y la plataforma también se despliega como servicio de primera parte en Amazon EKS, Google GKE, Azure AKS y OCI Kubernetes Engine.
Pros and Cons
Pros:
- Escala código Python en clústeres distribuidos de GPU
- Prestación de modelos independiente del framework a través de Ray Serve
- Soporte para instancias spot con tolerancia a fallos automática
Cons:
- Estrechamente acoplado al ecosistema Ray
- Requiere amplios conocimientos de sistemas distribuidos

Otras Herramientas para el Despliegue de Modelos ML
Aquí tienes algunas opciones adicionales de herramientas para el despliegue de modelos ML que no llegaron a mi selección destacada, pero que aún así vale la pena revisar:


{kind=link}
Cómo evalúo las herramientas de despliegue de modelos de ML
Evalúo cada herramienta en dos niveles: la base para desplegar un modelo PyTorch en un endpoint REST con escalado automático y monitoreo de deriva, y los diferenciadores que importan para los equipos de MLOps.
Funcionalidad principal (Requisitos básicos para esta lista)
Cuando selecciono herramientas para mi lista, califico cada una en una escala del 0 (no ofrece la funcionalidad) al 5 (destaca en esta área) para cada funcionalidad principal que se lista a continuación. Luego, calculo la puntuación total de la herramienta como un porcentaje. Cada herramienta necesita alcanzar una puntuación mínima total del 65% para ser considerada.
- Servicio de modelos e inferencia: Analizo si la herramienta puede alojar modelos detrás de endpoints REST o gRPC para predicciones en tiempo real y si también gestiona inferencia por lotes para trabajos de puntuación en modo offline.
- Soporte para múltiples frameworks: Verifico qué frameworks de ML se incluyen de forma nativa—como TensorFlow, PyTorch, XGBoost y ONNX—y si hay opción de contenedores personalizados para runtimes menos comunes.
- Versionado y registro de modelos: Un registro sólido te permite rastrear artefactos de modelos, metadatos y linaje para que puedas revertir un despliegue problemático en minutos en vez de buscar a ciegas el artefacto correcto.
- Escalabilidad y gestión de recursos: Evalúo cómo funciona el escalado automático bajo carga, si la asignación de GPU y CPU es configurable y si la herramienta soporta escalado hasta cero para reducir costes cuando está inactiva.
- Monitoreo y observabilidad: Los modelos en producción se degradan en silencio, así que busco detección de deriva de datos, seguimiento de latencia de predicción y alertas que señalen problemas de rendimiento antes de que afecten a los usuarios finales.
- CI/CD y automatización del despliegue: Considero si la herramienta soporta pipelines automatizados con estrategias de despliegue progresivo como canary o pruebas A/B, además de triggers basados en Git para el re-despliegue de modelos.
Una vez tengo una lista de herramientas que cumplen estos criterios, considero qué distingue a cada plataforma.
Factores diferenciadores (Lo que distingue a los proveedores)
Así es como comparo y contrasto diferentes proveedores:
Características sobresalientes
Los despliegues canary y en sombra distinguen a las herramientas. Busco la capacidad de enrutar una porción del tráfico en vivo a una nueva versión del modelo mientras la versión actual sigue sirviendo; esto permite detectar regresiones de precisión antes de que lleguen a todos los usuarios. La optimización para GPU es otra clave: el batching dinámico y el soporte de cuantización mediante aceleradores como NVIDIA Triton o TensorRT pueden reducir drásticamente el coste por predicción en volúmenes altos. Escalar a cero también es fundamental, ya que los endpoints inactivos consumiendo horas de GPU pueden elevar rápidamente los costes en cargas de trabajo con alta demanda de inferencias.
Más allá de las características
La integración al ecosistema MLOps es clave: reviso si la herramienta conecta con rastreadores de experimentos como MLflow o Weights & Biases, orquestadores como Airflow y sistemas de CI/CD como GitHub Actions. La flexibilidad de infraestructura es igualmente importante: los equipos en industrias reguladas suelen requerir opciones de Kubernetes autogestionado o BYOC en vez de un SaaS puro. También evalúo políticas de gobernanza y cumplimiento, especialmente RBAC, registros de auditoría y certificaciones como SOC 2 o HIPAA, que los equipos de seguridad empresarial exigirán durante la adquisición.
