10 Meilleurs Outils de Suivi d’Expériences ML en 2026

Liste des meilleurs outils de suivi d'expériences ML


Les outils de suivi d'expériences ML vous aident à enregistrer, organiser et comparer les expériences de machine learning afin que vous puissiez gérer les résultats et reproduire les découvertes en toute confiance. Si vous cherchez des moyens pratiques pour suivre vos expériences, partager vos avancées avec votre équipe ou garder vos modèles et jeux de données organisés, le bon outil peut véritablement faire la différence.
Dans cette liste, vous trouverez des solutions adaptées à différents environnements techniques et flux de travail, afin de vous aider à réduire les frictions, simplifier les rapports et vous concentrer sur une gestion fiable de vos expériences de machine learning.
Table of Contents
Pourquoi faire confiance à nos avis logiciels
Nous testons et analysons des logiciels depuis 2023. En tant que dirigeants technologiques, nous savons à quel point il est crucial et difficile de faire le bon choix lors de la sélection d’un logiciel.
Nous investissons dans des recherches approfondies pour aider notre audience à prendre de meilleures décisions d’achat de logiciels. Nous avons testé plus de 2 000 outils pour différents usages technologiques et rédigé plus de 1 000 avis complets. Découvrez comment nous restons transparents & notre méthodologie d’évaluation des logiciels.
Résumé des meilleurs outils de suivi d'expériences ML
Ce tableau comparatif résume les détails tarifaires de mes principaux choix d’outils de suivi d’expériences ML pour vous aider à trouver le meilleur pour votre budget et vos besoins professionnels.
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | Idéal pour la comparaison d’expériences en temps réel | Offre gratuite disponible | À partir de $19/utilisateur/mois | Website | |
| 2 | Idéal pour des tableaux de bord de visualisation personnalisables | Forfait gratuit disponible | À partir de $60/mois | Website | |
| 3 | Idéal pour la gestion automatique des versions dans les pipelines | Essai gratuit de 14 jours disponible | Tarification disponible sur demande | Website | |
| 4 | Idéal pour l'orchestration automatique des pipelines | Offre gratuite disponible | À partir de $15/utilisateur/mois | Website | |
| 5 | Idéal pour la prise en charge open source du cycle de vie des modèles | Démo gratuite + offre gratuite à vie disponible | Gratuit à vie (open source) | Website | |
| 6 | Idéal pour une architecture à plugins extensible | Offre gratuite disponible | À partir de $399/mois | Website | |
| 7 | Idéal pour les options de déploiement hybrides et sur site | Formule gratuite + démo gratuite disponible | À partir de 450 $/mois (facturé annuellement) | Website |
-

TestDevLab
Visit Website -
Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8


Avis détaillés sur les meilleurs outils de suivi d'expériences ML
Vous trouverez ci-dessous mes résumés détaillés des meilleurs outils de suivi d’expériences ML présents dans ma présélection. Mes avis proposent un aperçu complet des fonctionnalités, des intégrations et des cas d’utilisation idéaux de chaque plateforme, pour vous aider à trouver celle qui vous convient le mieux.
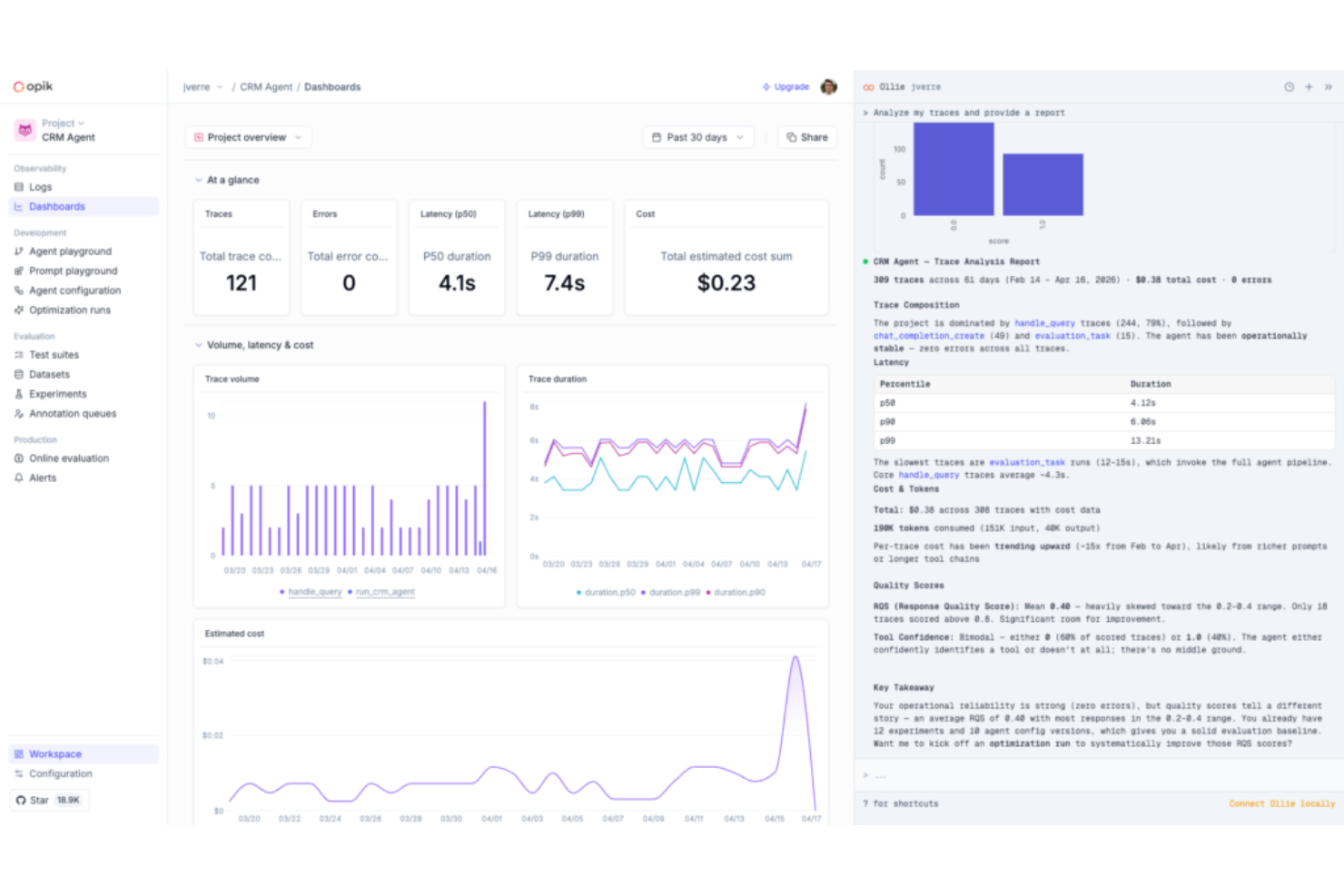
Comet est une plateforme de suivi d’expériences ML et d’évaluation de modèles qui consigne les métriques, hyperparamètres et artefacts issus des entraînements, et s’étend à l’observabilité des LLM et à l’évaluation de l’IA agentique via son produit Opik.
