DevOps-Metriken zur Messung des Erfolgs Ihrer Prozesse

Du hast also damit begonnen, DevOps in deinem Unternehmen einzuführen. Doch wie kannst du feststellen, ob es deine Prozesse tatsächlich verbessert? Du musst den Erfolg irgendwie messen – dies gelingt dir durch das Überwachen bestimmter wichtiger DevOps-Kennzahlen.
Es gibt viele Möglichkeiten, die Qualität eines Systems oder einer Anwendung zu bewerten, aber in diesem Artikel konzentriere ich mich auf wichtige Kennzahlen, die dabei helfen können, die Qualität deiner Prozesse zu beurteilen. Indem du diese Indikatoren verfolgst, gewinnst du tiefere Einsichten in Stärken und Schwächen, kannst deine DevOps-Best Practices verbessern und die passenden Tools und Softwarelösungen für kontinuierliche Verbesserung einsetzen.
Warum sind DevOps-Kennzahlen wichtig?
Wie oben beschrieben, können gemeinsame Ziele und Kennzahlen für Teams, die DevOps im Unternehmen einführen, herausfordernd sein. Ohne DevOps-Kennzahlen gäbe es kein Testen, kein Messen und keine Verbesserungen in der Entwicklung. Es wären bloß immer wiederkehrende Iterationen der gleichen Software auf Basis von Bauchgefühl und Ideen; man würde sie einfach ins Leere werfen und dann etwas Neues ausprobieren. Ohne Rückmeldungen oder Produkt-Erfolgsmetriken, um zu verstehen, wie etwas abschneidet, gibt es keine Orientierung.
Beispielsweise möchten Finanzabteilungen die Kosten so niedrig wie möglich halten, während Entwickler die Leistung möglichst hoch halten wollen. Diese beiden Zielsetzungen stimmen möglicherweise nicht überein, es sei denn, Risiken wurden bewertet und die Teams verstehen die jeweiligen Ziele.
Dort, wo deine Entwickler vielleicht lieber ein unfertiges Produkt ausliefern und sich später darum kümmern würden, verursacht diese Entscheidung technische Schulden. Die Einführung von DevOps kann Ziele und Strategien beider Teams aufeinander abstimmen und deinen Entwicklern dabei helfen, die Kostenauswirkungen ihrer technischen Entscheidungen zu verstehen.
Dies ist nur ein kleiner Teil von DevOps und der Bedeutung gemeinsamer Kennzahlen.
5 zentrale DevOps-Kennzahlen (DORA)
DevOps zu implementieren und prinzipienbasierte Frameworks zu verstehen ist das eine – aber bei den DevOps-Kennzahlen zeigt sich erst wirklich der Nutzen dieses kollaborativen Ansatzes im Softwareentwicklungszyklus. Wie bei den meisten Geschäftsstrategien gibt es unzählige Kennzahlen, die du je nach Branche, Zielgruppe und Zielsetzungen für das Wachstum messen könntest.
Die DevOps Research and Assessment (DORA)-Abteilung von Google Cloud ist das am längsten bestehende Forschungsteam in diesem Bereich. Sie haben ursprünglich vier Schlüsselkennzahlen identifiziert, mit denen die Performance der „Elite“ im DevOps gemessen wird. Inzwischen wurde jedoch eine fünfte wichtige Kennzahl aufgenommen, und ihre Clusteranalysen erkennen nur noch drei Level von DevOps-Teams: hoch, mittel und niedrig; das Niveau ‚Elite‘ gehört der Vergangenheit an.