Cómo Elegir Herramientas para el Despliegue de Modelos ML
Es fácil perderse en largas listas de funciones y estructuras de precios complejas. Para ayudarte a mantener el enfoque mientras avanzas en tu proceso único de selección de software, aquí tienes una lista de factores a tener en cuenta:
| Factor | Qué Considerar |
|---|---|
| Escalabilidad | ¿La herramienta gestionará aumentos repentinos en el tráfico de inferencia sin intervención manual? Verifica si admite tanto escenarios de picos como de bajo volumen. |
| Integraciones | ¿La plataforma se conecta nativamente con tus rastreadores de experimentos, herramientas de CI/CD o almacenes de datos, o necesitarás desarrollar y mantener código personalizado? |
| Personalización | ¿Puedes adaptar los flujos de trabajo de despliegue, los controles de acceso a modelos y la gestión de recursos según tus políticas específicas y la estructura del equipo? |
| Facilidad de uso | ¿Qué tan pronunciada es la curva de aprendizaje para tu equipo? Considera la complejidad de la interfaz, la calidad de la documentación y si la incorporación ralentizará otros proyectos. |
| Implementación y puesta en marcha | ¿Cuánto tiempo de ingeniería se requiere para pasar de la prueba a la producción? Presta atención a posibles pasos ocultos de configuración, requisitos de red o formación obligatoria. |
| Costo | ¿Los modelos de precios son transparentes y predecibles a medida que aumenta el uso? Compara los métodos de facturación—por predicción, hora de cómputo o endpoint—según tus cargas de trabajo. |
| Salvaguardas de seguridad | ¿Qué mecanismos de cifrado, control de acceso y auditoría existen? Evalúa si la oferta cumple con los estándares internos de seguridad y las necesidades de tus clientes. |
| Requisitos de cumplimiento | ¿Necesitarás HIPAA, GDPR o SOC 2 Tipo II? Confirma que el proveedor proporciona las certificaciones necesarias y soporta las auditorías requeridas para tu sector. |
¿Qué Son las Herramientas para el Despliegue de Modelos ML?
Las herramientas de despliegue de modelos de ML son plataformas que te ayudan a operacionalizar modelos de aprendizaje automático entrenados, poniéndolos a disposición a través de APIs o puntos finales por lotes para su uso en entornos reales. Estas herramientas gestionan tareas como el servicio de modelos, escalado, monitoreo y versionado, para que puedas proporcionar predicciones precisas y mantener la confiabilidad a medida que evolucionan las cargas de trabajo.
Características de las herramientas de despliegue de modelos de ML
Al seleccionar herramientas de despliegue de modelos de ML, presta atención a las siguientes características clave:
- Soporte multiframework: Permite desplegar modelos construidos con TensorFlow, PyTorch, scikit-learn, XGBoost y ONNX sin necesidad de reescribir el código del modelo ni pasos de conversión.
- Inferencia con autoescalado: Asigna automáticamente recursos de cómputo según los patrones de tráfico, gestionando picos repentinos o periodos de bajo uso para mantener tanto el rendimiento como la eficiencia de costes.
- Versionado de modelos: Mantiene un seguimiento de las diferentes versiones de los modelos, facilitando revertir, comparar o promover modelos en los pipelines de producción con mínima interrupción.
- Despliegues canario y en sombra: Permite lanzamientos graduales o el espejado de tráfico en vivo, para validar de manera segura los nuevos modelos frente a datos reales antes del despliegue completo.
- Servicio batch y en tiempo real: Ofrece soporte tanto para APIs en tiempo real como para procesamiento asíncrono por lotes, dando flexibilidad para aplicaciones empresariales o flujos de trabajo de ciencia de datos.
- Gestión de recursos: Permite asignar y monitorear el uso de CPU, GPU y memoria por modelo, ayudando a optimizar costes y mantener la salud del servicio en producción.
- Medidas de seguridad: Incluye control de acceso, cifrado y aislamiento de red para proteger artefactos de modelos y datos sensibles de inferencia.
- Soporte de integración: Se conecta de forma nativa o a través de API con herramientas de MLOps, pipelines de CI/CD e infraestructura de datos para agilizar la entrega continua y el monitoreo.
- Registro y monitoreo: Proporciona visibilidad sobre registros de solicitudes, métricas de latencia y tasas de error para facilitar la resolución proactiva de problemas y la confiabilidad operacional.
- Conformidad y auditabilidad: Incluye características como registros de auditoría y soporte de cumplimiento normativo, ayudando a satisfacer requisitos de la industria en sanidad, finanzas u otros sectores regulados.
Funciones de IA comunes en herramientas de despliegue de modelos de ML
Además de las funciones estándar mencionadas arriba, muchas de estas soluciones están incorporando IA con características tales como:
- Detección automática de deriva: Emplea IA para monitorear los datos entrantes y las predicciones en busca de cambios en la distribución, alertando a los equipos cuando es necesario un reentrenamiento o una investigación para mantener la precisión del modelo.
- Asignación inteligente de recursos: Utiliza algoritmos de IA para predecir patrones de carga de trabajo y asignar dinámicamente recursos de cómputo, reduciendo costes y minimizando la latencia sin ajustes manuales.
- Despliegues auto-recuperables: Aprovecha la IA para detectar puntos finales de modelos fallidos o degradados y redirigir el tráfico automáticamente o iniciar el redespliegue, minimizando el tiempo de inactividad y la intervención manual.
- Escalado predictivo: Usa IA para pronosticar picos o caídas de tráfico según el historial de uso, escalando proactivamente la infraestructura para garantizar un rendimiento constante y control de costes.
- Detección de anomalías en inferencia: Emplea IA para señalar solicitudes de predicción inusuales o sospechosas en tiempo real, ayudando a los equipos a identificar posibles problemas de calidad de datos o amenazas de seguridad.