À qui s’adresse Comet ?
Comet convient particulièrement aux équipes ML et IA de sociétés en croissance ou d’entreprises qui réalisent un grand nombre d’expériences et nécessitent une visibilité en temps réel sur les runs d’entraînement.
Pourquoi j’ai choisi Comet
J’ai sélectionné Comet comme l’un des meilleurs outils car son tableau de bord de suivi d’expériences actualise les métriques en direct pendant l’entraînement, permettant à mon équipe de repérer une courbe de perte qui diverge et de stopper un run défaillant avant de gaspiller du calcul. J’utilise également sa vue de comparaison d’expériences côte à côte pour filtrer des dizaines de runs selon la valeur des hyperparamètres et isoler immédiatement la configuration ayant donné la meilleure précision de validation. En plus des fonctionnalités MLOps classiques, Comet propose désormais l’évaluation de LLM grâce à Opik, ce qui fait que je n’ai pas à changer d’outil lors du passage de l’entraînement à la surveillance en production.
Fonctionnalités clés de Comet
- Registre de modèles : Stockez, versionnez et gérez les modèles entraînés dans un registre centralisé avec des étiquettes de stade comme staging ou production.
- Journalisation des artefacts : Consignez et versionnez les jeux de données, images, matrices de confusion et fichiers audio, directement au côté des expériences.
- Panneaux personnalisés : Réalisez des visualisations personnalisées dans l’interface Comet avec JavaScript pour aller au-delà des graphiques par défaut.
- Suivi des métriques systèmes : Capture automatiquement l’utilisation du GPU, la charge CPU et la mémoire à chaque run sans instrumentation supplémentaire.
Intégrations de Comet
Comet offre plus de 30 intégrations natives, dont PyTorch, TensorFlow, Keras, Scikit-learn, XGBoost, Hugging Face Transformers, Ray, Kubeflow, Snowflake et Vertex AI. Il est disponible sur Zapier et propose une API REST ainsi que des SDK Python, Java, JavaScript et R pour des intégrations sur mesure.
Pros and Cons
Pros:
- Journalisation automatique des métriques avec peu de code
- Visualisation en temps réel des runs d’entraînement
- Suit à la fois les expériences ML et les LLM
Cons:
- L’offre Pro limite les équipes à 10 utilisateurs
- Options de personnalisation de l’UI limitées
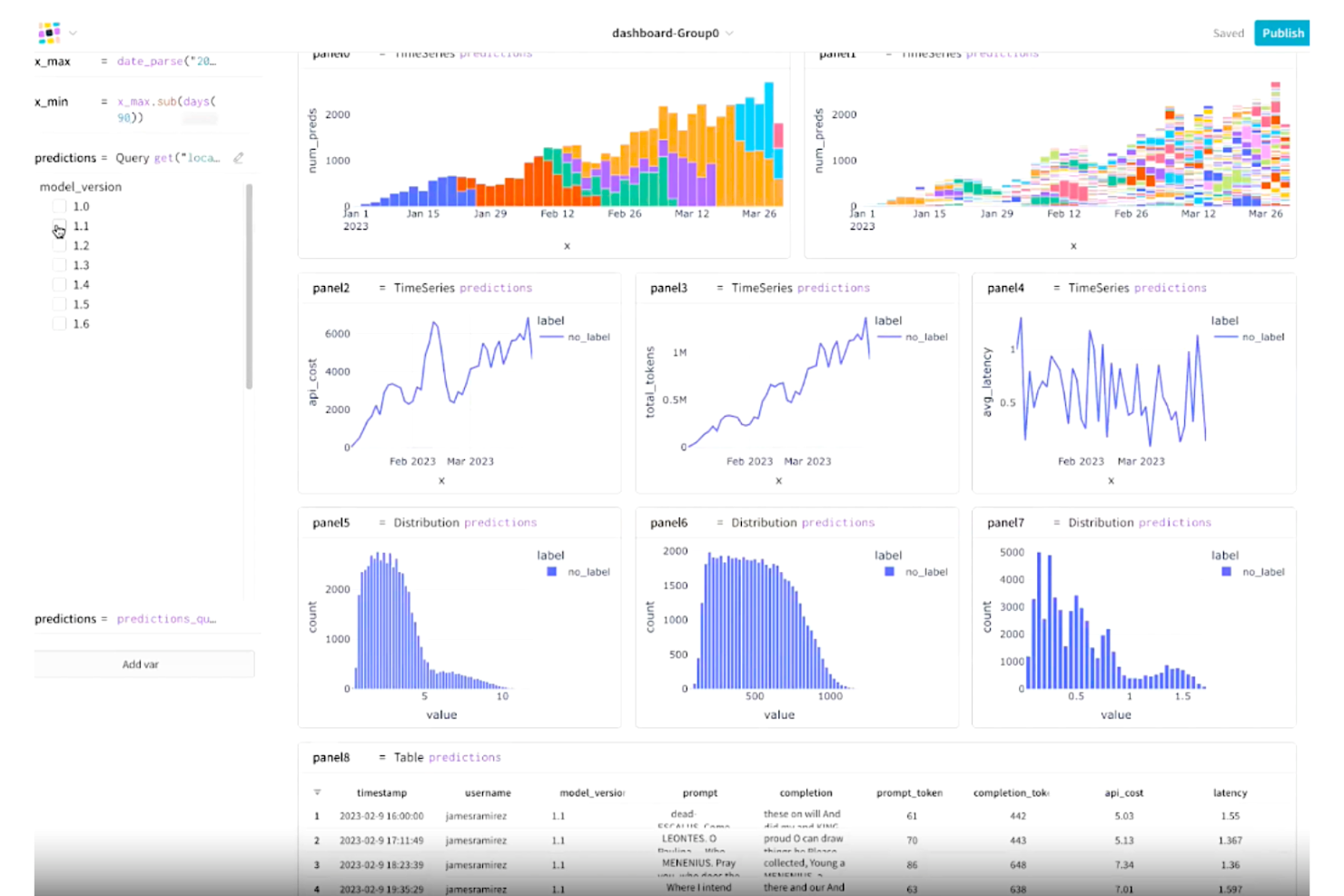
Weights & Biases est une plateforme de suivi d'expériences en apprentissage automatique qui enregistre les métriques, les hyperparamètres et les checkpoints de modèles, tout en permettant de visualiser et de comparer les essais à l'aide de tableaux de bord interactifs.