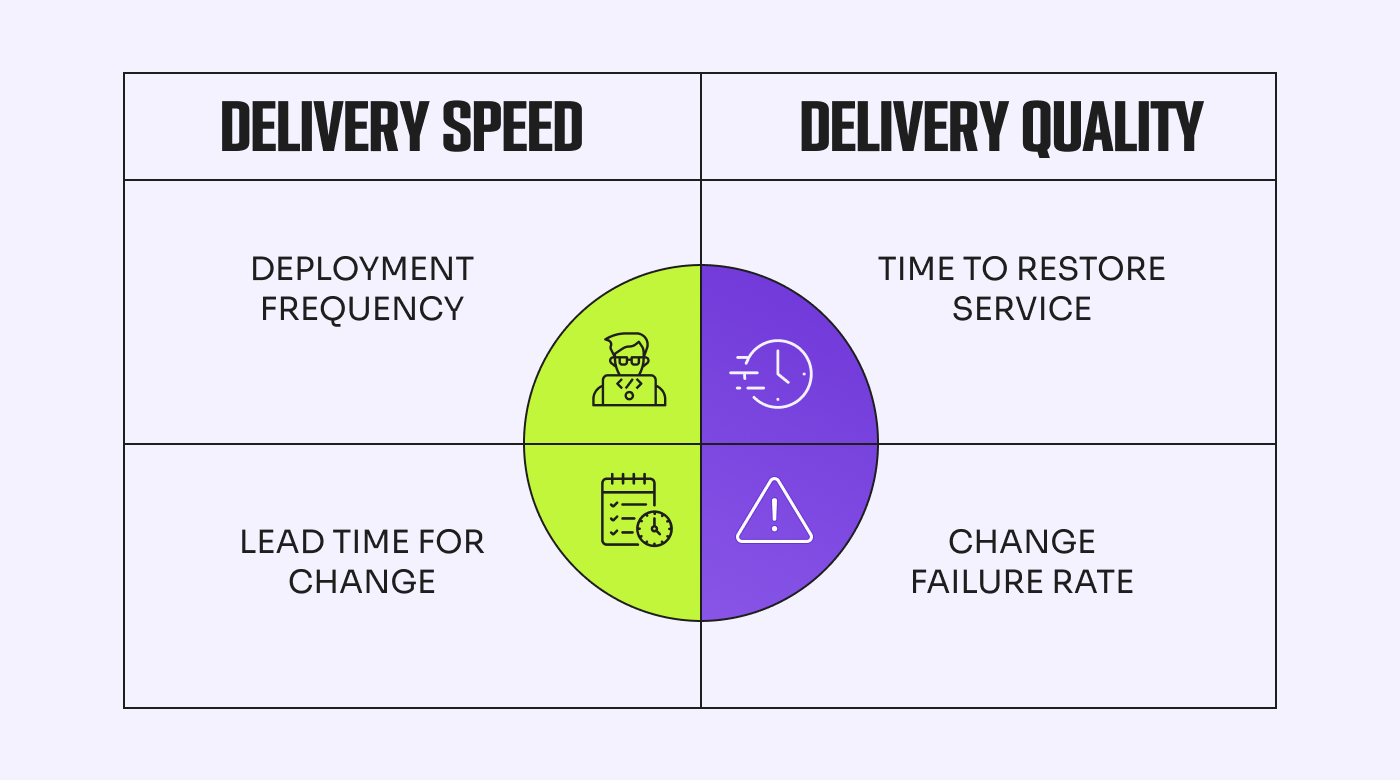
1. Deployment-Frequenz (DF)
DF misst, wie oft du erfolgreich in der Produktion veröffentlichst. Diese Kennzahl steht für Kontinuität und ist ein hervorragender Indikator für das Erreichen der Ziele.
Teams in der Kategorie „Elite“ veröffentlichten mehrmals täglich konsistent in der Produktivumgebung, während leistungsschwache Teams eher auf einmal alle sechs Monate kommen.
DF lässt sich ganz einfach verbessern, indem du mehrere kleinere Updates veröffentlichst. Der Hauptvorteil dabei ist, dass mögliche Prozessblocker, Engpässe oder komplexe Projekte, die Aufmerksamkeit erfordern, sichtbar werden. Größere Teams bevorzugen vielleicht regelmäßige Release-Intervalle, indem sie Agile Release Trains bilden; das kann dabei helfen, Überforderung durch zu hohes Tempo und viele Beteiligte zu vermeiden.
2. Durchlaufzeit für Änderungen (LTC)
LTC bezeichnet die Zeit, die ein Commit benötigt, um produktiv zu gehen. Diese Kennzahl ist ein guter Indikator für die Reaktionsfähigkeit und Agilität eines Teams, da sie zeigt, wie schnell auf Nutzerwünsche und Anforderungen reagiert werden kann.
