Leadership nei Test: Test dei Servizi

Nota dell'editore: Benvenutə alla serie Leadership in Test, dal guru e consulente del software testing Paul Gerrard. Questa serie è pensata per aiutare tester con qualche anno di esperienza — in particolare chi lavora in team agile — a eccellere nei propri ruoli di team lead e manager dei test.
Nell'articolo precedente, abbiamo esaminato il ruolo in evoluzione dei tester e come promuovere una migliore collaborazione con i colleghi. In questo articolo, entreremo nel dettaglio di come testare le prestazioni, l'affidabilità e la gestibilità di un'applicazione web. In altre parole, il service testing.
Iscriviti alla newsletter di The QA Lead per essere avvisatə quando saranno pubblicate le nuove parti della serie. Questi post sono estratti dal corso Leadership in Test di Paul che consigliamo vivamente per approfondire questo e altri argomenti. Se ti interessa, usa il nostro codice sconto esclusivo QALEADOFFER per risparmiare $60 sul prezzo intero del corso!
Ciao e benvenutə a un altro capitolo della serie Leadership in Test. Questa settimana ci occupiamo di service testing per applicazioni web. Tratteremo:
- Cos'è il Service Testing?
- Cos'è il Performance Testing?
- Test di affidabilità/Failover
- Testing della Gestione del Servizio
Cominciamo.
Cos'è il Service Testing?
La qualità del servizio che un'applicazione web fornisce può essere definita includendo tutte le sue caratteristiche quali funzionalità, prestazioni, affidabilità, usabilità, sicurezza e così via.
Tuttavia, ai nostri fini qui, distinguiamo tre obiettivi particolari del servizio che rientrano nell'ambito di ciò che chiameremo “service testing”. Questi obiettivi sono:
- Prestazioni: il servizio deve essere reattivo agli utenti mentre supporta i carichi che gli vengono imposti.
- Affidabilità: se progettato per essere resiliente ai guasti, il servizio deve essere affidabile e/o continuare a funzionare anche quando si verifica un guasto.
- Gestibilità: il servizio deve poter essere gestito, configurato o modificato senza che si noti un degrado del servizio da parte degli utenti finali. La gestibilità, o service operations testing, mira a dimostrare che le procedure amministrative, gestionali, di backup e di ripristino del sistema funzionano efficacemente.
In tutti e tre i casi, è necessario simulare un carico utente per condurre efficacemente i test. Gli obiettivi di prestazioni, affidabilità e gestibilità esistono nel contesto di clienti reali che utilizzano il sito per fare business.
La reattività (in questo caso, il tempo che impiega un nodo del sistema a rispondere alla richiesta di un altro) di un sito è direttamente correlata alle risorse disponibili all'interno dell'architettura tecnica.
Man mano che più clienti utilizzano il servizio, meno risorse tecniche sono disponibili per servire le richieste di ogni utente e i tempi di risposta peggiorano.
Ovviamente, un servizio poco caricato è meno soggetto a guasti. Gran parte della complessità del software e dell'hardware esiste proprio per gestire la domanda di risorse all'interno dell'architettura tecnica quando un sito è fortemente caricato.
Quando un sito è sotto carico (o sovraccarico), le richieste concorrenti di risorse devono essere gestite da vari componenti dell'infrastruttura come sistemi operativi server e di rete, sistemi di gestione dei database, web server, object request broker, middleware e così via.
Questi componenti infrastrutturali sono di solito più affidabili rispetto al codice applicativo personalizzato che ne richiede le risorse, ma i guasti possono verificarsi su entrambi i fronti:
- I componenti dell'infrastruttura falliscono perché il codice applicativo (a causa di design o implementazione scadente) richiede un uso eccessivo di risorse.
- I componenti applicativi potrebbero fallire perché le risorse di cui necessitano potrebbero non essere sempre disponibili (in tempo).
Simulando carichi di produzione tipici e insoliti per un periodo prolungato, i tester possono evidenziare difetti nel design o nella realizzazione del sistema. Una volta risolti questi difetti, gli stessi test dimostreranno la resilienza del sistema. I QA possono sfruttare gli strumenti di load testing per eseguire molti dei processi definiti qui sotto.
Su tutti i servizi, solitamente vi sono diversi processi di gestione critici che devono essere eseguiti per mantenere il servizio fluido. Potrebbe essere possibile sospendere un servizio per la manutenzione ordinaria fuori dall'orario lavorativo, ma la maggior parte dei servizi online opera 24 ore su 24.
