Métricas de DevOps para Medir el Éxito de Tus Procesos

Entonces, has comenzado a adoptar DevOps en tu empresa. Pero, ¿cómo puedes saber si está mejorando tus procesos? Debes medir el éxito de alguna manera, y puedes lograrlo monitoreando algunas métricas clave de DevOps.
Existen muchas maneras de evaluar la calidad de un sistema o aplicación, pero en este artículo me centraré en métricas clave que ayudan a evaluar la calidad de tus procesos. Al hacer seguimiento de estos indicadores, puedes obtener una visión más profunda de tus fortalezas y debilidades, mejorar tus mejores prácticas de DevOps y aprovechar las herramientas y software adecuados para una mejora continua.
¿Por qué son importantes las métricas de DevOps?
Como se descubrió anteriormente, los objetivos y métricas compartidos pueden ser un desafío para los equipos que implementan DevOps en una empresa. Sin métricas de DevOps, no habría pruebas ni mediciones, y tampoco mejoras en el desarrollo. Serían solo iteraciones del mismo software basadas en corazonadas e ideas, arrojándolo al vacío y luego intentando algo nuevo. Sin retroalimentación o métricas de éxito de producto para entender cómo funciona algo, no hay dirección.
Por ejemplo, los departamentos financieros quieren mantener los costos lo más bajos posible, mientras que los desarrolladores buscan mantener el rendimiento lo más alto posible. Estos dos objetivos pueden no estar alineados a menos que se hayan evaluado los riesgos y los equipos comprendan los objetivos de los demás.
Donde tus desarrolladores pueden optar por lanzar un producto incompleto y lidiar con ello más adelante, el costo de ese impacto genera deuda técnica. Implementar DevOps puede alinear los objetivos y estrategias de ambos equipos, y puedes ayudar a tus desarrolladores a entender el impacto de costos de sus decisiones técnicas.
Esto es solo una pequeña parte de DevOps y la importancia de las métricas compartidas.
5 Métricas Clave de DevOps (DORA)
Implementar DevOps y entender los marcos basados en principios es una cosa, pero las métricas de DevOps son donde realmente comienzas a ver los beneficios de este enfoque colaborativo del ciclo de vida del desarrollo de software. Como la mayoría de las estrategias comerciales, hay infinitas métricas que podrías elegir para medir el crecimiento, según tu industria, audiencia y objetivos.
El equipo de DevOps Research and Assessment (DORA) de Google Cloud es el equipo de investigación de este tipo con más trayectoria. Originalmente identificaron cuatro métricas clave para medir el rendimiento de los 'élite' en DevOps. Sin embargo, desde entonces se ha añadido una quinta métrica clave, y su análisis de clústeres solo detecta tres niveles de equipo DevOps: alto, medio y bajo, siendo el 'élite' cosa del pasado.
1. Frecuencia de Despliegue (DF)
DF mide con qué frecuencia realizas lanzamientos exitosos a producción. Esta métrica tiene que ver con la consistencia y es una excelente indicación del cumplimiento de objetivos.
Los equipos en la categoría ‘élite’ desplegarían en producción varias veces al día de manera constante, mientras que los equipos de bajo rendimiento estarían más cerca de una vez cada seis meses.
Mejorar la DF es tan simple como lanzar varias actualizaciones menores. El principal beneficio de hacer esto es resaltar cualquier bloqueo en los procesos, cuellos de botella o proyectos complejos que requieran atención. Los equipos más grandes pueden preferir desplegar a intervalos regulares creando trenes de lanzamiento ágiles; esto ayudará a eliminar la sobrecarga de un ritmo extremo y de muchas personas.
2. Lead Time para Cambios (LTC)
LTC se refiere al tiempo que le toma a un commit llegar a producción. Esta métrica es un buen indicador de la capacidad de respuesta y agilidad del equipo, ya que mide qué tan rápido pueden actuar sobre las necesidades y demandas de los usuarios.