Der frühere ‚Elite‘-Standard lag bei weniger als einem Tag für den LTC, während leistungsschwächere Teams dafür mehr als sechs Monate benötigen. Ein niedriger Wert bei LTC resultiert wahrscheinlich aus ineffizienten Prozessen.
Diese Kennzahl kannst du verbessern, indem du insbesondere den Automatisierungsprozess (vor allem das Testen) optimierst. Durch den Ausbau deiner Continuous-Integration- und Continuous-Delivery-(CI/CD-)Pipeline kannst du Updates schneller in die Produktion bringen. Allerdings besteht hier das Risiko, die Nachhaltigkeit aus den Augen zu verlieren. Wenn dein Team das gesteigerte Tempo nicht durchhalten kann, drohen schlechte Nutzererfahrungen und potenzielle Sicherheitslücken.
3. Änderungsfehlerquote (CFR)
Der CFR ist der Prozentsatz der Deployments, die zu einem Produktionsfehler führen. Ein Fehler kann dabei Ausfallzeiten, Rollbacks oder eine verschlechterte Dienstleistung bedeuten. Diese Kennzahl zeigt Ihnen, wie effektiv Ihr Team beim Ausrollen von Änderungen ist.
Elite-Performance-Benchmarks liegen bei 0–15 %; hohe, mittlere und niedrige Leistungen fallen alle unter 16–30 %.
Die Verbesserung des CFR liegt in der Qualität, nicht in der Quantität. Unternehmen veröffentlichen unterschiedlich viele Änderungen und haben daher auch unterschiedlich viele Fehlerfälle. Allerdings führen Änderungen von höchster Qualität zu weniger Fehlern, egal ob zweimal im Jahr oder zweimal täglich eingesetzt wird.
4. Mittlere Wiederherstellungszeit (MTTR)
Die MTTR misst, wie lange Ihr Team braucht, um einen Ausfall oder eine Störung zu beheben und den Service wiederherzustellen. Diese Kennzahl zeigt nicht nur die Agilität Ihres Teams, sondern ist auch ein guter Indikator für die Stabilität Ihrer Software.
Wenn Sie ein „Elite“-Niveau anstreben, sollten Sie sich auf unter einer Stunde MTTR konzentrieren. Wenig leistungsstarke Teams benötigen dafür über sechs Monate.
Sie können die MTTR verbessern, indem Sie sich auf kleinere, schnelle Releases konzentrieren, sodass sich Fehler leichter erkennen und beheben lassen. Ebenso könnten Sie Feature Flags einsetzen, um Ihrem Team mehr Kontrolle zu geben – insbesondere für experimentelle Features.
Eine Kennzahl bleibt noch übrig.
5. Zuverlässigkeit
Die Bonus-Kennzahl Nummer fünf ist Zuverlässigkeit. Diese Kennzahl wurde erst später vom DORA-Team (2021) eingeführt, da zuvor die Verfügbarkeit als Maßstab für zuverlässige Software herangezogen wurde. Es wurde jedoch beschlossen, dass Zuverlässigkeit die Aspekte Verfügbarkeit, Latenz, Performance und Skalierbarkeit besser umfasst. Im Wesentlichen ist so die operative Performance zusätzlich zur Entwicklungsleistung Teil der Messung.
Weitere gängige DevOps-Kennzahlen

Durchlaufzeit
Die Durchlaufzeit ist die gesamte Zeitspanne vom Start einer Aufgabe bis zur endgültigen Auslieferung. Auf den ersten Blick misst sie die Arbeitsgeschwindigkeit Ihres Teams. Sie können jedoch tiefer eintauchen, um Engpässe wie lange Wartezeiten in Warteschlangen oder umfangreiche Pull Requests zu entdecken.
Eine kürzere Durchlaufzeit zeigt einen effizienten Workflow an, verringert Engpässe und steigert die Entwicklungsgeschwindigkeit.
Wie wird die Durchlaufzeit gemessen?
Die Durchlaufzeit wird berechnet, indem Zeitstempel von Commits, Code-Merges und Deployments mit Tools wie GitHub, GitLab oder Jenkins verfolgt werden.
