3 métricas de monitoreo de servidores que debes seguir para la salud del sistema

La garantía de calidad requiere una combinación de medidas proactivas y protocolos reactivos eficientes. Con el equilibrio adecuado, puedes ofrecer a los usuarios un servicio y una funcionalidad excelentes en un servidor disponible durante todo el año. La única forma de lograr ese equilibrio es identificando las métricas de monitoreo de servidores más relevantes.
¿Pero cuáles podrían ser esas métricas? Eso depende de los atributos que busques, incluidos los descritos en el Modelo de Madurez de Calidad, y tus objetivos de monitoreo. Aun así, hay algunas métricas de salud y rendimiento que los ingenieros de QA siempre deben vigilar, sin importar qué.
Al seleccionar desde el principio las métricas ideales de monitoreo del servidor, puedes desarrollar una línea base de rendimiento que te servirá como referencia cuando inevitablemente surjan problemas de salud o desempeño.
En esta breve guía analizaremos por qué deberías rastrear estas métricas clave. Además, obtendrás información adicional sobre su relevancia y cómo monitorizarlas.
1. Uso de CPU
Uno de los principales motivos para el monitoreo de servidores es vigilar la salud de la infraestructura y el rendimiento básico del servidor. Una parte crítica de esto es el diagnóstico proactivo y la mitigación de posibles problemas de rendimiento. La medición del uso de CPU y del disco es fundamental para estos esfuerzos. Por ello, el uso de CPU es una de las métricas de rendimiento más fundamentales y comúnmente monitorizadas.
Esta métrica se considera “basada en el host”, ya que lleva un registro de la capacidad de una máquina individual para rendir y permanecer estable. Dicho esto, monitorear el uso de CPU implicará una combinación de monitoreo pasivo y activo. El segundo es especialmente útil para pruebas de carga controladas, mientras que el primero recopila mediciones en el objetivo durante el tráfico real.
Cómo medir la utilización de la CPU
Antes de empezar, debes:
- Seleccionar las unidades específicas que deseas monitorear.
- Determinar dónde se encuentran esas unidades.
- Asegurarte de que tu recolector de datos tenga acceso a los procesos de tu equipo.
Una vez que tengas todo configurado, tendrás que determinar la frecuencia de muestreo a la que quieres rastrear estas métricas. Por ejemplo, podrías medir el uso de CPU cada 30 segundos o cada minuto.
Existen varias formas de monitorear el uso de la CPU, como utilizar tu administrador de tareas o un comando como wmic CPU get load percentage en sistemas Windows. Sin embargo, cuando buscas una visión general de tu servidor, lo mejor es mostrar estos datos en un panel de control.
Recuerda: El rendimiento de la CPU está influenciado por las condiciones del hardware, como la temperatura de la CPU y la velocidad del ventilador. Quizá quieras monitorear estos factores junto con la utilización (representada como porcentaje) en estos dos estados, ignorando el estado de inactividad.
| Ocupado | Durante este tiempo, la CPU está ejecutando una tarea. |
| I/O | Este estado no está ocupado, pero tampoco inactivo. En vez de eso, la CPU podría estar esperando una operación de I/O para ejecutar una tarea, normalmente esperando para enviar o recibir datos. |
Dos factores clave que querrás monitorear de cerca son el Tiempo de Privilegio y el Tiempo de Usuario, ya que la suma de estos dos te dará el Tiempo de Procesador, definidos así:
- Tiempo de Privilegio: Porcentaje de tiempo que los procesadores dedican a ejecutar procesos que no son de usuario (es decir, procesos del kernel)
- Tiempo de Usuario: Porcentaje del tiempo que los procesadores utilizan para ejecutar procesos de usuario (por ejemplo, la consola de comandos, el servidor de correo electrónico, el compilador)
- Tiempo de Procesador: Cantidad total de tiempo que la CPU estuvo ocupada
Ten en cuenta que sobrepasar el 100% no siempre significa que un sistema está sobrecargado. Por ejemplo, si tienes un sistema multiprocesador, esto simplemente indica que la suma de dos o más CPUs es mayor al 100% (por ejemplo, 50% y 60%). Vigila el rendimiento individual para mantener la salud del sistema.
Junto con la utilización de CPU y disco, las esperas también son consideradas esenciales en el monitoreo de la salud y el rendimiento de la infraestructura.

