3 Metriche di Monitoraggio del Server da Tenere Sotto Controllo per la Salute del Sistema

L'assicurazione della qualità richiede una combinazione di misure proattive e protocolli reattivi efficienti. Con il giusto equilibrio, puoi offrire agli utenti un servizio eccellente e funzionalità su un server disponibile tutto l'anno. L'unico modo per raggiungere questo equilibrio è identificare le metriche di monitoraggio del server più rilevanti.
Ma quali potrebbero essere queste metriche? Dipende dagli attributi desiderati, inclusi quelli delineati nel Modello di Maturità della Qualità, e dagli obiettivi di monitoraggio. Tuttavia, ci sono alcune metriche di salute e prestazioni che gli ingegneri QA dovrebbero sempre monitorare, indipendentemente da tutto.
Scegliendo fin dall'inizio le metriche ideali di monitoraggio del server, puoi sviluppare una baseline delle prestazioni da utilizzare come riferimento quando inevitabilmente sorgono problemi di salute e prestazioni.
In questa breve guida, analizzeremo perché dovresti tracciare queste metriche chiave. Inoltre, otterrai ulteriori approfondimenti sulla loro rilevanza e su come monitorarle.
1. Utilizzo della CPU
Una delle principali motivazioni per il monitoraggio dei server è tenere d'occhio la salute dell'infrastruttura e le prestazioni di base del server. Una parte fondamentale di ciò è la diagnosi proattiva e la mitigazione di possibili problemi di prestazioni. La misurazione dell'utilizzo di CPU e disco è centrale per questi sforzi. Per questo motivo, l'utilizzo della CPU è una delle metriche di prestazione più fondamentali e comunemente monitorate.
Questa metrica è considerata "basata sull'host", poiché tiene traccia della capacità di una singola macchina di operare e rimanere stabile. Detto ciò, il monitoraggio dell'utilizzo della CPU comporta una combinazione di monitoraggio passivo e attivo. Quest’ultimo è particolarmente utile per i test di carico controllati, mentre il primo raccoglie misurazioni sul target durante il traffico reale.
Come misurare l'utilizzo della CPU
Prima di iniziare, dovrai:
- Selezionare i drive specifici che vuoi monitorare.
- Determinare dove si trovano questi drive.
- Assicurarti che il tuo raccoglitore di dati abbia accesso ai processi del computer.
Una volta configurato tutto, dovrai determinare la frequenza di campionamento con cui desideri tracciare queste metriche. Ad esempio, puoi misurare l'utilizzo della CPU ogni 30 secondi o ogni minuto.
Ci sono diversi modi per monitorare l'utilizzo della CPU, come usare il task manager o un comando come wmic CPU get load percentage per i sistemi Windows. Tuttavia, quando vuoi ottenere una visione d’insieme del tuo server, è meglio visualizzare questi dati su una dashboard.
Ricorda: Le prestazioni della CPU sono influenzate dalle condizioni hardware, come la temperatura della CPU e la velocità delle ventole. Potresti voler monitorare questi fattori insieme all’utilizzo (rappresentato come percentuale) in questi due stati, escludendo l’inattività.
| Occupata | Durante questo tempo, la CPU sta eseguendo un'attività. |
| I/O | Questo stato non è occupato, ma nemmeno inattivo. La CPU potrebbe essere in attesa di un'operazione I/O per eseguire un compito, in genere aspettando di inviare o ricevere dati. |
Due aspetti chiave che dovrai monitorare attentamente includono Privileged Time e User Time, poiché la somma di questi due ti darà il Processor Time, ciascuno definito come segue:
- Privileged Time: Percentuale di tempo in cui i processori eseguono processi non utente (cioè processi di kernel)
- User Time: Percentuale di tempo in cui i processori eseguono processi utente (ad es. shell dei comandi, server email, compilatore)
- Processor Time: Totale del tempo in cui la CPU è stata occupata
Tieni presente che superare il 100% non significa sempre che un sistema sia sovraccarico. Ad esempio, se hai un sistema multiprocessore, significa semplicemente che la somma dei due o più CPU è superiore al 100% (es: 50% e 60%). Controlla le prestazioni individuali per mantenere la salute del sistema.