Durchlaufzeit = Deployment-Zeitpunkt - Commit-Zeitpunkt
Um die Durchlaufzeit zu verbessern, sollten Teams:
- CI/CD-Pipelines für eine schnellere Integration und Bereitstellung optimieren.
- Builds und Tests automatisieren.
- Die Zusammenarbeit zwischen Entwicklungs- und Betriebsteams verbessern.
- Abhängigkeiten zwischen Aufgaben reduzieren, um Engpässe zu minimieren.
Mean Time to Detection (MTTD)
Dies ist die durchschnittliche Zeit, die Ihr Team benötigt, um einen Fehler zu erkennen. Ein niedriger MTTD weist auf ein effizientes Monitoring- und Alarmsystem hin, das eine schnelle Reaktion und Lösung von Vorfällen ermöglicht.
Wie wird der MTTD gemessen?
Der MTTD kann berechnet werden, indem die durchschnittliche Zeit zwischen dem Auftreten eines Problems und dessen Erkennung durch Monitoring-Tools oder gemeldete Störungen ermittelt wird. Zur Senkung des MTTD sollten automatisierte Überwachung, gezieltere Alarmierung und proaktive Fehleridentifizierung verbessert werden.
Bestandene automatisierte Tests
Es lohnt sich, auf eine gute Testabdeckung hinzuarbeiten, insbesondere bei automatisierten Tests. Gemeint sind hier Unit-, Integrations-, UI- und End-to-End-Tests. Allerdings reicht eine gute Abdeckung allein nicht aus, um Softwarequalität sicherzustellen. Entscheidend ist der Prozentsatz der bestandenen Tests.
Ziel ist es natürlich, einen möglichst hohen Prozentsatz bestandener Tests – so nah wie möglich an 100 % – zu erreichen. Das Monitoring dieser Kennzahl zeigt auch, wie oft neue Entwicklungen bestehende Tests fehlschlagen lassen.
Wie wird der Prozentsatz bestandener automatisierter Tests gemessen?
Die Berechnung ist eine einfache Prozentrechnung: Die Anzahl der bestandenen Tests wird mit 100 multipliziert und dann durch die Gesamtzahl der Tests geteilt. Diese Information kann dem Pipeline-Tool entnommen werden, das die Builds ausführt (Jenkins, Azure DevOps, CircleCI usw.).
Die Zahl kann ein guter Indikator für die Qualität des Produkts sein. Sie kann jedoch auch irreführend sein, wenn Sie instabile oder unzuverlässige Tests haben.
Felddefektrate
Die Felddefektrate (Defect Escape Rate) beschreibt, wie viele Fehler während der Tests übersehen und in die Produktion übertragen werden – also wie viele „entkommen“. Diese Kennzahl eignet sich ideal zur Überwachung, wenn Sie die Test- und Automatisierungsprozesse verbessern möchten.
In einer utopischen Welt wären all unsere Anwendungen fehlerfrei. In der Realität ist das jedoch selten der Fall. Idealerweise werden Defekte in den Entwicklungs- und Testphasen des DevOps-Prozesses entdeckt – und nicht erst in der Produktion.
Diese Kennzahl hilft, die Effektivität Ihrer Testprozesse sowie die Gesamtqualität Ihres Programms zu bestimmen. Eine hohe Felddefektrate weist darauf hin, dass Abläufe verbessert und mehr Automatisierung eingesetzt werden sollte, während eine niedrige Rate (idealerweise nahe Null) auf eine hochwertige Anwendung hinweist.
Wie wird die Felddefektrate gemessen?
Dazu können Sie Ihr Fehlerverfolgungstool verwenden und für jeden offenen Defekt erfassen, wo er entdeckt wurde – ob in der Test- oder Produktionsumgebung (oder in einer anderen Umgebung wie etwa UAT), die Sie verwenden.
Kundentickets
Kundenzufriedenheit ist ein maßgeblicher Innovationstreiber – und das aus gutem Grund: Eine makellose Benutzererfahrung ist guter Kundenservice und geht in der Regel mit einer Umsatzsteigerung einher. Somit sind Kundentickets, insbesondere während des Ticket-Eskalationsprozesses, ein guter Indikator dafür, wie erfolgreich Ihre DevOps-Umstellung verläuft.