À qui s'adresse Weights & Biases ?
Weights & Biases convient particulièrement aux data scientists et ingénieurs ML qui réalisent fréquemment des expériences et ont besoin de comparer en détail les résultats au sein de grandes équipes.
Pourquoi j'ai choisi Weights & Biases
Weights & Biases compte parmi mes favoris en raison de ses tableaux de bord de visualisation personnalisables particulièrement poussés. Je peux extraire en direct l'utilisation du GPU, les courbes de perte et des prédictions exemples dans un tableau de bord interactif unique pendant un entraînement, ce qui permet d'identifier rapidement les goulets d'étranglement. La fonctionnalité Sweeps me permet de visualiser les résultats des recherches d'hyperparamètres directement à côté de mes métriques d'expérience, de sorte que je compare tout en un seul endroit. Les rapports offrent également la possibilité à mon équipe d'annoter et de partager ces tableaux de bord sans quitter la plateforme.
Fonctionnalités clés de Weights & Biases
- Artifacts : Versionnez et suivez les jeux de données, modèles et résultats d'évaluation à travers les essais d'expériences.
- Registre de modèles : Centralisez les modèles entraînés et reliez-les directement aux expériences qui les ont produits.
- Regroupement des essais : Organisez les essais associés en groupes afin de comparer les résultats entre différentes configurations d'entraînement.
- Alertes : Définissez des notifications automatiques pour certains seuils de métriques, échecs d'essais ou la fin d'une tâche.
Intégrations Weights & Biases
Weights & Biases propose des intégrations natives avec PyTorch, Keras, TensorFlow, Scikit-learn, XGBoost, Hugging Face Transformers et PyTorch Lightning, ainsi qu'avec des outils LLM comme LangChain et LlamaIndex. Il s'intègre aussi à Kubeflow, Jenkins, Airflow, GitHub Actions, AWS SageMaker et Google Vertex AI. Une API et un SDK Python sont disponibles pour les intégrations personnalisées.
Pros and Cons
Pros:
- Streaming des métriques en temps réel vers des tableaux de bord
- Journalisation automatique des commits git et des configurations
- Rapports collaboratifs riches avec graphiques intégrés
Cons:
- L'interface Web ralentit avec de nombreux essais en parallèle
- Des lacunes dans la documentation sur les fonctionnalités de base
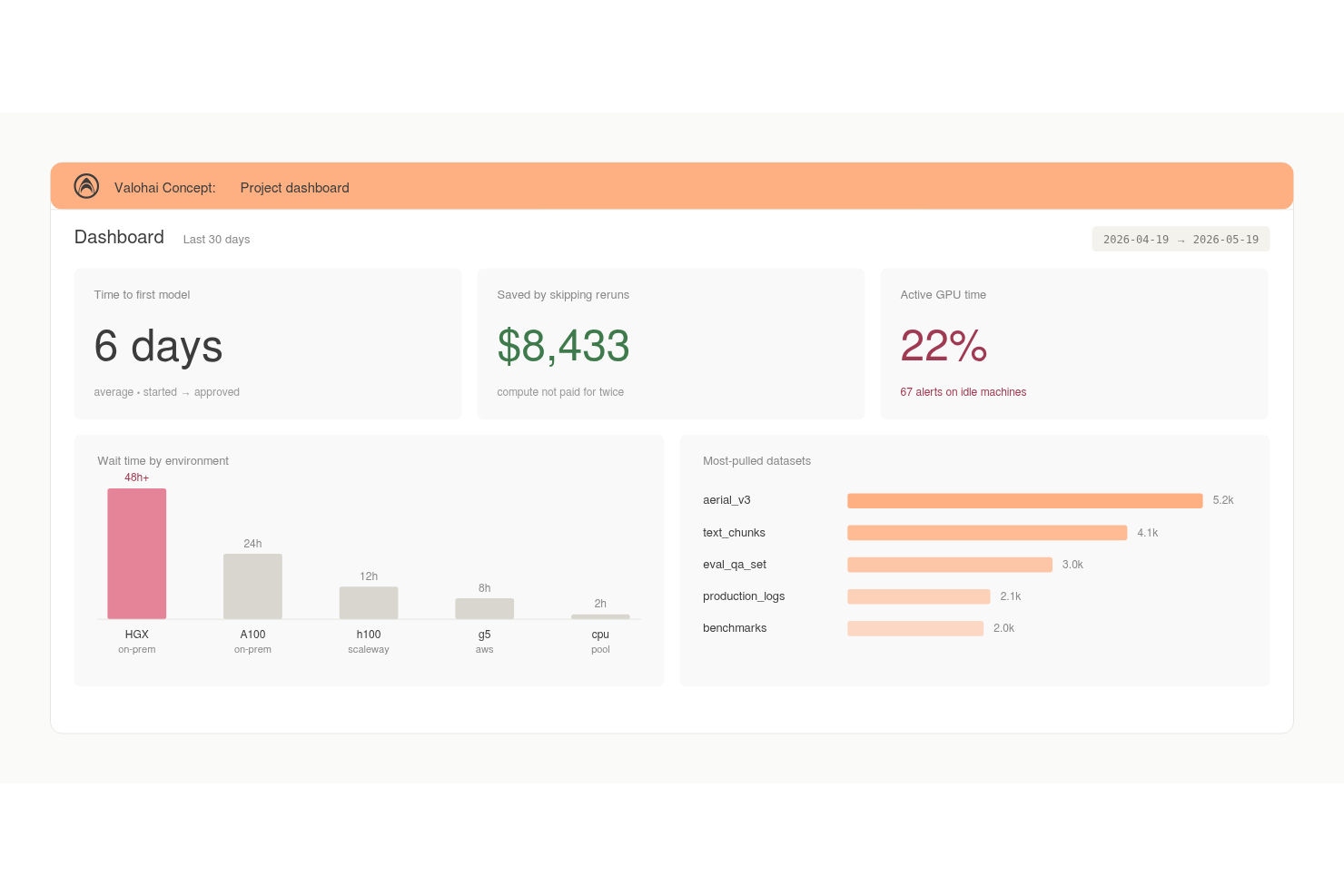
Valohai est une plateforme ML qui combine le suivi automatique des expériences, la gestion des versions de jeux de données, la traçabilité des modèles et l'orchestration du calcul cloud pour les équipes créant et entraînant des modèles à grande échelle.
Pour qui Valohai est-il le mieux adapté ?
Valohai est particulièrement adapté aux équipes d'ingénierie ML de taille moyenne à grande entreprise qui exécutent fréquemment des tâches d'entraînement sur plusieurs environnements cloud.