Esperas
Las esperas te ayudan a saber qué tan eficientemente se ejecutan las tareas y te alertan sobre posibles cuellos de botella. Pero sólo saber el valor de esperas no será suficiente. Deberás investigar más para identificar el problema exacto de rendimiento.
Las esperas altas pueden estar bien en picos, porque puede haber tareas intensivas en ejecución, pero cualquier cosa más allá de eso normalmente es motivo de preocupación.
2. Tiempo de actividad del servidor
Tu servidor no sirve de nada si no está disponible para tus usuarios. Por ello, monitorear el tiempo de actividad del servidor no es negociable. Cada vez que la disponibilidad de tu servidor caiga por debajo del 99.999% (el estándar conocido como “cinco nueves”), tienes un problema serio entre manos.
Utiliza las siguientes fórmulas para obtener información comprensible y accionable de tus esfuerzos de monitoreo.
Cómo medir el tiempo de actividad del servidor
Aquí tienes algunos conceptos clave que debes conocer al monitorear el tiempo de actividad del servidor:
- Tiempo de actividad: La cantidad de tiempo que tu servicio o aplicación está activo y disponible para los usuarios. Fórmula: (Tiempo total - Tiempo de inactividad)/Tiempo total
- Tiempo medio entre fallos (MTBF): El tiempo promedio entre incidentes de inactividad. Fórmula: (Tiempo total - Tiempo de inactividad)/Número de incidentes de inactividad
- Tiempo medio de resolución (MTTR): El tiempo promedio necesario para resolver una caída del servicio. Fórmula: Tiempo total de inactividad/Número de incidentes de inactividad
- Tiempo medio de reconocimiento (MTTA): El tiempo promedio necesario para reconocer una caída actual. Fórmula: Tiempo total de reconocimiento/Número de incidentes de inactividad
Todas estas métricas ayudan a desarrollar una visión general sobre la fiabilidad de tu infraestructura y la capacidad de respuesta de tu equipo.
Por ejemplo, tener un MTTR y MTTA saludables es positivo. Pero si también tienes un MTBF alto, tendrás que investigar más a fondo las causas que originan los periodos de inactividad de tu servidor. De lo contrario, la empresa seguirá estando en riesgo de sufrir importantes pérdidas económicas y de dañar la confianza de los usuarios.
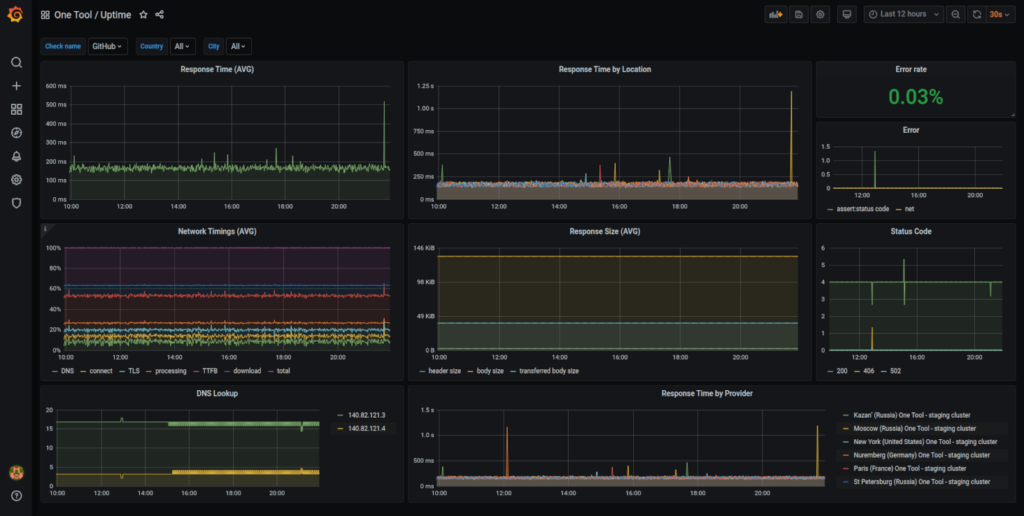
En última instancia, debes aspirar a lograr los “cinco nueves”, manteniendo el tiempo de inactividad en un máximo de aproximadamente cinco minutos por año. El software de monitoreo de servidores como Grafana y Prometheus son ambos altamente recomendados por ser herramientas accesibles y fáciles de usar para este aspecto del monitoreo del rendimiento.