Kunden sollten nicht als Qualitätskontrolle fungieren, indem sie Fehler und Bugs melden. Eine Abnahme der Kundentickets ist daher ein gutes Zeichen für eine funktionierende Anwendung.
CPU- und Speichernutzung
Erkennt Trends in der Ressourcenauslastung.
Antwortzeit
Misst die Zeit, die die Anwendung benötigt, um auf Anfragen zu reagieren.
Fehlerrate
Erfasst die Anzahl fehlgeschlagener Anfragen im Zeitverlauf.
Durchsatz
Misst die Anzahl der verarbeiteten Anfragen pro Sekunde.
Latenz von API-Anfragen
Misst die Verzögerung zwischen dem Senden einer Anfrage und dem Erhalt einer Antwort.
Datenbankabfrage-Performance
Zeichnet Ausführungszeiten von Abfragen und mögliche Engpässe auf.
Analyse des Nutzerverhaltens
Überwacht die Nutzung und Akzeptanz von Funktionen sowie Interaktionstrends.
Mean Time Between Failures (MTBF)
MTBF misst die durchschnittliche Zeitspanne zwischen Systemausfällen, Ausfallzeiten oder Vorfällen. Diese Kennzahl bewertet die Zuverlässigkeit und Stabilität Ihrer Softwaresysteme und verdeutlicht die Wirksamkeit Ihrer präventiven Wartung und Fehlervermeidungsstrategien.
Time to Mitigate (TTM)
Die Zeitspanne, die für die Behebung eines erkannten Problems benötigt wird, ist das TTM. Diese Kennzahl hilft, die Prozesse für Vorfallreaktion und -lösung zu bewerten und zeigt, wie effizient Ihre Teams bei der Problemlösung und Wiederherstellung agieren.
Change Lead Time (CLT)
CLT liefert einen Maßstab für den gesamten Umsetzungsprozess von Veränderungen, einschließlich Entwicklung, Tests, Review und Bereitstellung. Ein kürzerer CLT steht für schnellere Auslieferungszyklen und höhere Agilität.
So setzen Sie KPIs mit DevOps-Kennzahlen
Nachdem Sie nun einen guten Überblick über die Kennzahlen zur Implementierung und Optimierung von DevOps in Ihrem Unternehmen haben, sollten Sie sich mit Schlüsselkennzahlen (KPIs) beschäftigen, um Ziele und Benchmarks für Ihr Team zu setzen.
Kennzahlen vs. KPIs
Vielleicht fragen Sie sich, was der Unterschied zwischen Kennzahlen und KPIs ist. Eine Kennzahl ist was Sie messen. Es ist eine quantifizierbare Größe, die Daten über einen bestimmten Leistungsaspekt liefert. Nicht alle Kennzahlen sind zwangsläufig mit Zielen oder Vorgaben verknüpft.
KPIs hingegen sind eine Form von Kennzahlen, die strategisch ausgewählt und definiert werden, um die wichtigsten Leistungsaspekte und den Fortschritt in Richtung strategischer Ziele widerzuspiegeln. KPIs sind in der Regel mit Zielen verbunden und haben oft spezifische Zielwerte, Schwellen oder Benchmarks, die erreicht werden müssen.
KPIs für Ihr DevOps-Team festlegen
Der erste Schritt bei der Festlegung von KPIs für Ihr DevOps-Team besteht darin, DevOps-Kennzahlen mit Ihrer Geschäftsstrategie und Ihren Zielen zu verknüpfen. Indem Sie die wichtigsten Metriken priorisieren, die Sie verfolgen sollten, können Sie beginnen, Zielsetzungen und Benchmarks für kontinuierliche Verbesserung zu definieren. Die Auswahl der richtigen Kennzahlen erfordert die Berücksichtigung von Unternehmensgröße, Produkt und Markt. Konzentrieren Sie sich darauf, was die umsetzbarsten Erkenntnisse bringt, und vermeiden Sie die häufige Falle einer Überflutung durch zu viele Kennzahlen.