Pourquoi j'ai choisi Valohai
J'ai choisi Valohai comme l'un des meilleurs car la gestion automatique des versions est véritablement intégrée à chaque exécution. Les métriques, les métadonnées, les journaux et les hyperparamètres sont versionnés sans aucune étiquette manuelle, je n'ai donc jamais à reconstituer ce qui a été exécuté et quand. J'apprécie également que Valohai assure une traçabilité complète des jeux de données et des modèles, ce qui me permet de remonter exactement à quelle version du jeu de données a produit un modèle donné. Chaque exécution est reproductible par conception, ce qui élimine l'incertitude qui rend les audits d'expériences laborieux.
Fonctionnalités clés de Valohai
- Vue comparative des expériences : Affiche plusieurs exécutions côte à côte, ce qui vous permet de comparer les hyperparamètres, les métriques et les résultats des expériences dans un seul tableau.
- Éditeur de pipelines : Un éditeur visuel pour construire des pipelines ML en plusieurs étapes, où chaque nœud correspond à une étape d'exécution versionnée.
- Orchestration du calcul cloud : Provisionne et arrête automatiquement les instances cloud sur AWS, GCP ou Azure pour chaque tâche d'entraînement.
- Déclencheurs de déploiement : Permet de promouvoir directement les modèles entraînés vers un endpoint de mise en production depuis la même plateforme utilisée pour l'entraînement.
Intégrations Valohai
Valohai propose un petit ensemble d'intégrations préconstruites via sa bibliothèque Ecosystem, incluant des connecteurs pour Snowflake, BigQuery et Redshift, un modèle Hugging Face ainsi que des intégrations avec Slurm et OVHcloud. Il fonctionne sur AWS, GCP, Azure et Oracle Cloud Infrastructure, et propose une API REST pour développer des intégrations personnalisées.
Pros and Cons
Pros:
- Journalise automatiquement les métriques à partir des JSON imprimés
- Fonctionne sur tout matériel cloud ou sur site
- Traçabilité complète du modèle au jeu de données
Cons:
- Adapter les scripts au format Valohai demande des efforts
- La vue principale des expériences manque d'attrait visuel
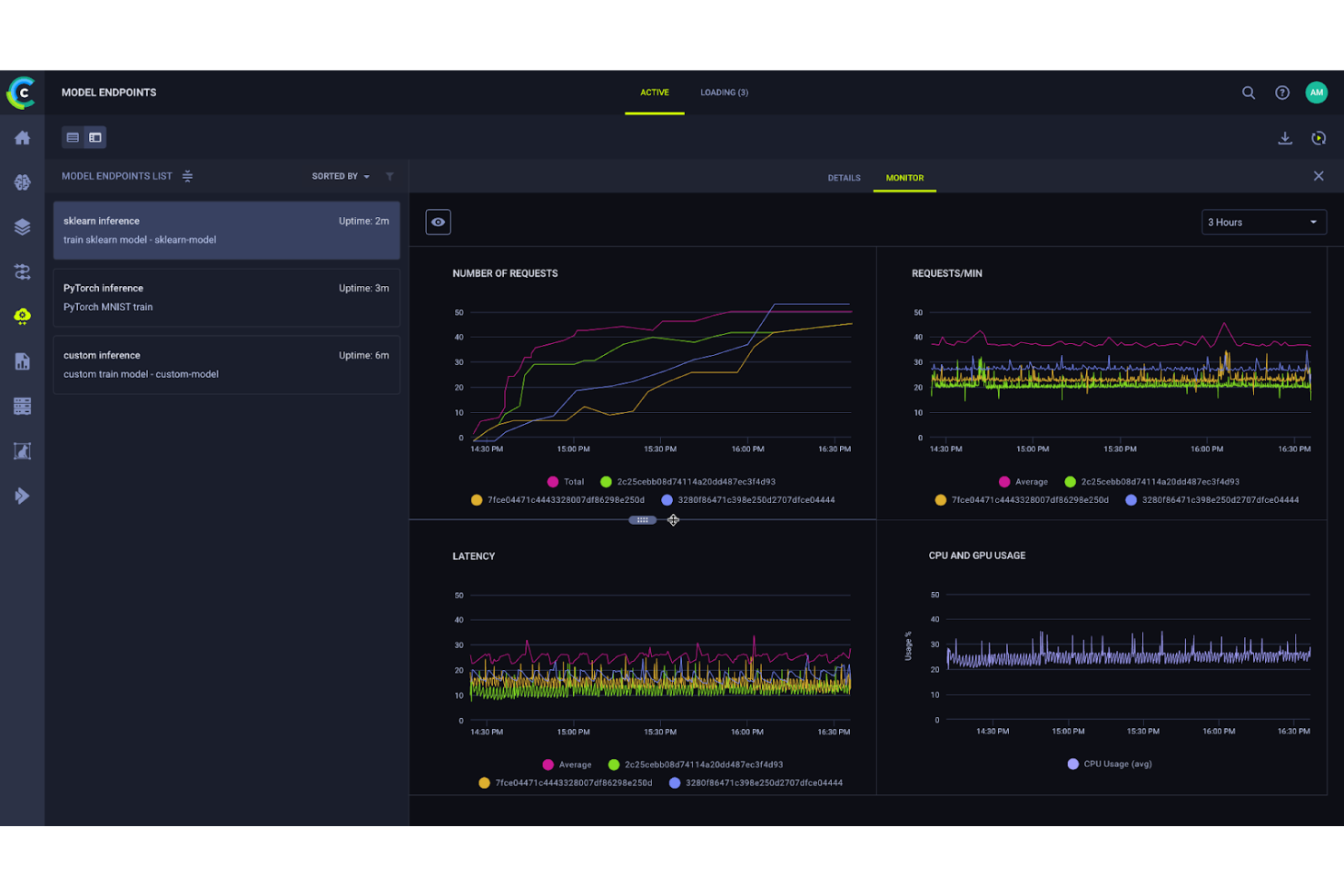
ClearML est une plate-forme MLOps open-source qui couvre le suivi des expériences, la gestion des versions de jeux de données, la gestion des modèles et l'orchestration de pipelines tout au long du cycle de vie du machine learning.
À qui s'adresse ClearML ?
ClearML s'adresse particulièrement aux ingénieurs ML et aux data scientists travaillant dans des organisations qui hébergent elles-mêmes leur infrastructure MLOps et qui souhaitent un contrôle total de leurs pipelines.
Pourquoi j'ai choisi ClearML
ClearML mérite sa place dans ma sélection car son orchestration automatique des pipelines est véritablement sans intervention. Lorsque j'ajoute un travail à une file d'attente, ClearML le containerise avec tout son environnement et gère automatiquement la planification et la gestion des ressources. Je n'ai pas besoin de réécrire le code pour passer de l'on-premise, au cloud ou aux clusters HPC. J'apprécie aussi que les composants de pipeline en cache me permettent d’éviter les étapes redondantes lors des relances, ce qui réduit considérablement le temps de cycle dans les processus d’entraînement itératifs.