El estándar legado ‘élite’ apuntaba a menos de un día para el LTC, mientras que los equipos de menor rendimiento podrían tardar más de seis meses. Un desempeño en el extremo inferior de la escala para LTC probablemente sea consecuencia de procesos ineficientes.
Puedes mejorar esta métrica optimizando los procesos de automatización, especialmente las pruebas. Al mejorar tu canalización de integración continua y entrega continua (CI/CD), puedes llevar las actualizaciones a producción más rápido. Sin embargo, un riesgo que hay que vigilar aquí es la sostenibilidad. Si tu equipo no puede mantener este ritmo mejorado, podrías enfrentar una mala experiencia de usuario y posibles vulnerabilidades de seguridad.
3. Tasa de Fallos por Cambio (CFR)
CFR es el porcentaje de implementaciones que provocan un fallo en producción. El fallo puede ser tiempo de inactividad, retrocesos o degradación del servicio. Esta métrica muestra la efectividad de tu equipo al implementar cambios.
Los puntos de referencia de rendimiento de élite son del 0 al 15%, donde el rendimiento alto, medio y bajo caen bajo el 16-30%.
Mejorar el CFR es cuestión de calidad sobre cantidad. Las empresas lanzan diferentes cantidades de cambios y, por lo tanto, tienen diferentes cantidades de fallos. Sin embargo, las modificaciones de mayor calidad resultarán en menos fallos, ya sea que implementen cambios dos veces al año o dos veces al día.
4. Tiempo Medio de Recuperación (MTTR)
MTTR es el tiempo que tarda tu equipo en restaurar el servicio tras una falla o interrupción. Esta métrica no solo mide la agilidad de tu equipo, sino que también es un buen indicador de la estabilidad de tu software.
Si aspiras a un nivel 'élite', deberías apuntar a menos de una hora para el MTTR. Los equipos de bajo rendimiento pueden tardar más de seis meses.
Puedes mejorar el MTTR centrándote en lanzamientos pequeños y rápidos, que hagan que los fallos sean más fáciles de encontrar y arreglar. También puedes explorar feature flags para dar a tu equipo más control, especialmente si son experimentales.
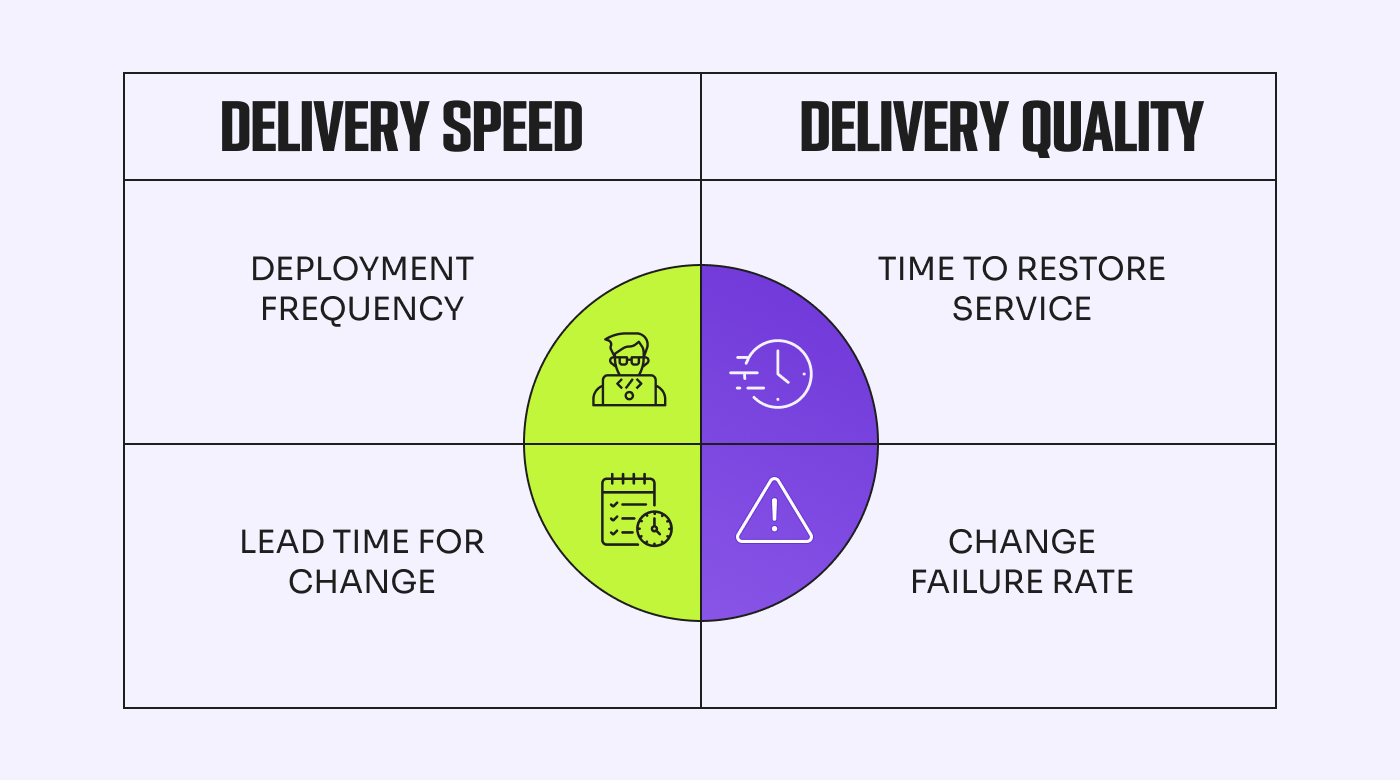
