I 10 migliori strumenti per il deployment di modelli ML nel 2026

Elenco dei migliori strumenti per il deployment di modelli ML


Gli strumenti per il deployment di modelli ML ti permettono di trasformare i modelli di machine learning addestrati in servizi pronti per la produzione e realmente utilizzabili. Se stai cercando soluzioni affidabili per lanciare, monitorare e gestire le tue app basate sull’intelligenza artificiale, la scelta della giusta piattaforma di deployment è fondamentale. Sicurezza, scalabilità, automazione e trasparenza possono incidere profondamente sul tuo flusso di lavoro. In questo elenco, suddividerò gli strumenti di deployment ML di cui mi fido di più e ti mostrerò esattamente dove si inseriscono nel tuo stack, così potrai scegliere la piattaforma che meglio si adatta alle esigenze del progetto e alle aspettative del tuo team.
Table of Contents
Perché Fidarti delle Nostre Recensioni Software
Testiamo e recensiamo software dal 2023. Come leader tecnologici, sappiamo quanto sia cruciale e difficile prendere la decisione giusta nella scelta di un software.
Investiamo in una ricerca approfondita per aiutare il nostro pubblico a effettuare scelte migliori di acquisto software. Abbiamo testato oltre 2.000 strumenti per diversi casi d’uso tecnologici e scritto più di 1.000 recensioni complete. Scopri come restiamo trasparenti e la nostra metodologia di recensione del software.
Riepilogo dei migliori strumenti per il deployment di modelli ML
Questa tabella di confronto riassume i dettagli dei prezzi delle mie principali scelte di strumenti per il deployment di modelli ML per aiutarti a trovare quello più adatto al tuo budget e alle esigenze della tua azienda.
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | Ideale per l'orchestrazione di modelli nativi su Kubernetes | Piano gratuito disponibile | Gratuito e open source | Website | |
| 2 | Ideale per API di inferenza standardizzate su Kubernetes | Gratis per sempre | Gratis per sempre | Website | |
| 3 | Ideale per pacchettizzare modelli come API di produzione | Piano gratuito + demo gratuita disponibile | Prezzo su richiesta | Website | |
| 4 | Ideale per l'hosting di modelli transformer su larga scala | Piano gratuito + demo gratuita disponibile | A partire da $9/mese | Website | |
| 5 | Ideale per il deployment di funzioni Python serverless | Piano gratuito disponibile | Da $250 + calcolo/mese | Website | |
| 6 | Ideale per la gestione automatizzata end-to-end dei modelli | Piano gratuito disponibile | Prezzi su richiesta | Website | |
| 7 | Ideale per workflow unificati tra dati e AI | $300 di credito gratuito disponibili | Prezzo su richiesta | Website | |
| 8 | Ideale per creare interfacce web personalizzate per modelli | Piano gratuito disponibile | Prezzo su richiesta | Website | |
| 9 | Ideale per il serving distribuito con Python e Ray | Credito gratuito di $100 disponibile | Prezzi su richiesta | Website | |
| 10 | Ideale per la gestione dei modelli nei settori regolamentati | Not available | Prezzi su richiesta | Website |
-

TestDevLab
Visit Website -
Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8


Recensioni dei migliori strumenti per il deployment di modelli ML
Di seguito trovi i miei riepiloghi dettagliati dei migliori strumenti per il deployment di modelli ML che sono entrati nella mia shortlist. Le mie recensioni offrono uno sguardo dettagliato alle funzionalità, alle integrazioni e ai migliori casi d’uso di ciascuna piattaforma per aiutarti a trovare quella più adatta a te.