La giornata lavorativa del servizio non finisce mai. Inevitabilmente, le procedure di gestione devono essere effettuate mentre il servizio è attivo e gli utenti sono sul sistema. Queste procedure devono essere testate mentre c'è carico sul sistema, per assicurarsi che non abbiano impatti negativi sul servizio in produzione ovvero sul performance testing.

Che cos'è il Performance Testing?
Il performance testing è un componente fondamentale del test dei servizi. Si tratta di una modalità di verifica del comportamento di un sistema in termini di reattività e stabilità sotto un certo carico di lavoro. Ecco una panoramica di come funziona:
- Il performance testing consiste in una serie di test a carichi variabili, in cui il sistema raggiunge uno stato stabile (carichi e tempi di risposta su livelli costanti).
- Misuriamo il carico e i tempi di risposta per ciascun carico, simulato per un periodo di 15-30 minuti, per ottenere un numero statisticamente significativo di misurazioni.
- Monitoriamo e registriamo i segnali vitali per ogni carico simulato. Questi sono le varie risorse nel nostro sistema, ad esempio utilizzo della CPU e della memoria, banda di rete, tassi di I/O ecc.
Tracciamo un grafico di questi carichi variabili rispetto ai tempi di risposta sperimentati dai nostri "utenti virtuali". Una volta elaborato, il grafico apparirà simile a quello riportato qui sotto.
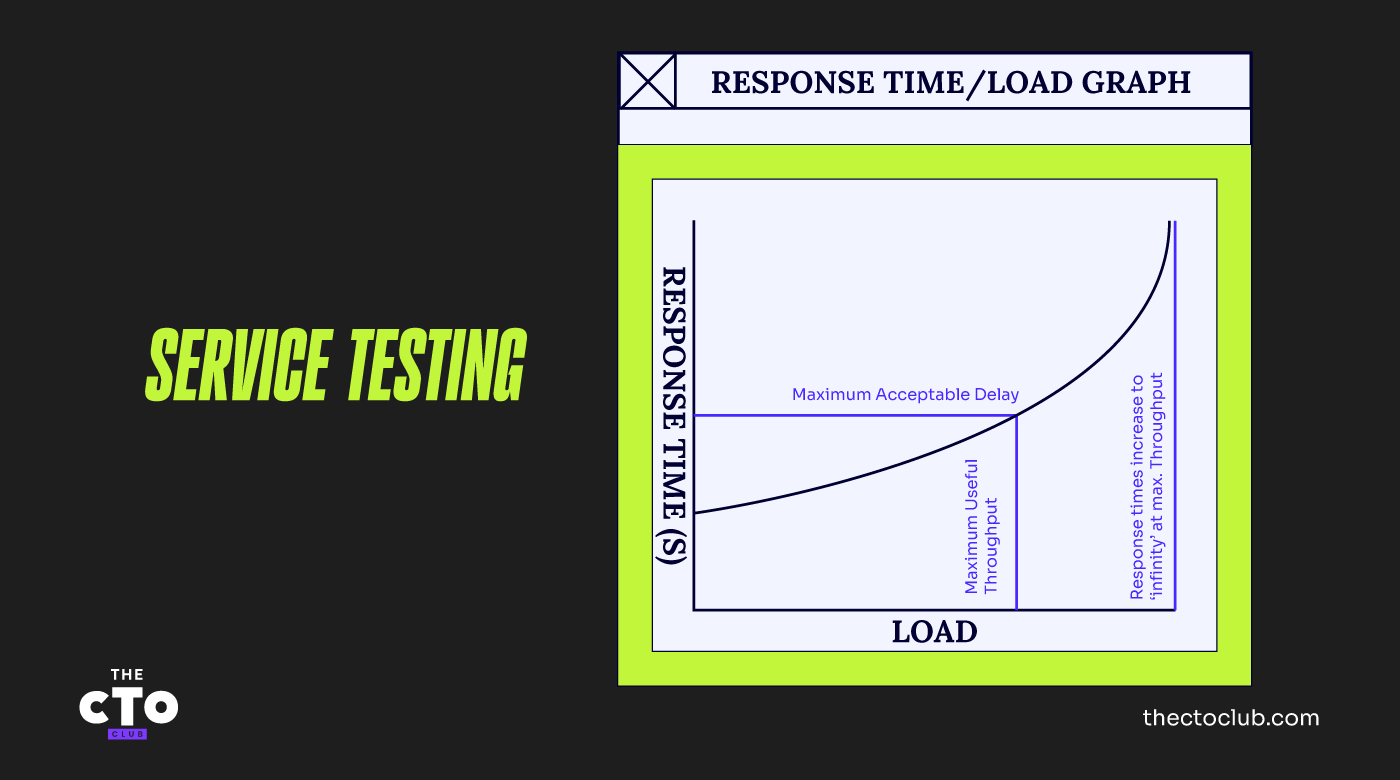
A carico zero, quando c'è solo un utente nel sistema, questi ha a disposizione tutte le risorse e i tempi di risposta sono rapidi. Man mano che introduciamo carichi crescenti e misuriamo i tempi di risposta, questi peggiorano progressivamente fino a raggiungere un punto in cui il sistema opera alla massima capacità.