Insieme all'utilizzo di CPU e disco, anche le attese sono considerate essenziali per il monitoraggio della salute e delle prestazioni dell'infrastruttura.

Attese
Le attese aiutano a capire quanto efficientemente vengono eseguiti i compiti e avvisano di possibili colli di bottiglia. Ma conoscerle soltanto non basta. Dovrai indagare ulteriormente per identificare il problema di prestazioni preciso.
Alti valori di attesa sono accettabili solo in brevi periodi, perché potresti avere attività intensive in corso, ma superare tali valori è generalmente motivo di preoccupazione.
2. Uptime del server
Il tuo server è inutile se non è disponibile per i tuoi utenti. Perciò, monitorare l’uptime del server è fondamentale. Ogni volta che la disponibilità del server scende sotto il 99,999% (lo standard noto come “cinque nove”), hai un serio problema da affrontare.
Utilizza le formule qui sotto per ottenere insight comprensibili e pratici dai tuoi sforzi di monitoraggio.
Come misurare l’uptime del server
Ecco alcuni concetti fondamentali da conoscere quando si monitora l’uptime del server:
- Uptime: La quantità di tempo in cui il tuo servizio o applicazione è attivo e disponibile per gli utenti. Formula: (Tempo totale - Tempo di inattività)/Tempo totale
- Mean time between failures (MTBF): Il tempo medio che intercorre tra gli incidenti di downtime. Formula: (Tempo totale - Tempo di inattività)/Numero di incidenti di downtime
- Mean time to resolution (MTTR): Il tempo medio necessario per risolvere un’interruzione. Formula: Tempo totale di inattività/Numero di incidenti di downtime
- Mean time to acknowledge (MTTA): Il tempo medio necessario per riconoscere un’interruzione in corso. Formula: Tempo totale di riconoscimento/Numero di incidenti di downtime
Tutte queste metriche aiutano a sviluppare una panoramica completa che illustra l’affidabilità della tua infrastruttura e la reattività del tuo team.
Quindi, ad esempio, avere valori sani per MTTR e MTTA è positivo. Tuttavia, se hai anche un valore MTBF elevato, dovrai indagare ulteriormente sulle cause principali dei periodi di inattività del server. Altrimenti, l’azienda è comunque a rischio di perdite finanziarie significative e perdita di fiducia degli utenti.
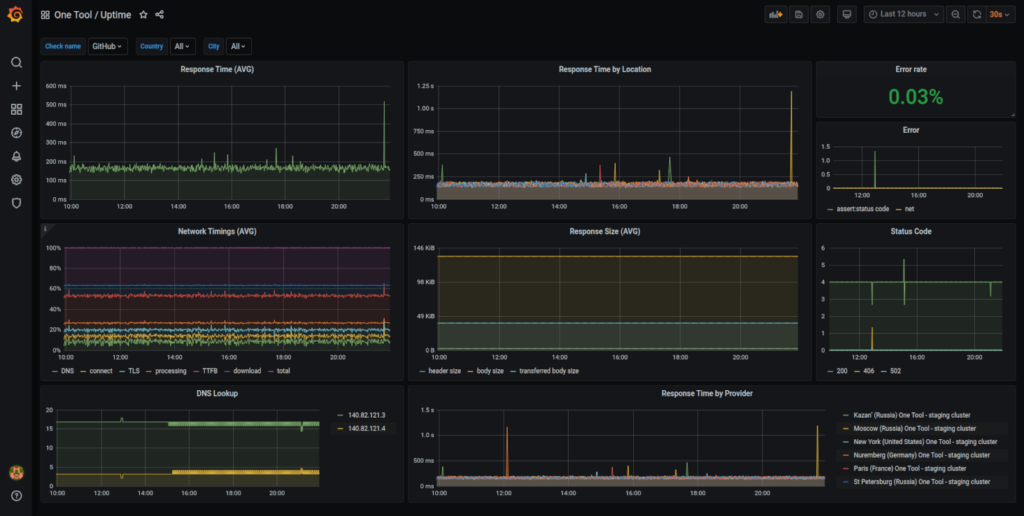
In definitiva, devi puntare al “five nines”, mantenendo i tempi di inattività a un massimo di circa cinque minuti all’anno. I software di monitoraggio server Grafana e Prometheus sono entrambi comunemente raccomandati come strumenti intuitivi e facilmente accessibili per questo aspetto del monitoraggio delle prestazioni.