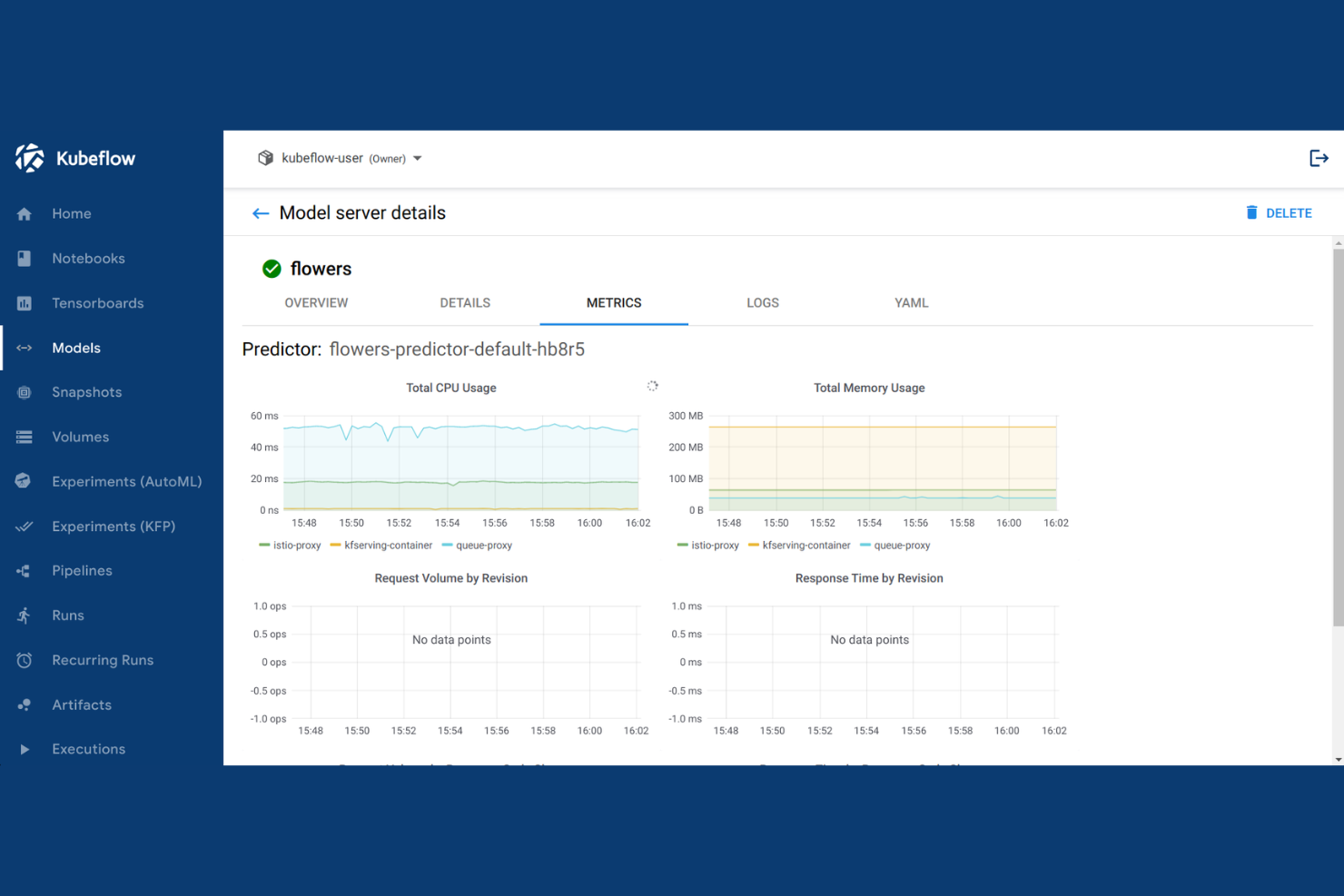
Kubeflow è una piattaforma ML open-source basata su Kubernetes che copre l'orchestrazione delle pipeline, l'addestramento dei modelli, l'ottimizzazione degli iperparametri e il servizio di modelli multi-framework su infrastrutture cloud e on-premises.
Per chi è ideale Kubeflow?
Kubeflow è particolarmente indicato per team di ingegneria ML che già utilizzano Kubernetes e necessitano di gestire lavori di addestramento su larga scala e la messa in produzione dei modelli sulla propria infrastruttura.
Perché ho scelto Kubeflow
Ho scelto Kubeflow tra i migliori perché è costruito appositamente attorno a Kubernetes, il che significa che ogni componente viene eseguito come workload nativo di Kubernetes. Mi piace che Kubeflow Pipelines mi permetta di definire workflow ML end-to-end come DAG containerizzati, in modo che ogni fase possa scalare indipendentemente. Kubeflow Trainer gestisce l'addestramento distribuito tra PyTorch, JAX e DeepSpeed senza necessità di configurare manualmente il cluster. Posso anche usare Katib per eseguire sweep automatici degli iperparametri direttamente sui job di addestramento in esecuzione nello stesso cluster.