Falta una métrica más por cubrir.
5. Fiabilidad
La métrica extra número cinco es fiabilidad. Esta métrica fue descubierta más tarde por el equipo DORA (2021) debido a que previamente se medía la disponibilidad como referencia para un software fiable. Sin embargo, se decidió que la fiabilidad abarca mejor la disponibilidad, la latencia, el rendimiento y la escalabilidad. Es esencialmente la inclusión de la medición del rendimiento operativo junto con el desarrollo.
Otras Métricas Comunes de DevOps

Tiempo de Ciclo
El tiempo de ciclo es el tiempo total desde que se inicia una tarea hasta su entrega final. Superficialmente, rastrea la velocidad de trabajo de tu equipo. Sin embargo, puedes profundizar en esta métrica para encontrar cuellos de botella como tiempos de espera largos y pull requests prolongados.
Un tiempo de ciclo más corto indica un flujo de trabajo eficiente, reduciendo cuellos de botella y aumentando la velocidad de desarrollo.
Cómo Medir el Tiempo de Ciclo
El tiempo de ciclo se calcula rastreando marcas de tiempo de los commits, fusiones de código e implementaciones en herramientas como GitHub, GitLab o Jenkins.
Tiempo de Ciclo = Hora de Implementación - Hora del Commit
Para mejorar el tiempo de ciclo, los equipos deberían:
- Optimizar los pipelines de CI/CD para una integración e implementación más rápidas.
- Automatizar los builds y las pruebas.
- Mejorar la colaboración entre los equipos de desarrollo y operaciones.
- Reducir la dependencia entre tareas para minimizar cuellos de botella.
Tiempo Medio hasta la Detección (MTTD)
Este es el tiempo promedio que tarda tu equipo en reconocer un fallo. Un MTTD bajo indica sistemas de monitorización y alertas eficientes, permitiendo una respuesta y solución rápida ante incidentes.
Cómo Medir el MTTD
El MTTD puede medirse rastreando el tiempo promedio entre la ocurrencia de un problema y su detección por parte de herramientas de monitorización o por reportes de los usuarios. Para bajar el MTTD hay que mejorar la monitorización automática, perfeccionar los mecanismos de alertas y garantizar la detección proactiva de problemas.