Principales fonctionnalités de ClearML
- Journalisation automatique des expériences : Capture automatiquement les métriques, hyperparamètres, sorties console et code source de chaque exécution d'entraînement sans instrumentation supplémentaire.
- Versionnage des données avec ClearML : Gérez et versionnez les jeux de données avec traçabilité complète, chaque version étant liée directement aux expériences qui l'ont utilisée.
- Registre de modèles : Stockez, étiquetez et récupérez les modèles entraînés avec gestion des versions et des étapes tout au long du cycle de développement.
- Optimisation d'hyperparamètres : Lancez des recherches HPO automatisées sur vos expériences avec des stratégies intégrées, telles que l’optimisation bayésienne et la recherche aléatoire.
Intégrations ClearML
ClearML propose des intégrations natives avec PyTorch, TensorFlow, Keras, Scikit-learn, XGBoost, Hugging Face Transformers, FastAI, Optuna et Hydra, ainsi qu'avec des outils de visualisation comme Matplotlib et TensorBoard. Une API et un SDK Python sont disponibles pour des intégrations personnalisées.
Pros and Cons
Pros:
- Serveur open-source auto-hébergé, sans frais d'abonnement
- Journalise automatiquement le code, les jeux de données et les hyperparamètres sans instrumentation
- La conception modulaire permet d'adopter des composants individuellement
Cons:
- Des lacunes dans la documentation ralentissent la prise en main pour les nouveaux utilisateurs
- La navigation entre les modules donne une impression de fragmentation à grande échelle
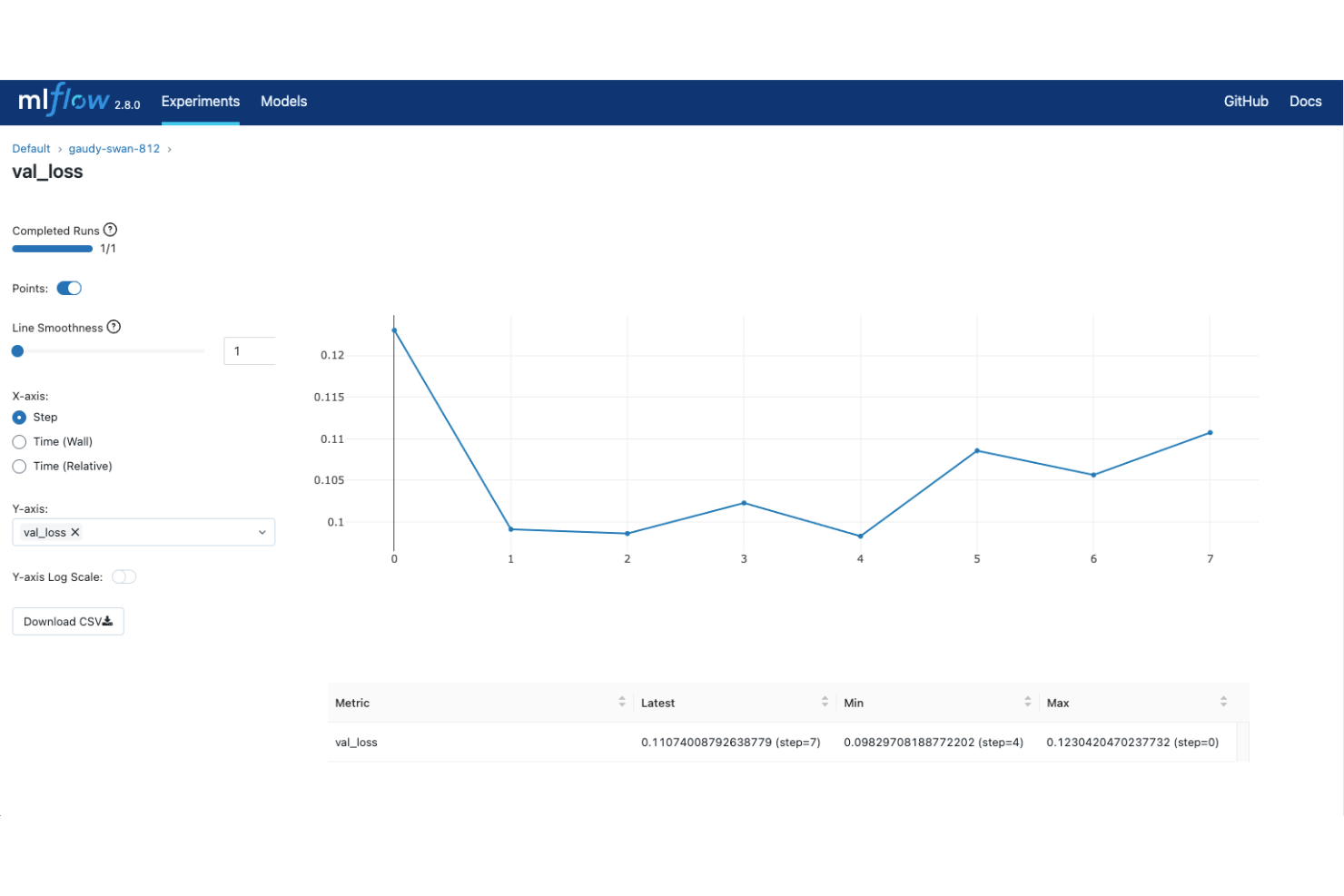
MLflow est une plateforme open source de suivi d'expériences de machine learning couvrant l'intégralité du cycle de vie du modèle, de la journalisation des expériences à la comparaison des exécutions, jusqu'à l'empaquetage, la gestion des versions et le déploiement des modèles.
À qui s'adresse MLflow ?
MLflow est particulièrement adapté aux ingénieurs ML et data scientists travaillant dans des organisations qui hébergent leurs propres outils et souhaitent garder un contrôle total sur leur infrastructure de suivi d'expériences sans dépendance à un fournisseur.
Pourquoi j'ai choisi MLflow
MLflow figure dans ma sélection car il couvre l'ensemble du cycle de vie du modèle au sein d'un même framework open source. J'utilise l'API de suivi MLflow pour enregistrer les paramètres, les métriques et les artefacts à chaque exécution, puis le registre de modèles pour versionner et faire évoluer les modèles du développement à la production. Ce que j'apprécie particulièrement, c'est de pouvoir empaqueter des modèles au format standard MLflow et les déployer sur n'importe quelle cible sans devoir réécrire le code de service.