Funzionalità principali di Kubeflow
- KServe: Distribuisce modelli addestrati come servizi di inferenza scalabili su Kubernetes utilizzando runtime di serving preconfigurati per TensorFlow, PyTorch e scikit-learn.
- Registro modelli: Archivia, versiona e traccia i modelli registrati nei vari run di addestramento prima di promuoverli in ambienti di serving.
- Server di notebook: Avvia istanze di notebook Jupyter direttamente sul cluster con allocazioni configurabili di CPU, GPU e memoria.
- Isolamento multi-utente: Gestisce namespace separati e controlli di accesso per diversi team o progetti all'interno di un cluster condiviso.
Integrazioni di Kubeflow
Kubeflow non offre integrazioni native tradizionali nel senso SaaS, ma la sua architettura nativa Kubernetes permette la connessione con un ampio ecosistema di strumenti ML e infrastrutturali. Kubeflow Trainer supporta l'addestramento distribuito su framework come PyTorch, HuggingFace, DeepSpeed, JAX e XGBoost. KServe supporta il protocollo OpenAI, garantendo compatibilità con le librerie client OpenAI e strumenti come LangChain e LlamaIndex. Kubeflow Pipelines funziona sia con Argo Workflows sia con Tekton come backend e la piattaforma si integra con strumenti di scheduling Kubernetes come Kueue, Volcano e YuniKorn. Anche Metaflow si integra con Kubeflow, permettendo di distribuire i flussi Metaflow come Kubeflow Pipelines. È inoltre in corso un'integrazione sperimentale con MLflow come sottoprogetto di Kubeflow.
Pros and Cons
Pros:
- Distribuibile su tutti i principali provider cloud Kubernetes
- Ogni step della pipeline gira in un container isolato
- Ottimi risultati in addestramento distribuito e orchestrazione
Cons:
- Configurazione iniziale complessa, serve competenza in Kubernetes
- Richiede un team di piattaforma dedicato per la manutenzione
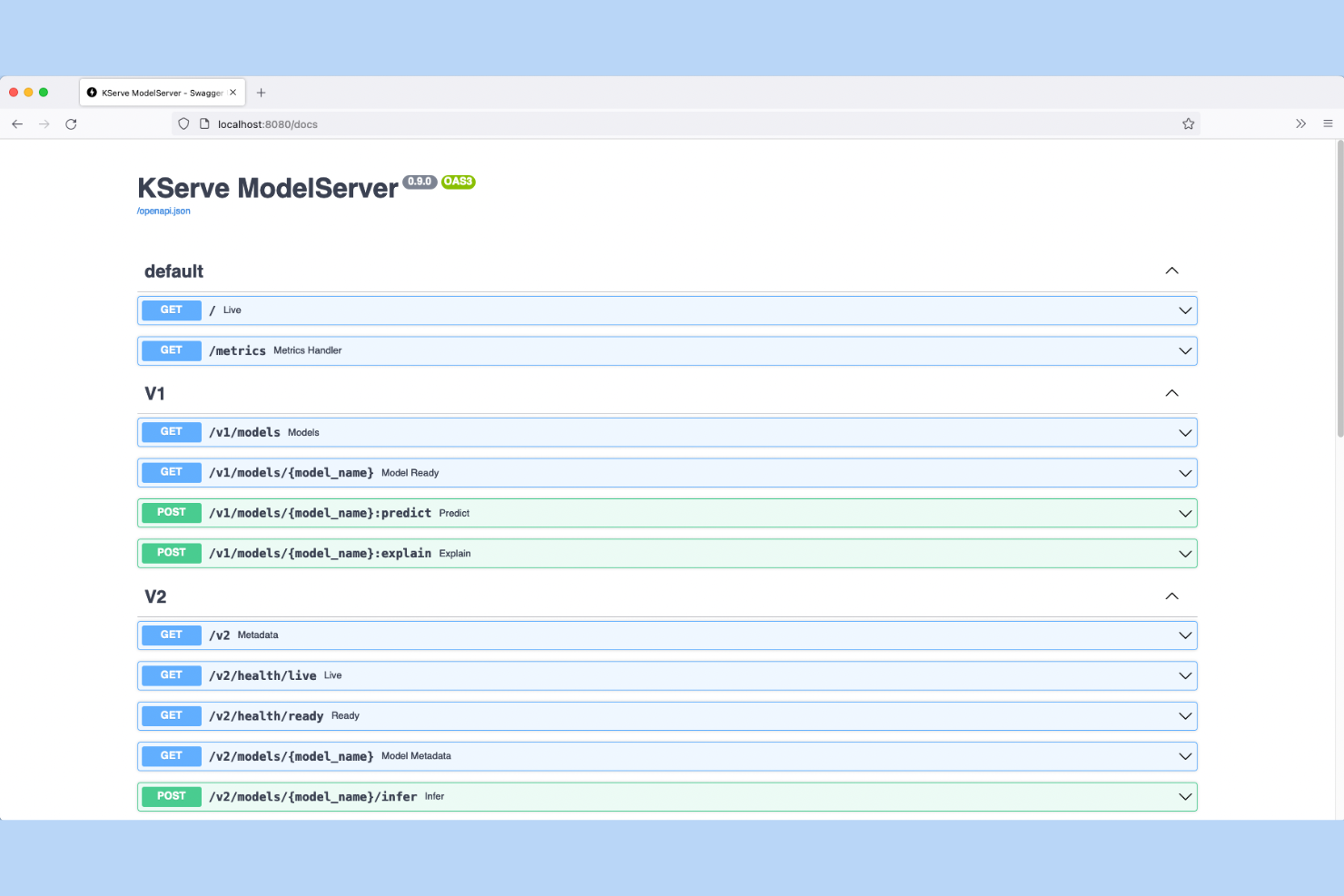
KServe è una piattaforma open-source nativa per Kubernetes per il deployment e l’inferenza di modelli, in grado di gestire il serving di modelli di diversi framework, rollout canarini, autoscaling e spiegabilità dei modelli tramite un layer API di inferenza standardizzato.