Pruebas Automatizadas Aprobadas
Es importante aspirar a una buena cobertura de pruebas, especialmente automatizadas. Y aquí me refiero a pruebas unitarias, de integración, de UI y de extremo a extremo. Sin embargo, una buena cobertura no basta para asegurar la calidad del software. Lo que importa es el porcentaje de estas pruebas que se aprueban.
Por supuesto, el objetivo es tener un porcentaje de pruebas aprobadas lo más cercano posible al 100%. Monitorizar esta métrica también puede revelar con qué frecuencia los nuevos desarrollos rompen pruebas existentes.
Cómo Medir el Porcentaje de Pruebas Automatizadas Aprobadas
El cálculo es un porcentaje simple: multiplica el número de pruebas aprobadas por 100, y luego divide por el número total de pruebas. Puedes obtener esta información de la herramienta de pipelines que ejecuta los builds (Jenkins, Azure DevOps, CircleCI, etc.).
El número puede ser un buen indicador de la calidad del producto. Sin embargo, también puede resultar engañoso si tienes pruebas inestables o poco fiables.
Tasa de Fugas de Defectos
La tasa de fugas de defectos indica cuántos errores no se detectan durante las pruebas y se lanzan a producción, es decir, cuántos se "escaparon". Esta métrica es ideal para hacer un seguimiento si deseas mejorar los procesos de pruebas y automatización.
En un mundo utópico, todas nuestras aplicaciones estarían libres de defectos. Sin embargo, esto rara vez es el caso. Lo ideal es que los defectos se detecten durante las fases de desarrollo y pruebas del proceso DevOps, no en producción.
Esta métrica ayuda a determinar la eficacia de tus procesos de pruebas y la calidad general de tu programa. Una alta tasa de fugas de defectos sugiere que los procedimientos deben mejorarse y que se necesita más automatización, mientras que una tasa baja (idealmente cerca de cero) implica una aplicación de alta calidad.
Cómo Medir la Tasa de Fugas de Defectos
Para medir esto, puedes usar tu herramienta de seguimiento de errores y, para cada defecto abierto, rastrear dónde se ha detectado: si en el entorno de pruebas, de producción o en cualquier otro entorno que utilices, como UAT.
Tickets de Clientes
La satisfacción del cliente es un elemento impulsor de la innovación, y con buena razón: una experiencia de usuario impecable es un buen servicio al cliente y, normalmente, corresponde a un aumento en las ventas. Por ello, los tickets de clientes, especialmente durante el proceso de escalado de tickets, son un buen indicador de cómo va tu transición a DevOps.
Los clientes no deberían actuar como control de calidad informando sobre defectos y errores. Por lo tanto, una disminución en los tickets de clientes es una buena señal de un buen rendimiento de la aplicación.
Uso de CPU y Memoria
Identifica tendencias en la utilización de recursos.
Tiempo de Respuesta
Mide el tiempo que tarda la aplicación en responder a las solicitudes.
Tasa de Errores
Supervisa la cantidad de solicitudes fallidas a lo largo del tiempo.
Rendimiento (Throughput)
Mide el número de solicitudes procesadas por segundo.
Latencia de Solicitudes API
Mide el retraso entre el envío de una solicitud y la recepción de una respuesta.
Rendimiento de Consultas de Base de Datos
Supervisa los tiempos de ejecución de consultas y posibles cuellos de botella.
Análisis del Comportamiento del Usuario
Monitorea la adopción de funcionalidades y tendencias de uso.
Tiempo Medio Entre Fallos (MTBF)
MTBF mide el tiempo promedio transcurrido entre fallos, periodos de inactividad o incidentes del sistema. Esta métrica evalúa la fiabilidad y estabilidad de tus sistemas de software, poniendo en evidencia la eficacia de tu mantenimiento preventivo y de las estrategias de mitigación de errores.
Tiempo de Mitigación (TTM)
El tiempo que se tarda en solucionar un problema una vez detectado es el TTM. Esta métrica ayuda a valorar los procesos de respuesta y resolución de incidencias, indicando la eficiencia de tus equipos para abordar y recuperarse de problemas.