Principales fonctionnalités de MLflow
- Journalisation automatique : Capture automatiquement les paramètres, métriques et artefacts depuis des bibliothèques prises en charge comme Scikit-learn, XGBoost et PyTorch sans appels de journalisation manuels.
- Interface de comparaison des exécutions : Visualisez et comparez côte à côte les métriques de plusieurs entraînements dans l'interface web intégrée de MLflow.
- MLflow Projects : Emballe le code ML avec ses dépendances et points d'entrée pour garantir la reproductibilité exacte d'une exécution sur toute machine.
- Système de plugins : Étend les fonctionnalités de suivi, de stockage et de déploiement de MLflow grâce à des plugins communautaires, sans modifier le cœur du code.
Intégrations MLflow
MLflow propose plus de 60 intégrations intégrées, y compris PyTorch, TensorFlow, Scikit-learn, XGBoost, LightGBM, Hugging Face Transformers, LangChain, LlamaIndex et OpenAI. Il prend également en charge AWS SageMaker, Azure ML, Databricks et OpenTelemetry. Une API REST et un SDK Python sont disponibles pour les intégrations personnalisées.
Pros and Cons
Pros:
- Journalisation indépendante des frameworks pour diverses bibliothèques ML
- Versionnage complet des modèles avec transitions de stade
- Peut être auto-hébergé sur toute infrastructure
Cons:
- Nécessite des compétences DevOps pour une mise en production
- Visualisation matérielle intégrée limitée pour les profils
ZenML est une plateforme open source d'orchestration de pipelines ML qui gère l'orchestration des workflows, la gestion de versions des artefacts, la traçabilité des modèles et le suivi des expériences sur toute infrastructure cloud ou pile ML.
À qui s'adresse ZenML ?
ZenML convient particulièrement aux ingénieurs ML et aux équipes de science des données qui doivent standardiser et faire évoluer des pipelines ML sur plusieurs environnements cloud ou infrastructures.
Pourquoi j'ai choisi ZenML
ZenML figure sur ma liste car son architecture par composants de stack me permet d'interchanger n'importe quelle partie de mon infrastructure ML sans réécrire de code de pipeline. Je peux brancher MLflow ou Weights & Biases pour le suivi d'expériences, passer le stockage d'artefacts du local à S3, et changer l'orchestrateur pour Kubeflow, tout cela en modifiant simplement la stack active. J'utilise aussi les saveurs de composants personnalisés de ZenML pour développer des intégrations de suivi propriétaires à intégrer directement dans la même abstraction de pipeline.
Fonctionnalités clés de ZenML
- Mise en cache des étapes du pipeline : Met automatiquement en cache les sorties des étapes déjà exécutées, afin que les étapes inchangées ne soient pas réexécutées lors d'expériences itératives.
- Gestion de versions des artefacts : Suit chaque artefact produit par une exécution de pipeline, y compris les jeux de données, modèles et métriques, avec une traçabilité complète jusqu'à l'étape d'origine.
- Registre de modèles : Stocke et gère la version des modèles entraînés, ainsi que leurs métadonnées associées, les exécutions de pipeline et l'historique des déploiements dans un registre centralisé.
- Tableau de bord ZenML : Offre une interface web pour parcourir les exécutions de pipelines, comparer les résultats d'expériences et inspecter les métadonnées des artefacts à travers les stacks.
Intégrations ZenML
ZenML propose 66 intégrations natives dans l'écosystème ML, y compris MLflow, Weights & Biases, Neptune, Comet et TensorBoard, ainsi que des orchestrateurs comme Kubeflow, Apache Airflow, Kubernetes et Databricks, et des infrastructures cloud pour AWS, Google Cloud et Microsoft Azure. Une API est disponible pour des intégrations personnalisées.
Pros and Cons
Pros:
- Interchanger l'infrastructure sans réécrire le code du pipeline
- Stack indépendante du cloud pour éviter l'enfermement propriétaire
- Versionnement automatique des artefacts sur les exécutions de pipelines
Cons:
- Dépendance à des outils tiers pour la visualisation des expériences
- Configuration initiale de la stack nécessitant un effort de mise en place important
{kind=link}
Polyaxon est une plateforme de suivi d'expériences ML et d'orchestration de pipelines qui couvre le suivi des expériences, l'optimisation des hyperparamètres, la gestion de versions des artefacts, le registre des modèles et la planification de travaux distribués sur des infrastructures cloud et sur site.
Pour qui Polyaxon est-il le mieux adapté ?
Polyaxon est particulièrement adapté aux ingénieurs ML dans les grandes entreprises qui opèrent sous des exigences strictes en matière de gouvernance des données ou qui ont besoin d'exécuter des charges de travail sur une infrastructure privée.
Pourquoi j'ai choisi Polyaxon
J'ai inclus Polyaxon dans mes meilleurs choix car il s'agit de l'une des rares plateformes de suivi d'expériences ML conçues dès le départ pour fonctionner entièrement au sein de votre propre infrastructure. Je l'exécute sur un cluster Kubernetes privé, et chaque journal d'expérience, artefact et modèle reste à l'intérieur de notre réseau. Son architecture basée sur des agents me permet de connecter des environnements isolés sur site à un plan de contrôle central, sans exposer de données brutes à l'extérieur, ce qui est une exigence réelle dans les secteurs réglementés.
Fonctionnalités clés de Polyaxon
- Recherche et optimisation d'hyperparamètres : Exécutez des groupes d'expériences en parallèle à l'aide de stratégies de recherche distribuée pour trouver les configurations de modèles optimales.
- Hub de composants : Définissez des modules réutilisables avec entrées et sorties typées pouvant être partagés et versionnés entre les pipelines de votre équipe.
- Recherche avancée : Filtrez les exécutions par nom, description, regex, champs spécifiques, métriques ou configurations afin de localiser rapidement les expériences.
- Respect des SLA : Appliquez des politiques de TTL, de délai d'expiration et de nouvelle tentative à chaque opération afin de maintenir les pipelines dans les limites définies.
Intégrations Polyaxon
Polyaxon propose un large éventail d'intégrations natives dans les domaines du suivi ML, de l'orchestration et de l'infrastructure, dont TensorBoard, PyTorch, TensorFlow, Keras, XGBoost, Hugging Face, Kubeflow, Slack, GitHub et Jenkins. Il se connecte également à Zapier et propose une API pour des intégrations personnalisées et l'automatisation CI/CD.
Pros and Cons
Pros:
- Planification native Kubernetes des tâches d'entraînement distribuées
- Multi-location intégré avec contrôles d'accès fins
- Prend en charge les déploiements sur site, cloud et hybrides
Cons:
- Nécessite une expertise Kubernetes approfondie pour l'exploitation
- Communauté plus restreinte que MLflow ou W&B
Comment j'évalue les outils de suivi d'expériences ML
Je divise mon évaluation en deux niveaux : ce que chaque outil doit absolument faire (comme la journalisation automatique des exécutions PyTorch) et ce qui distingue les meilleurs outils.