A chi è più adatto KServe?
KServe è particolarmente indicato per i team di ingegneria ML di aziende di medie e grandi dimensioni che eseguono il serving di modelli su larga scala su Kubernetes e necessitano di un livello di inferenza indipendente dal framework.
Perché ho scelto KServe
Ho scelto KServe tra i migliori perché è basato sull’Open Inference Protocol (V2), una specifica API standardizzata che permette al mio team di sostituire backend per il serving, come Triton o vLLM, senza dover riscrivere il codice client. Mi affido inoltre al suo InferenceService CRD per definire in modo dichiarativo i rollout canarini, reindirizzando una percentuale di traffico reale verso una nuova versione del modello prima della promozione completa. Sono supportati sia gli endpoint di inferenza REST che gRPC, quindi non sono vincolato a un unico strato di trasporto.
Funzionalità principali di KServe
- Autoscaling con scala a zero: L’autoscaling basato su Knative porta i pod di inferenza a zero quando non utilizzati e li riattiva su richiesta.
- Trasformatori di richieste/risposte: La logica di pre- e post-processing viene eseguita in un container trasformatore separato affiancato al server del modello.
- Rollout canarini: Sposta gradualmente il traffico su una nuova versione del modello, consentendo di testare le modifiche in produzione senza esposizione totale.
- Registrazione dei payload: Le richieste e risposte di inferenza vengono registrate su sink configurabili per audit trail e monitoraggio del modello.
Integrazioni KServe
KServe include integrazioni native con Knative, Istio e l’API Kubernetes Gateway per lo scaling serverless e il routing di ingresso. Offre runtime integrati per vLLM, llm-d, NVIDIA Triton Inference Server, Seldon MLServer, TorchServe e Hugging Face, e supporta l’archiviazione dei modelli su Amazon S3, Google Cloud Storage e Azure Blob Storage. Sono disponibili un SDK per Python Serving e API REST/gRPC per inferenza per integrazioni personalizzate.