Tiempo de Ciclo de Cambio (CLT)
CLT proporciona un punto de referencia para el proceso completo de implementación de cambios, incluyendo desarrollo, pruebas, revisión y despliegue. Un CLT más corto significa ciclos de entrega más rápidos y mayor agilidad.
Cómo Establecer KPIs con Métricas DevOps
Ahora que tienes una buena comprensión de las métricas que puedes utilizar para implementar y optimizar DevOps en tu empresa, querrás explorar los indicadores clave de desempeño (KPIs) para establecer metas y puntos de referencia para tu equipo.
Métricas vs. KPIs
Quizá te preguntes cuál es la diferencia entre métricas y KPIs. Una métrica es lo que mides. Es una medición cuantificable que proporciona datos sobre un aspecto específico del desempeño. No todas las métricas están necesariamente vinculadas a objetivos o metas específicas.
Por otro lado, los KPIs son un tipo de métrica seleccionada y definida estratégicamente para reflejar los aspectos más críticos del rendimiento y el progreso hacia los objetivos estratégicos. Los KPIs suelen estar asociados a objetivos y, a menudo, tienen metas, umbrales o puntos de referencia asociados que deben cumplirse.
Establecimiento de KPIs para tu equipo DevOps
El primer paso para establecer KPIs en tu equipo DevOps es vincular las métricas de DevOps con la estrategia y los objetivos de tu negocio. Al priorizar las métricas más esenciales que se deben monitorear, puedes comenzar a establecer objetivos y referencias para la mejora continua. Seleccionar las métricas adecuadas requiere considerar el tamaño de tu empresa, el producto y el mercado. Concéntrate en lo que brindará las perspectivas más útiles, evitando el error común de sobrecarga de métricas.
Monitorear tus KPIs es tan importante como establecerlos. Explora herramientas de visualización de datos para proporcionar a tu equipo datos en tiempo real en paneles de control intuitivos. Esto garantiza visibilidad total, proporciona responsabilidad y permite que todos trabajen juntos hacia metas compartidas, alineando los equipos de desarrollo y operaciones, y apoyando la adopción y madurez de DevOps.

Tomando las métricas principales de DORA, podemos ver los valores de referencia para cada métrica según equipos de alto, medio, bajo y élite desempeño. Esta tabla puede ayudarte a establecer KPIs para tu propio negocio, dependiendo de lo que tú consideres prioritario.
Al establecer tus KPIs, lo mejor es considerar cuidadosamente tu equipo y negocio sin compararlos con otras empresas. Si tomamos el CFR como ejemplo, el valor de referencia es el mismo para alto, medio y bajo rendimiento. Esto dependerá en gran medida de tu frecuencia de despliegue, pero también puede afectar de manera inversa. Si tu equipo pasa todo el tiempo corrigiendo fallos, dedicará menos tiempo a desarrollar y lanzar actualizaciones. Los KPIs también pueden cambiar a medida que tu equipo DevOps madura. Los procesos automáticos y pruebas rigurosas deberían permitirte aumentar los estándares de tus objetivos.
Cómo usar métricas DevOps para escalar
Con el mercado global de DevOps que se espera alcance $24.71 mil millones para 2027 (una tasa de crecimiento anual compuesta del 22.9%, basada en el tamaño de mercado de $10.84 mil millones en 2023), tómatelo como una señal si estás buscando el mejor momento para comenzar a implementarlo en tu negocio.
DevOps no solo acelera el desarrollo, reduciendo el time-to-market, sino que también mejora la colaboración eliminando silos, mejora la calidad con pruebas y retroalimentación continuas, y utiliza los recursos de manera eficiente, lo que ahorra dinero. Por último, es fácilmente escalable, permitiendo el crecimiento empresarial a nuevos límites, con el 83% de los responsables de IT obteniendo mayor valor para su negocio al implementar DevOps en 2021.