Die Überwachung Ihrer KPIs ist genauso wichtig wie deren Festlegung. Entdecken Sie Datenvisualisierungstools, um Ihrem Team Echtzeitdaten auf intuitiven Dashboards bereitzustellen. Das gewährleistet vollständige Transparenz, sorgt für Verantwortlichkeit und ermöglicht es allen, gemeinsam an gemeinsamen Zielen zu arbeiten. So werden Entwicklungs- und Betriebsteams aufeinander abgestimmt, was die Einführung und Weiterentwicklung von DevOps unterstützt.

Anhand der DORA-Kernmetriken sehen wir die Benchmarks für jede Kennzahl, basierend auf Elite-, High-, Medium- und Low-Performing-Teams. Diese Tabelle kann Ihnen helfen, KPIs für Ihr eigenes Unternehmen festzulegen – je nachdem, welche Prioritäten Sie setzen.
Bei der Festlegung Ihrer KPIs sollten Sie Ihr Team und Ihr Unternehmen genau betrachten und keine Vergleiche mit anderen Unternehmen ziehen. Wenn wir beispielsweise den CFR betrachten, ist der Benchmark für High-, Medium- und Low-Performance identisch. Dies hängt stark von Ihrer Bereitstellungshäufigkeit ab, kann aber auch umgekehrt wirken. Wenn Ihr Team seine gesamte Zeit mit der Behebung von Fehlern verbringt, bleibt weniger Zeit für die Entwicklung und das Ausrollen von Updates. Die KPIs können sich zudem mit der Reife Ihres DevOps-Teams verändern. Ausgereifte Automatisierungs- und Testprozesse sollten es ermöglichen, die Hürden für Ihre Zielvorgaben automatisch anzuheben.
Wie Sie DevOps-Metriken für die Skalierung nutzen
Mit einem erwarteten globalen DevOps-Marktvolumen von 24,71 Milliarden Dollar bis 2027 (bei einer durchschnittlichen jährlichen Wachstumsrate von 22,9 % auf Grundlage einer Marktgröße von 10,84 Milliarden Dollar im Jahr 2023) ist jetzt der ideale Zeitpunkt, DevOps in Ihrem Unternehmen einzuführen.
DevOps beschleunigt nicht nur die Entwicklung und verkürzt die Markteinführungszeit, sondern verbessert auch die Zusammenarbeit, indem Silos aufgelöst werden. Zudem steigert es die Qualität durch kontinuierliche Tests und Feedbackschleifen und sorgt für eine effiziente Ressourcennutzung, was Kosten spart. Schließlich ist es problemlos skalierbar und unterstützt das Unternehmenswachstum bis an neue Grenzen – 83 % der IT-Entscheidungsträger konnten 2021 durch die Implementierung von DevOps einen höheren Geschäftswert realisieren.
Leistungsmessung und kontinuierliche Verbesserung
Die Überwachung der Performance ist entscheidend für das Wachstum eines Unternehmens, das DevOps anwendet. Es handelt sich um einen schnellen Ansatz mit ständigem Produktionsfluss; daher sollten Messungen und Berichte ebenso häufig erfolgen. Mit DevOps-Kennzahlen können Sie die Performance Ihrer Entwicklungs- und Bereitstellungsprozesse verfolgen. Durch die Quantifizierung von Schlüsselfaktoren wie Bereitstellungshäufigkeit, Durchlaufzeit und Änderungsausfallrate können Engpässe, Ineffizienzen und Verbesserungsbereiche identifiziert werden. So lassen sich Workflows und Prozesse regelmäßig optimieren.
Das Verfolgen von Kennzahlen wie Änderungsausfallrate und mittlere Wiederherstellungszeit hilft Ihnen, Trends frühzeitig zu erkennen. Dieser proaktive Ansatz ermöglicht es, korrigierende Maßnahmen zu ergreifen und die Auswirkungen auf die Kunden zu minimieren – was Zuverlässigkeit bedeutet, ein weiteres wesentliches Element für Skalierung mit hoher Qualität.