Pros and Cons
Pros:
- Autoscaling con scala a zero per ridurre i costi GPU a riposo
- Serving indipendente dal framework tramite protocollo di inferenza standardizzato
- Rollout canarini integrati per aggiornamenti sicuri
Cons:
- Richiede competenza nella gestione di cluster Kubernetes
- La modalità serverless limita la personalizzazione dei mount di volume
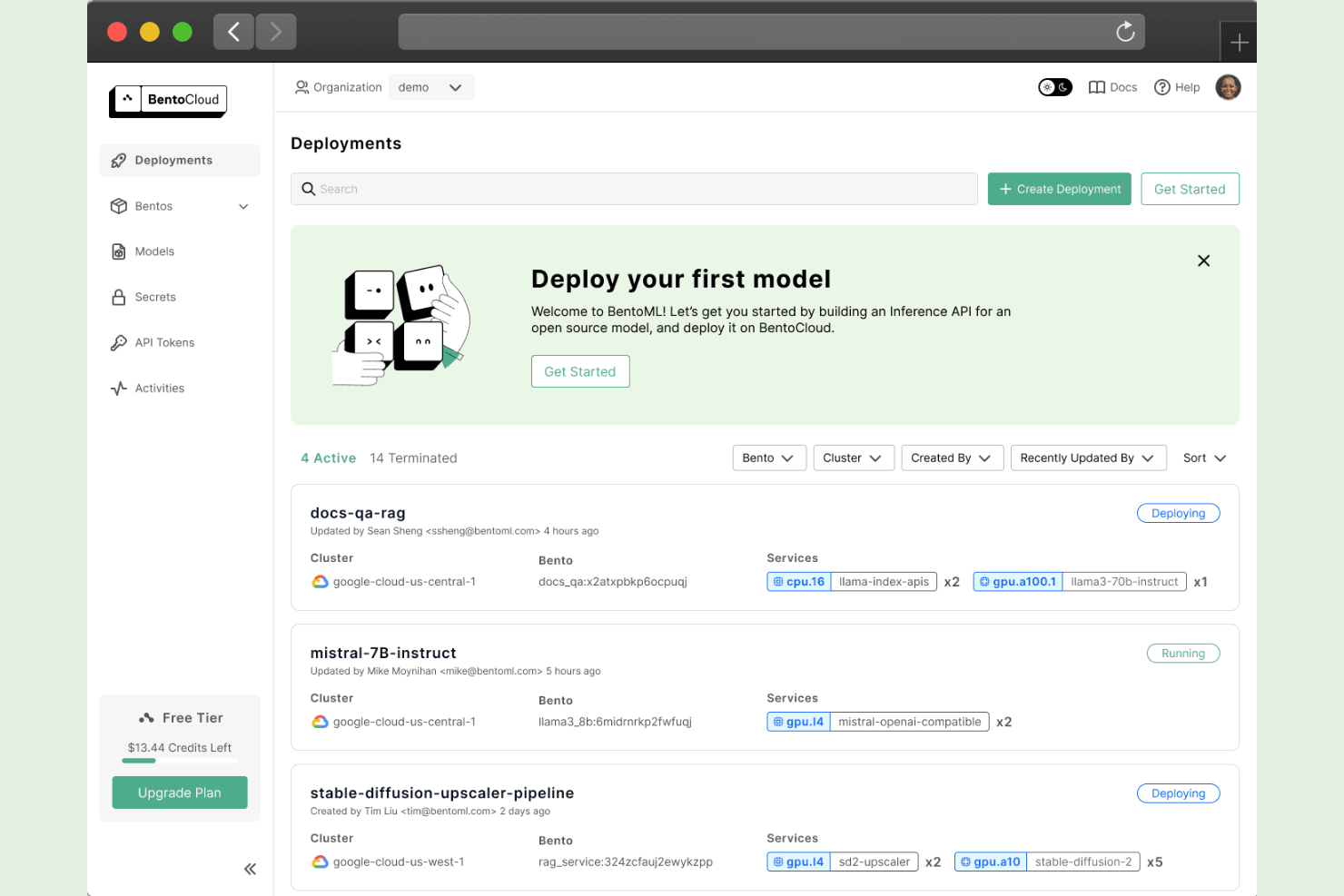
Basato sul concetto di artefatto 'Bento', BentoML è un framework per il serving di modelli nativo in Python che gestisce la definizione dei servizi, la containerizzazione e il packaging di modelli multi-framework per il deployment in produzione.