Fonctionnalités de base (Critères essentiels pour cette liste)
Lorsque je sélectionne des outils pour ma liste, j'attribue un score à chacun sur une échelle de 0 (ne propose pas la fonctionnalité) à 5 (excelle dans ce domaine) pour chaque fonctionnalité essentielle ci-dessous. Ensuite, je calcule le score total de l'outil en pourcentage. Chaque outil doit atteindre un score total minimum de 65 % pour être pris en compte dans la sélection.
- Journalisation des expériences : Je vérifie si l'outil capture automatiquement les métriques, hyperparamètres et la télémétrie système des phases d'entraînement ou s'il nécessite l'instrumentation manuelle du SDK pour chaque point de données.
- Comparaison et visualisation des exécutions : Les tableaux comparatifs côte à côte sont un début, mais je recherche des graphiques interactifs, comme des tracés de coordonnées parallèles, qui aident à repérer des tendances à travers des dizaines d'exécutions dans vos projets ML.
- Versionnage des artefacts et des modèles : J'évalue comment chaque outil gère les versions de jeux de données, les points de sauvegarde des modèles (checkpoints) et des sorties, y compris s'il relie les artefacts à l'exécution spécifique qui les a générés.
- Prise en charge des frameworks ML : L'outil doit couvrir les frameworks réellement utilisés par votre équipe, de PyTorch et TensorFlow à Hugging Face Transformers et XGBoost, avec un minimum de code d'adaptation.
- Reproductibilité et traçabilité : Je privilégie les outils qui capturent ensemble les commits du code, les instantanés de dépendances et l'état des jeux de données, afin que vous puissiez relancer une expérience réalisée il y a six mois et obtenir le même résultat.
- Collaboration et partage : Les équipes réparties sur plusieurs fuseaux horaires ont besoin d'espaces de travail partagés, d'un accès basé sur les rôles, et de la possibilité de commenter ou de partager des exécutions précises sans devoir exporter de fichiers CSV en permanence.
Une fois que j'ai une liste d'outils qui répondent à ces critères, j'analyse ce qui différencie chaque plateforme.
Facteurs de différenciation (Ce qui distingue les fournisseurs)
Voici comment je compare et distingue les différents fournisseurs :
Fonctionnalités remarquables
L'optimisation des hyperparamètres est un facteur clé de différenciation. Je recherche des fonctionnalités intégrées permettant d'automatiser les recherches à travers plusieurs exécutions distribuées et de visualiser les performances selon les différentes configurations en un seul endroit. Le suivi en direct des ressources est aussi un vrai plus : lorsqu'on peut surveiller l'utilisation GPU et mémoire pendant l'entraînement, on détecte les goulets d'étranglement avant de gaspiller des heures de calcul. Le reporting collaboratif complète l'offre pour les grandes équipes, où des tableaux de bord partageables remplacent les feuilles de calcul manuelles et permettent aux data scientists de discuter des résultats avec les parties prenantes sans changer d'outil.
Au-delà des fonctionnalités
La flexibilité de déploiement compte plus que ce que beaucoup d'équipes imaginent. J'évalue si un outil prend en charge l'auto-hébergement ou les installations isolées (air-gapped) pour les équipes qui manipulent de la propriété intellectuelle sensible ou des données réglementées. L'évolutivité est un autre critère : la journalisation de milliers d'exécutions simultanées ne doit pas dégrader les performances des requêtes ni provoquer de pics de coûts imprévisibles. L'expérience d'intégration différencie également les outils, car une documentation de démarrage rapide efficace et des forums communautaires actifs permettent à votre équipe d'instrumenter ses scripts d'entraînement en quelques heures, pas en quelques semaines.
Comment choisir un outil de suivi d'expériences ML
Il est facile de se perdre dans de longues listes de fonctionnalités et des grilles tarifaires complexes. Pour vous aider à rester concentré durant votre processus de sélection logicielle, voici une liste de points à garder à l’esprit :
| Critère | À prendre en compte |
|---|---|
| Scalabilité | L’outil peut-il gérer le volume et la fréquence d’expériences attendus à mesure que votre équipe et vos données grandissent ? |
| Intégrations | Peut-il se connecter directement à vos frameworks ML préférés, outils d’orchestration et systèmes de déploiement ? |
| Personnalisation | Pouvez-vous adapter les champs de métadonnées, les étapes du workflow et les rapports aux besoins spécifiques de votre équipe ? |
| Facilité d’utilisation | Les chercheurs et ingénieurs trouveront-ils l’interface intuitive, ou faudra-t-il surmonter une courbe d’apprentissage importante ? |
| Mise en place et onboarding | Combien de temps faut-il pour passer de l’achat à la première expérience suivie ? Quelles ressources d’installation sont nécessaires ? |
| Coût | Les tarifs selon l’usage, les frais de stockage ou les modules complémentaires requis sont-ils clairs et prévisibles pour vos prévisions ? |
| Sécurité des données | L’outil prend-il en charge le chiffrement, les permissions granulaires et les systèmes d’authentification pour protéger les données sensibles ? |
| Exigences de conformité | L’outil vous aide-t-il à respecter les réglementations sectorielles, clients ou géographiques (SOC 2, ISO 27001, RGPD) ? |
Qu’est-ce qu’un outil de suivi d’expériences ML ?
Les outils de suivi d’expériences ML sont des plateformes logicielles qui consignent, organisent et versionnent les expériences de modèles de machine learning, incluant leurs paramètres, leur code, leurs jeux de données et leurs métriques. Ces outils permettent à votre équipe de conserver l’historique des expériences, de comparer les résultats et de reproduire entièrement les exécutions passées, facilitant ainsi la collaboration et l’audit à mesure que les processus se complexifient.
Fonctionnalités des outils de suivi d’expériences ML
Lors de la sélection d’outils de suivi d’expériences en apprentissage automatique (ML), veillez à ce que les fonctionnalités clés suivantes soient présentes :
- Enregistrement des expériences : Consigne les paramètres de chaque session d’entraînement, les configurations, les références du code source et les métriques afin de conserver une piste d’audit claire.
- Comparaison des exécutions : Permet de visualiser et d’analyser plusieurs expériences côte à côte pour comprendre l’impact des différents réglages ou modifications sur vos résultats.
- Versionnage des artefacts : Gère automatiquement les versions des jeux de données, des modèles ML versionnés et des autres résultats pour pouvoir reproduire ou poursuivre tout travail passé à tout moment.
- Intégrations aux frameworks : Se connecte directement aux frameworks ML populaires, facilitant la mise en place du suivi avec un minimum de modifications de votre workflow.