In questo punto, il tempo di risposta per le nostre transazioni di test è teoricamente infinito perché una delle risorse chiave del sistema è completamente esaurita e non è più possibile processare altre transazioni.
All'aumentare dei carichi da zero fino al massimo, monitoriamo anche l'utilizzo dei diversi tipi di risorse, ad esempio utilizzo del processore del server, utilizzo della memoria, banda di rete, lock del database e così via.
Al carico massimo, una di queste risorse è sfruttata al 100%. Questa risorsa rappresenta il collo di bottiglia, poiché si esaurisce per prima. Ovviamente, a questo punto, i tempi di risposta sono peggiorati a tal punto da risultare probabilmente molto più lenti di quanto sia accettabile.
Il grafico qui sotto mostra l’uso/disponibilità di diverse risorse rispetto al carico.

Per aumentare la capacità di throughput e/o ridurre i tempi di risposta di un sistema bisogna adottare una o più delle seguenti strategie:
- Ridurre la domanda per la risorsa, tipicamente rendendo più efficiente il software che la utilizza (questa è solitamente una responsabilità dello sviluppo).
- Ottimizzare l’uso della risorsa hardware all’interno dell’architettura tecnica, ad esempio configurando il DBMS per memorizzare più dati in memoria o dando priorità a determinati processi sull’application server rispetto ad altri.
- Rendere disponibile una maggiore quantità della risorsa. Normalmente aggiungendo processori, memoria o banda di rete e così via.
Come avrai già capito, il performance testing richiede il supporto di un team di persone che assistano i tester. Si tratta di architetti tecnici, amministratori di server, amministratori di rete, sviluppatori e progettisti/amministratori di database. Questi esperti tecnici sono qualificati per analizzare le statistiche generate dagli strumenti di monitoraggio delle risorse e valutare il modo migliore per intervenire sull’applicazione, oppure per effettuare ottimizzazioni e aggiornamenti del sistema.
Se sei il tester, a meno che tu stesso non sia un esperto in questi ambiti, non cedere alla tentazione di fingere di poter interpretare queste statistiche e prendere decisioni di tuning e ottimizzazione. Sarà necessario coinvolgere questi specialisti fin dalle prime fasi del progetto per ricevere i loro consigli e ottenere il loro appoggio e, successivamente, durante i test, per garantire che eventuali colli di bottiglia vengano identificati e risolti.
Non perdere il prossimo articolo in cui approfondiremo come gestire il performance testing.
Test di Affidabilità/Failover
Garantire la disponibilità continua di un servizio è probabilmente un obiettivo chiave del tuo progetto. Il test di affidabilità aiuta a scoprire guasti nascosti che causano errori imprevisti. Il test di failover aiuta a verificare che le misure di failover progettate per guasti previsti funzionino realmente.
Test di Failover
Dove è richiesta resilienza e/o affidabilità, i siti tendono a essere progettati con componenti di sistema affidabili, provvisti di funzionalità di ridondanza e failover integrate che si attivano in caso di guasti.
Queste feature possono includere un instradamento di rete diversificato, server multipli configurati in cluster, middleware e tecnologie di servizio distribuito che gestiscono il load balancing e la re-instradazione del traffico in scenari di guasto.
Il test di failover mira a esplorare il comportamento del sistema in determinati scenari di guasto, prima del rilascio, e in genere prevede le seguenti attività:
- Identificazione dei componenti che potrebbero guastarsi e causare una perdita di servizio (analizzando i guasti dall’interno verso l’esterno).
- Identificazione dei pericoli che potrebbero causare un guasto e provocare una perdita di servizio (analizzando le minacce dall’esterno verso l’interno).
- Un’analisi delle modalità di guasto o degli scenari che potrebbero verificarsi nei casi in cui serve la certezza che la misura di recupero funzionerà.