Letztlich helfen Ihnen DevOps-Kennzahlen dabei, Ihr DevOps-Team weiterzuentwickeln, indem sie eine Kultur der kontinuierlichen Verbesserung fördern. Feedbackschleifen unterstützen Lernen und Wachstum – es sollte stets Raum für Experimente mit unterschiedlichen Herangehensweisen geben.
Welche DevOps-Kennzahlen unterstützen das Unternehmenswachstum?
Bei der Festlegung von KPIs sollten die meisten Kennzahlen für Ihr eigenes Team im Hinblick auf Wachstum betrachtet und nicht mit anderen Unternehmen oder Teams mit anderem Reifegrad verglichen werden.
Ein niedriger LTC beispielsweise kann zeigen, dass Ihr Team effizient arbeitet. Ist das Tempo aber nicht nachhaltig, kann dies langfristig die Nutzererfahrung beeinträchtigen. Diese Kennzahl sollte über einen längeren Zeitraum beobachtet werden, statt einen KPI zu setzen, der einem leistungsstarken oder gar Elite-DevOps-Team entspricht. Die Vorgabe, das LTC monatlich, viertel- oder jährlich zu senken, zeigt Wachstum innerhalb Ihres Teams und Ihres Unternehmens.
CFR ist eine wertvolle Kennzahl, denn nicht jeder hat die gleiche Anzahl an Ausfällen oder Problemen. Indem man jedoch einen Prozentsatz angibt, kann man messen, wie erfolgreich die eigenen Deployments sind. Ihr Team hat vielleicht nur wenige Ausfälle, wenn Veränderungen selten eingespielt werden, aber wenn jede Veröffentlichung zu einem Problem führt, wird der CFR sehr hoch sein. Wenn Sie CI/CD-Praktiken befolgen, sehen Sie womöglich mehr Ausfälle, aber wenn Ihr CFR gering ist, haben Sie einen Vorteil, weil Ihnen Geschwindigkeit und Qualität beim Wachstum helfen. MTTR sollte ebenfalls über die Zeit hinweg gemessen werden, um ein kontinuierliches Wachstum sicherzustellen.
DORA fand heraus, dass Teams aller Entwicklungsleistungsstufen bessere Ergebnisse erzielten, wenn sie sich auf die operative Leistung konzentrierten. Dies könnte bedeuten, KPIs für Incident-Berichte oder offene Tickets, Anwendungsbetriebszeit und Verfügbarkeit zu setzen.
Eine hohe Anzahl offener Tickets könnte auf ein Problem mit Ihrer Kundenzufriedenheit hindeuten, aber das Streben nach einer Verringerung im Zeitverlauf spiegelt das Wachstum in diesem Bereich wider. Sie könnten weiter ins Detail gehen und Reaktions- sowie Wartezeiten messen, um die Verbesserung dieser Kennzahl zu beschleunigen.
Die eine Kennzahl, die Entwicklung und Betrieb vollständig als DevOps-Team vereint, ist die Durchlaufzeit. Dies eröffnet die Möglichkeit, eine Kultur des Feedbacks und Wachstums zu etablieren. Wenn sich andere Kennzahlen bessern und die Automatisierung voranschreitet, sollten Sie eine Verkürzung der Durchlaufzeit erwarten. Wenn Ihr Kundenservice hervorragend und die Entwicklungsfehler gering sind, haben Sie die perfekte Kombination gefunden, um Ihr Unternehmen zu skalieren.
Fazit
Wie jede andere Methodik ist auch DevOps nur dann erfolgreich, wenn es richtig umgesetzt wird. Und Sie können den Erfolg nicht erkennen, solange Sie nicht wissen, wie man DevOps-Kennzahlen nutzt.
Natürlich bringt das Implementieren von DevOps-Kennzahlen Herausforderungen mit sich. Es erfordert eine strategische Denkweise, eine kollaborative Kultur und die Verpflichtung zu kontinuierlicher Verbesserung. Die Ergebnisse sind jedoch optimierte Workflows und Prozesse, auf denen Sie eine solide Grundlage für das Wachstum Ihres Unternehmens aufbauen können.
Wenn Sie über Neuigkeiten und Artikel auf dem Laufenden bleiben möchten, abonnieren Sie unseren Newsletter!



{kind=link}