- Traçabilité des lignées : Cartographie toute la chaîne de la donnée brute jusqu’au modèle final, soutenant la reproductibilité et les exigences de conformité réglementaire.
- Outils collaboratifs : Permet à plusieurs utilisateurs de commenter, de documenter des analyses et de partager les résultats au sein de l’équipe.
- Métadonnées personnalisées : Autorise l’ajout de champs ou de tags spécifiques à votre projet, pour catégoriser les expériences selon les besoins de votre workflow.
- Gestion des accès basée sur les rôles : Restreint l’accès aux données sensibles et aux actions, soutenant la gouvernance à l’échelle de l’organisation et le respect des standards de sécurité.
- Tableaux de bord et visualisations : Génère des rapports personnalisables et des visualisations de données afin de mettre en avant rapidement les tendances et anomalies issues de vos expériences.
- Recherche et filtrage : Permet à votre équipe de retrouver facilement des expériences, exécutions et artefacts pertinents selon les paramètres, la date ou d’autres critères, économisant du temps à mesure que le projet grandit.
Fonctionnalités IA courantes des outils de suivi d’expériences ML
Au-delà des fonctionnalités standards des outils de suivi d’expériences ML mentionnées ci-dessus, beaucoup de ces solutions intègrent l’IA par le biais de fonctionnalités telles que :
- Détection automatisée d’anomalies : Utilise l’IA pour surveiller les métriques d’expériences et signaler les schémas ou valeurs inhabituels, aidant les équipes à détecter rapidement la dérive des données ou des comportements inattendus du modèle.
- Suggestions intelligentes d’hyperparamètres : Applique l’apprentissage automatique pour recommander des valeurs optimales d’hyperparamètres en se basant sur l’historique des expériences, réduisant les essais manuels et accélérant l’optimisation du modèle.
- Requêtes sur les expériences en langage naturel : Permet aux utilisateurs de rechercher et de filtrer les expériences via un langage conversationnel, facilitant ainsi l’accès et la compréhension des résultats par les parties prenantes non techniques.
- Allocation prédictive des ressources : Utilise l’IA pour prévoir les besoins en calcul et en mémoire des prochaines exécutions, permettant aux équipes d’anticiper l’utilisation des ressources et d’éviter les blocages.
- Résumés automatisés d’expériences : Exploite l’IA pour générer des synthèses concises des résultats d’expériences, mettant en valeur les éléments clés et tendances pour un reporting et une prise de décision plus rapides.
Bénéfices des outils de suivi d’expériences ML
La mise en place d’outils de suivi d’expériences ML apporte de nombreux bénéfices à votre équipe et à votre entreprise. Voici quelques avantages auxquels vous pouvez vous attendre :
- Reproductibilité des expériences : Suivi des paramètres, jeux de données et détails d’environnement pour pouvoir recréer et valider aisément les expériences passées.
- Collaboration facilitée : Tableaux de bord partagés, commentaires et documentation projet aident les équipes à travailler ensemble et à communiquer efficacement les résultats.
- Développement de modèles accéléré : Comparaisons côte à côte des exécutions et versionnage automatique des artefacts accélèrent les cycles d’expérimentation et la prise de décision.
- Gestion centralisée de la connaissance : Tout l’historique du projet et les métadonnées expérimentales sont centralisés, préservant le savoir institutionnel à mesure que l’équipe s’agrandit.
- Conformité et audit améliorés : La traçabilité intégrée et les journaux d’audit répondent aux besoins réglementaires et aux standards de gouvernance d’entreprise.
- Maîtrise des coûts de ressources : Le suivi en temps réel des ressources et l’allocation prédictive permettent d’optimiser l’utilisation du matériel et d’éviter les dépenses inutiles.
- Support des workflows personnalisables : Les champs de métadonnées flexibles et les options de workflow s’adaptent aux processus existants et aux préférences de votre équipe.
Coûts et tarification des outils de suivi d’expériences ML
Choisir des outils de suivi d’expériences ML implique de bien comprendre les différents modèles et plans tarifaires proposés. Les coûts varient selon les fonctionnalités, la taille de l’équipe, les options supplémentaires, etc. Le tableau ci-dessous résume les plans courants, leurs prix moyens, et les fonctionnalités typiques incluses dans les solutions d’outils de suivi d’expériences ML :
Tableau comparatif des plans pour les outils de suivi d’expériences ML
| Type de plan | Prix moyen | Fonctionnalités courantes |
|---|---|---|
| Plan gratuit | $0 | Suivi d’expériences basique, utilisateurs limités, support communautaire et projets publics. |
| Plan personnel | $5-$25/utilisateur/mois | Expériences illimitées, stockage accru, projets privés et intégrations de base. |
| Plan entreprise | $30-$70/utilisateur/mois | Outils de collaboration en équipe, accès basé sur les rôles, intégrations avancées, sécurité renforcée et journaux d’audit. |
| Plan Entreprise | $80-$150/utilisateur/mois | Options de déploiement personnalisées, SSO/SAML, outils de conformité, support premium et personnalisation avancée. |
FAQ sur les outils de suivi d’expériences ML
Voici des réponses aux questions courantes sur les outils de suivi d’expériences ML :
Ces outils nécessitent-ils beaucoup de configuration ou de modifications de code ?
Non, la plupart des outils proposent des SDK ou des plugins légers permettant de commencer à enregistrer les expériences avec un minimum de modifications de code. Vous pouvez généralement intégrer le suivi dans vos scripts en quelques lignes seulement.
Comment ces outils aident-ils à la conformité et aux audits en équipe ?
Ils enregistrent les paramètres, le code et les résultats de chaque exécution, créent des historiques d’expériences traçables et maintiennent des pistes d’audit — ce qui facilite la documentation de la conformité et le partage de preuves lors de revues ou d’audits.
Ces solutions fonctionnent-elles avec les notebooks Jupyter ?
Oui, la plupart des outils de suivi d’expériences ML sont conçus pour fonctionner directement dans les notebooks Jupyter, ainsi qu’avec des scripts et pipelines, vous n’avez donc pas à modifier votre flux de travail.
Que se passe-t-il si mon équipe dépasse les limites du plan gratuit ?
Vous pouvez passer à une offre payante pour plus d’utilisateurs, des limites de stockage supérieures, des intégrations avancées et des fonctionnalités d’entreprise. Examinez attentivement les tarifs afin de ne pas être surpris lors de la transition.
Puis-je stocker des données sensibles ou propriétaires avec ces outils ?
Oui, mais il est nécessaire de vérifier les mesures de sécurité mises en place par le fournisseur, comme le chiffrement, le contrôle d’accès et les certifications de conformité, afin d’assurer la protection de vos données. Les options sur site ou cloud privé peuvent offrir un contrôle supplémentaire.