- Un test automatico che può essere utilizzato per caricare il sistema ed esplorare il comportamento del sistema per un periodo prolungato.
- Lo stesso test automatico può essere usato anche per caricare il sistema in prova e monitorare il comportamento del sistema in condizioni di guasto.
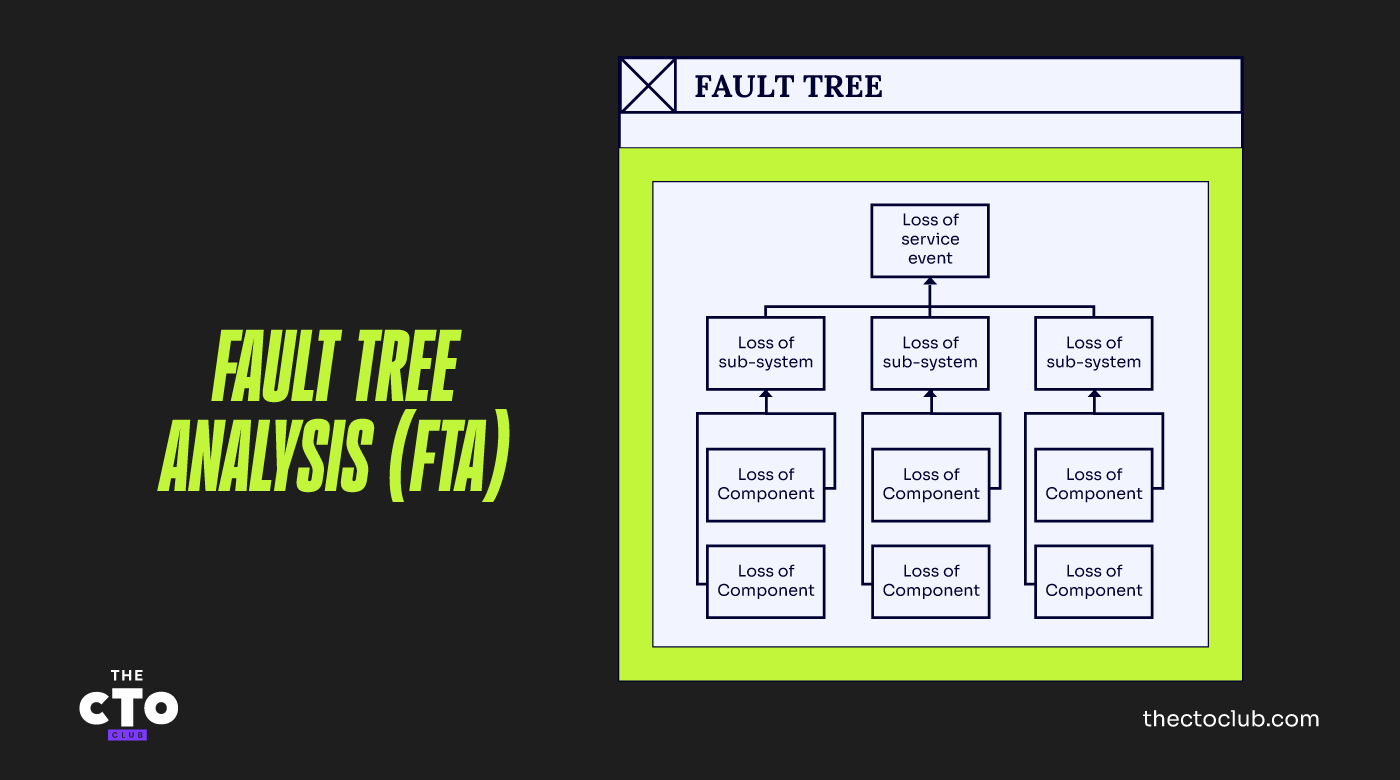
Una tecnica chiamata Fault Tree Analysis (FTA) può aiutarti a comprendere le dipendenze di un servizio dai suoi componenti sottostanti. L'analisi ad albero dei guasti e i diagrammi ad albero dei guasti sono una rappresentazione logica di un sistema o servizio e dei modi in cui questo può andare in errore.
Il semplice schema qui sotto mostra la relazione tra eventi di guasto di componenti di base, eventi di guasto di sottosistemi intermedi e il massimo evento di guasto a livello di servizio. Naturalmente, potrebbe essere possibile identificare più di tre livelli di eventi di guasto.