- Análisis automático de causa raíz: Utiliza IA para analizar registros y métricas, identificando la fuente de caídas de rendimiento o errores, para que los equipos puedan resolver problemas más rápido y con menos conjeturas.
Beneficios de las herramientas de despliegue de modelos de ML
Implementar herramientas de despliegue de modelos de ML aporta varios beneficios para tu equipo y tu negocio. Aquí tienes algunos que puedes esperar:
- Ciclos de despliegue acelerados: El empaquetado automatizado, la gestión de versiones y la integración con pipelines CI/CD permiten que los equipos lleven los modelos del desarrollo a la producción rápidamente.
- Escalabilidad constante: El autoescalado y la gestión dinámica de recursos aseguran que tus despliegues se mantengan estables y sean responsivos a medida que cambia la demanda.
- Mayor postura de seguridad: Los controles de acceso incorporados, la encriptación y el registro de auditoría ayudan a resguardar los modelos y los datos sensibles conforme a las exigencias organizativas y regulatorias.
- Menor sobrecarga operativa: El monitoreo, las alertas y el registro centralizados minimizan la resolución manual de problemas y liberan recursos técnicos para trabajos de mayor valor.
- Gobernanza confiable de modelos: La gestión de versiones y el registro de despliegues facilitan el seguimiento de los modelos, revertir cambios y demostrar cumplimiento durante auditorías.
- Integración flexible de flujos de trabajo: El soporte para múltiples frameworks, estrategias de despliegue y configuraciones de entornos permite adaptar las capacidades de las herramientas a las necesidades del negocio.
- Mayor preparación para el cumplimiento: Los registros completos de auditoría y las funciones de cumplimiento facilitan cumplir con requerimientos de HIPAA, GDPR u otros sectores, reduciendo riesgos para negocios regulados.
Costos y precios de las herramientas para desplegar modelos de ML
Seleccionar herramientas para desplegar modelos de ML requiere comprender los diferentes modelos y planes de precios disponibles. Los costos varían según las funciones, el tamaño del equipo, los complementos y más. La tabla a continuación resume los planes más comunes, sus precios promedio y las características típicas que incluyen las soluciones para despliegue de modelos de ML:
Tabla comparativa de planes para herramientas de despliegue de modelos de ML
| Tipo de plan | Precio promedio | Características comunes |
|---|---|---|
| Plan gratuito | $0 | Despliegues limitados, monitoreo básico, acceso para un solo usuario y soporte comunitario. |
| Plan personal | $10-$30/usuario/mes | Uso individual, versionado estándar de modelos, asignación moderada de recursos y soporte por correo electrónico. |
| Plan empresarial | $40-$100/usuario/mes | Colaboración en equipo, autoescalado, soporte para integraciones, seguridad mejorada y controles de acceso por roles. |
| Plan corporativo | $150-$500+/usuario/mes | Cumplimiento avanzado, soporte premium, infraestructura dedicada, SLA personalizados y herramientas ampliadas de auditoría y seguridad. |
Preguntas frecuentes sobre herramientas para desplegar modelos de ML
Aquí hay respuestas a preguntas comunes sobre las herramientas de despliegue de modelos de ML:
¿Cómo se diferencian las herramientas para desplegar modelos de ML de las herramientas tradicionales de despliegue de aplicaciones?
Las herramientas para desplegar modelos de ML están diseñadas para afrontar los retos únicos de servir, monitorear y actualizar modelos de aprendizaje automático, como gestionar versiones de modelos, rastrear registros de inferencias, soportar autoescalado para el tráfico de modelos e integrarse con flujos de datos. Las herramientas tradicionales de despliegue de aplicaciones normalmente no atienden estos requerimientos.
¿Puedo desplegar modelos creados en distintos frameworks con la misma herramienta de despliegue?
Sí, la mayoría de herramientas para desplegar modelos de ML ofrecen compatibilidad con múltiples frameworks, permitiéndote desplegar modelos de TensorFlow, PyTorch, XGBoost y más sin conversiones manuales ni reescrituras. Esto facilita a los equipos trabajar con diferentes tecnologías y estandarizar los procesos de producción.
¿Cuáles son algunas funciones de seguridad que debo buscar en estas herramientas?
Busca funciones como controles de acceso, endpoints encriptados, registros de auditoría y aislamiento de red. Estos aspectos aseguran que solo usuarios autorizados puedan desplegar o actualizar modelos, manteniendo seguros tanto los activos de modelos como las predicciones de datos.
¿Estas herramientas soportan inferencia tanto en tiempo real como por lotes?
Sí, las principales herramientas de despliegue de modelos de ML soportan tanto la predicción en tiempo real vía API como los modos por lotes. Esto otorga a tu equipo flexibilidad para abordar distintos casos de uso, desde aplicaciones de cara al usuario hasta grandes trabajos de puntuación offline.
¿Cómo ayudan estas herramientas con el monitoreo y mantenimiento de modelos?
Ofrecen tableros de monitoreo integrados, alertas, registros y detección automática de desvíos. Estas funciones permiten detectar degradaciones en el rendimiento, problemas con los datos o errores operativos a tiempo—muchas veces antes de que impacten al usuario final o los resultados del negocio.