3. Transacciones (y tasas de error)
Necesitas una visión clara de cuántas solicitudes soporta tu infraestructura en un momento dado. Por eso es fundamental estar atento a las transacciones, o número de solicitudes por segundo, y al tiempo medio de respuesta correspondiente. Esta información te ayudará a determinar la cantidad de recursos y la capacidad necesarias para que el servidor funcione sin problemas.
Al mismo tiempo, realizar un seguimiento de la tasa de error, o el porcentaje de solicitudes fallidas en relación con el total recibido, puede ofrecer más información sobre la capacidad de carga de tu servicio. Para maximizar el valor de esta métrica, lo mejor es desarrollar una línea base a lo largo del tiempo mediante monitoreo pasivo.
Esto es crucial para tu capacidad de vigilar las tendencias. Si puedes revisar y determinar la capacidad máxima y los recursos necesarios para una operación fluida, puedes actuar de manera proactiva para asignar esos recursos y detectar problemas de infraestructura que ayuden a reducir las tasas de error observadas y optimizar el tiempo de respuesta medio.
Cómo monitorear transacciones y tasas de error
Las siguientes son herramientas fiables para técnicas de monitoreo pasivo del rendimiento:
- Sniffers: Están diseñados para recoger mediciones a un “nivel microscópico” al “escuchar” el flujo de tráfico en redes cableadas e inalámbricas. Wireshark es uno de los estándares más reconocidos y recopila datos de atributos como marca de tiempo, direcciones MAC e IP, tiempo de vida y más. Estos pueden utilizarse tanto online como offline.
- Facilidades de registro (logging facilities): Suelen estar integradas en los sistemas operativos y aplicaciones. Principalmente recopilan información sobre las actividades y eventos generados por las aplicaciones para su uso sin conexión.
Una de las diez mejores herramientas para el monitoreo de servidores web que destaca especialmente en el monitoreo de transacciones es Monitis. Es un sistema de monitoreo integral para servidores, sitios web y aplicaciones. Es adecuado tanto para sistemas Windows como Linux, y resulta ideal para cubrir lo básico, incluido el monitoreo de tiempo de actividad.
El objetivo y las metas del monitoreo influirán en las mediciones exactas y en el uso de estas técnicas.
Otras métricas a monitorear con las transacciones
Tiempo de respuesta y el número total de hilos están relacionados directamente con las transacciones. Estas métricas te indican cuánto tarda tu servidor en responder a una solicitud y la cantidad de hilos (que permiten que las transacciones ocurran) que se están utilizando para gestionar todas esas solicitudes.
Cada hilo consume tiempo de CPU y RAM. Demasiados pueden derivar en un rendimiento deficiente. Hay mucho que monitorear aquí, incluyendo:
- El número total de hilos en un servidor web o grupo de contenedores, incluidos estos tipos:
- Activos
- Inactivos
- Atascados
- En espera
- Solicitudes de usuario pendientes y longitud de la cola
Normalmente se puede medir el tiempo de respuesta del servidor como Tiempo hasta el Primer Byte (TTFB). Este es el número de milisegundos que tarda un navegador en recibir el primer byte de respuesta del servidor. En general, cualquier valor superior a cinco segundos es crítico.
Cómo elegir los indicadores adecuados para monitorizar el rendimiento del servidor
Existe una larga lista de métricas que podrías monitorizar al seguir la salud y el rendimiento de tu servidor, pero los objetivos específicos dependen principalmente de la finalidad de tus actividades de monitorización.
Mientras que algunas son mejores para obtener información sobre la capacidad de carga de tu hardware y sistema operativo, otras resultan ideales para observar la actividad de los usuarios. En cualquier caso, la CPU, el tiempo de actividad y las transacciones son fundamentos que no se pueden pasar por alto.
A medida que avances como líder de control de calidad (QA) y tus objetivos inevitablemente cambien, sin duda añadirás más métricas de monitorización del servidor a tu panel. Para obtener más información experta sobre cuáles deberían ser esas métricas y cómo gestionarlas, suscríbete al boletín.


{kind=link}