Questi test devono essere eseguiti con un carico automatico per esplorare il comportamento del sistema in situazioni di produzione e acquisire fiducia nelle misure di recupero progettate. In particolare, è importante sapere:
- Come si comporta l’architettura in situazioni di guasto?
- Le soluzioni di bilanciamento del carico funzionano correttamente?
- Le funzionalità di failover riescono ad assorbire il carico quando un componente va in errore?
- Il recupero automatico funziona? I sistemi riavviati riescono a “recuperare”?
In definitiva, i test si concentrano sul determinare se il servizio agli utenti finali viene mantenuto e se gli utenti si accorgono effettivamente che si sta verificando un guasto.
Test di affidabilità (o soak)
I test di affidabilità mirano a verificare che non si verifichino guasti sotto carico.
La maggior parte dei componenti hardware è affidabile al punto che il tempo medio tra i guasti può essere misurato in anni. I test di affidabilità richiedono l’uso (o il riuso) di test automatici in due modi per simulare:
- Carichi estremi su specifici componenti o risorse nell’architettura tecnica.
- Lunghi periodi di carico normale (o estremo) sull’intero sistema.
Quando ci si concentra su componenti specifici, si mira a stressare il componente sottoponendolo a un numero irragionevolmente elevato di richieste per svolgere la sua funzione prevista. Spesso è più semplice testare in modo intensivo i componenti critici isolatamente con un gran numero di richieste semplici prima di effettuare test più complessi su tutta l’infrastruttura. Esistono anche strumenti progettati appositamente per lo stress testing che rendono il processo più semplice per i QA.
I soak test sono test che sottopongono un sistema a un carico per un periodo prolungato, ad esempio 24, 48 ore o più, al fine di individuare problemi (che spesso sono) oscuri. I difetti nascosti spesso si manifestano solo dopo un uso prolungato.
Il test automatico non deve necessariamente essere portato a carichi estremi (questa casistica è già coperta dallo stress testing). Ma ci interessa in particolare la capacità del sistema di resistere all’esecuzione continua di un’ampia varietà di transazioni di test per individuare eventuali perdite di memoria, blocchi o condizioni di race.
Test di Service Management
Infine, una considerazione sui test di service management.
Quando il servizio viene distribuito in produzione, deve essere gestito. Mantenere un servizio attivo richiede che venga monitorato, aggiornato, sottoposto a backup e che venga rapidamente ripristinato in caso di problemi.
Le procedure che i service manager utilizzano per eseguire aggiornamenti, backup, release e ripristino da situazioni di guasto sono fondamentali per offrire un servizio affidabile e quindi devono essere testate, soprattutto se il servizio subirà rapidi cambiamenti dopo l’avvio.
I problemi specifici da affrontare sono:
- Le procedure non raggiungono l’effetto desiderato.
- Le procedure sono impraticabili o inutilizzabili.
- Le procedure interrompono il servizio in produzione.
I test dovrebbero, per quanto possibile, essere eseguiti nel modo più realistico possibile.
Qualche spunto di riflessione
Alcuni sistemi sono soggetti a carichi estremi quando si verifica un determinato evento. Ad esempio, un’azienda online si aspetta carichi di picco subito dopo aver pubblicizzato offerte in TV, oppure un sito web di notizie nazionale potrebbe essere sovraccaricato quando si diffonde una notizia di grande rilievo.
Pensa a un sistema che conosci bene e che è stato colpito da incidenti imprevisti nella tua azienda o nelle notizie nazionali.
Quali incidenti o eventi potrebbero causare carichi eccessivi nel tuo sistema?
Puoi (o potresti) raccogliere dati dai log di sistema che ti forniscano il numero di transazioni eseguite? Riesci a scalare questo evento per prevedere un evento critico che si verifichi una volta ogni 100 anni, o una volta ogni 1000 anni?
Quali misure potresti applicare (o hai già applicato) per ridurre la probabilità di picchi, l'entità dei picchi o eliminarli del tutto?
Iscriviti alla newsletter di The QA Lead per essere avvisato quando saranno pubblicate nuove parti della serie. Questi post sono estratti dal corso Leadership In Test di Paul che consigliamo vivamente per approfondire questo e altri argomenti. Se decidi di iscriverti, usa il nostro codice coupon esclusivo QALEADOFFER per ottenere $60 di sconto sul prezzo completo del corso!
Lettura consigliata: 10 MIGLIORI STRUMENTI OPEN SOURCE PER LA GESTIONE DEI TEST

{kind=link}