3. Transazioni (e tassi di errore)
Hai bisogno di avere un quadro chiaro di quanto traffico la tua infrastruttura può gestire in qualsiasi momento. Pertanto, è essenziale tenere sotto controllo le transazioni—ovvero il numero di richieste per secondo—e il relativo tempo medio di risposta. Queste informazioni possono aiutarti a determinare risorse e capacità necessarie per far funzionare il server senza problemi.
Allo stesso tempo, tenere traccia del tasso di errore, ossia la percentuale di richieste fallite rispetto a quelle totali ricevute, può fornire ulteriori insight riguardo la capacità di carico del servizio. Per massimizzare il valore di questa metrica, è meglio sviluppare una baseline nel tempo tramite il monitoraggio passivo.
Questo è fondamentale per la tua capacità di monitorare le tendenze. Se puoi guardare al passato e determinare la capacità massima e le risorse necessarie per un funzionamento fluido, puoi agire in modo proattivo per allocare tali risorse e individuare problemi di infrastruttura per ridurre i tassi di errore e ottimizzare i tempi medi di risposta.
Come monitorare transazioni e tassi di errore
Di seguito sono riportati strumenti affidabili per tecniche di monitoraggio passivo delle prestazioni:
- Sniffer: Questi sono progettati per raccogliere misurazioni a livello “microscopico” “intercettando” il flusso del traffico su reti cablate e wireless. Wireshark è uno degli standard più utilizzati, raccoglie dati come timestamp, indirizzo MAC e IP, tempo di vita e altro. Possono essere utilizzati sia online che offline.
- Strutture di logging: Di solito sono integrate nei sistemi operativi e nelle applicazioni. Raccolgono principalmente informazioni sulle attività e gli eventi generati dalle applicazioni per l’uso offline.
Uno dei dieci migliori tool di monitoraggio dei server web particolarmente valido per monitorare le transazioni è Monitis. È un sistema di monitoraggio tutto in uno per server, siti web e applicazioni. Va bene sia per sistemi Windows che Linux, ed è ideale per coprire le basi, incluso il monitoraggio dell’uptime.
L’obiettivo e lo scopo degli sforzi di monitoraggio influenzeranno le misurazioni esatte e il modo di utilizzare queste tecniche.
Altre metriche da monitorare nelle transazioni
Tempo di risposta e numero totale di thread sono direttamente correlati alle transazioni. Questi ti informano su quanto tempo impiega il server a rispondere a una richiesta e sul numero di thread (che gestiscono le transazioni) utilizzati per gestire tutte queste richieste.
Ogni thread utilizza tempo CPU e RAM. Un numero eccessivo può portare a prestazioni inferiori alla media. Ci sono diversi aspetti da monitorare, inclusi:
- Numero totale di thread in un web server o in un pool di container, inclusi questi tipi:
- Attivi
- In attesa
- Bloccati
- In standby
- Richieste utente in attesa e lunghezza delle code
Di solito puoi misurare il tempo di risposta del server come Time to First Byte (TTFB). Si tratta del numero di millisecondi che un browser impiega a ricevere il primo byte della risposta del server. Generalmente, tutto ciò che supera i cinque secondi è critico.
Scegliere le Metriche Giuste per il Monitoraggio delle Prestazioni del Server
Esiste un lungo elenco di metriche che puoi monitorare mentre tieni sotto controllo lo stato di salute e le prestazioni del tuo server, ma gli obiettivi specifici dipendono principalmente dallo scopo delle tue attività di monitoraggio.
Alcune metriche sono ideali per ottenere informazioni sulla capacità di carico dell'hardware e del sistema operativo, mentre altre sono pensate per osservare l'attività degli utenti. In ogni caso, CPU, uptime e transazioni sono fondamentali che non possono essere trascurati.
Man mano che avanzate come QA lead e i vostri obiettivi cambiano inevitabilmente, aggiungerete senza dubbio altre metriche di monitoraggio del server alla vostra dashboard. Per ulteriori approfondimenti su quali dovrebbero essere queste metriche e su come gestirle, iscriviti alla newsletter.


{kind=link}