Medición de rendimiento y mejora continua
Monitorear el rendimiento es clave para escalar un negocio que utiliza DevOps. Es un enfoque de ritmo rápido con un flujo de trabajo de producción constante, por lo que la medición y los reportes deben ser igual de frecuentes. Las métricas DevOps te permiten rastrear el rendimiento de tus procesos de desarrollo y entrega. Al cuantificar aspectos clave como la frecuencia de despliegue, el lead time y la tasa de fallos por cambio, puedes identificar cuellos de botella, ineficiencias y áreas de mejora. Esto te permite optimizar flujos de trabajo y procesos de manera frecuente.
Rastrear métricas como la tasa de fallos por cambio y el tiempo medio de recuperación ayuda a identificar tendencias que te permiten detectar problemas a tiempo. Este enfoque proactivo significa que puedes tomar medidas correctivas y minimizar el impacto en los clientes, proporcionando fiabilidad, otro ingrediente esencial para escalar con alta calidad.
Finalmente, utilizar las métricas DevOps ayudará a madurar tu equipo promoviendo una cultura de mejora continua. Los ciclos de retroalimentación favorecen el aprendizaje y el crecimiento; siempre debe haber espacio para experimentar con diferentes enfoques.
¿Qué métricas DevOps impulsan el crecimiento empresarial?
Al establecer KPIs, la mayoría de las métricas deben considerarse dentro de tu equipo y orientadas al crecimiento, en lugar de compararlas con otras empresas y grupos con diferentes niveles de madurez.
Por ejemplo, un LTC bajo podría indicar que tu equipo es eficiente, pero si no pueden mantener ese ritmo, no es sostenible y podría afectar la experiencia del usuario. Esta métrica se debería medir a lo largo del tiempo, en lugar de establecer un KPI para igualar a equipos DevOps de alto o incluso élite rendimiento. Fijar KPIs para reducir el LTC mes a mes, trimestral o anualmente demuestra crecimiento interno en tu equipo y negocio.
El CFR es una métrica valiosa porque no todos tienen la misma cantidad de fallos o problemas, pero al expresar esto en un porcentaje, puedes medir cuán exitosas son tus implementaciones. Tu equipo puede tener muy pocos fallos si publica cambios de manera poco frecuente, pero si cada publicación causa un problema, el CFR será muy alto. Si sigues prácticas de CI/CD, es posible que veas un número mayor de fallos, pero si tu CFR es bajo, tendrás ventaja porque tendrás velocidad y calidad impulsando el crecimiento. El MTTR también debe medirse con el tiempo para asegurar un crecimiento constante.
DORA descubrió que equipos de todos los niveles de desempeño en desarrollo obtuvieron mejores resultados al enfocarse en el rendimiento operativo. Esto podría significar establecer KPIs para reportes de incidentes o tickets abiertos, tiempo de actividad de la aplicación y disponibilidad.
Un alto número de tickets abiertos podría representar un problema con la satisfacción de tus clientes, pero apuntar a una disminución a lo largo del tiempo refleja crecimiento en esta área. Puedes profundizar y medir los tiempos de respuesta y de espera para acelerar la mejora de esta métrica.
La métrica que combina tanto el desarrollo como las operaciones en un equipo DevOps es el tiempo de ciclo. Esto abre el espacio para construir una cultura de retroalimentación y crecimiento. A medida que otras métricas mejoran y la automatización madura, deberías esperar que el tiempo de ciclo disminuya. Si tu servicio al cliente es alto y los fallos de desarrollo son bajos, has encontrado la combinación ganadora para escalar tu negocio.
Reflexiones finales
Como cualquier otra metodología, DevOps solo tendrá éxito si se implementa correctamente. Y no puedes saber el éxito hasta que sepas cómo utilizar las métricas de DevOps.
Por supuesto, implementar métricas de DevOps tiene sus desafíos. Requiere una mentalidad estratégica, una cultura colaborativa y compromiso con la mejora continua. Sin embargo, los resultados son flujos de trabajo y procesos optimizados sobre los que puedes construir una base sólida para escalar tu negocio.
¡Si quieres mantenerte actualizado con noticias y artículos, suscríbete a nuestro boletín!


{kind=link}