Per chi è ideale BentoML?
BentoML è particolarmente adatto a team ML in aziende in crescita che hanno bisogno di passare velocemente da un modello addestrato a una API pronta per la produzione senza una piattaforma MLOps dedicata.
Perché ho scelto BentoML
Ho incluso BentoML tra le mie migliori scelte perché è uno dei pochi framework che tratta l'artefatto modello e il livello di serving come un'unica unità versionata. Mi piace che BentoML generi automaticamente sia endpoint REST che gRPC dalla stessa definizione del servizio, così il mio team non deve mantenere specifiche API separate. L'astrazione dei runner mi consente di isolare ogni modello nel proprio processo, il che significa che un passaggio di pre-processing su CPU non compete per risorse con un runner di modello su GPU.
Funzionalità principali di BentoML
- Batching adattivo: Raggruppa automaticamente le richieste di inferenza concorrenti in un unico batch, riducendo l'overhead GPU per richiesta senza modifiche al codice.
- Metriche Prometheus integrate: Espone un endpoint /metrics pronto all'uso, così puoi monitorare latenza e throughput delle richieste senza strumentazione personalizzata.
- Gateway LLM: Fornisce un'interfaccia API unificata tra vari fornitori di LLM, offrendoti un controllo centralizzato su routing e costi.
- Build di immagini containerizzate: Genera un'immagine Docker pronta per la produzione direttamente da un artefatto Bento tramite un solo comando CLI.
Integrazioni BentoML
BentoML offre integrazioni documentate con strumenti dell'ecosistema MLOps, tra cui Airflow, MLflow, Ray, Spark, Arize AI, Flink e Triton Inference Server. Si integra anche con Datadog per la raccolta di metriche dei servizi BentoML. È disponibile una API per integrazioni personalizzate, e l'output containerizzato di BentoML funziona nativamente con Kubernetes e Docker per una maggiore flessibilità di deployment.
Pros and Cons
Pros:
- Versionamento e tracking rollback integrati per i modelli
- Genera contenitori Docker da config YAML
- Gestisce richieste concorrenti tramite scalabilità dei worker
Cons:
- I file di configurazione possono risultare inutilmente complessi
- I loader personalizzati dei modelli richiedono configurazione aggiuntiva
Ideale per l'hosting di modelli transformer su larga scala

Una piattaforma di inferenza gestita costruita sopra Hugging Face Hub, Hugging Face Inference Endpoints si occupa del deployment cloud dedicato, della configurazione degli endpoint e della selezione dell'hardware per i modelli di ML su AWS, Azure e Google Cloud.
Per chi è ideale Hugging Face Inference Endpoints?
È particolarmente adatto a startup focalizzate sull'IA e aziende tecnologiche di medie dimensioni che necessitano di un hosting dei modelli pronto per la produzione senza dover costruire e mantenere un'infrastruttura di serving propria.
Perché ho scelto Hugging Face Inference Endpoints
Hugging Face Inference Endpoints si guadagna un posto nella mia shortlist perché è progettato appositamente per l'ecosistema dei modelli transformer in un modo che nessun'altra piattaforma di deployment riesce a fare. Il mio team può prendere qualsiasi modello dall'Hub, compresi LLM di grandi dimensioni e transformer multimodali, e metterlo in servizio su scala di produzione con regole di autoscaling configurabili che rispondono al traffico reale. Apprezzo anche la rapidità zero-to-endpoint: un modello che normalmente richiederebbe giorni per essere containerizzato e distribuito manualmente, è attivo in pochi minuti.
Funzionalità chiave di Hugging Face Inference Endpoints
- Deployment multi-cloud: Scegli di distribuire il tuo endpoint su AWS, Azure o Google Cloud senza dover gestire separatamente gli account cloud.
- Rete privata: Isola gli endpoint all'interno di una VPC dedicata in modo che solo i tuoi sistemi interni possano accedere all'API del modello.
- Autenticazione tramite token: Proteggi ogni endpoint con un token API per controllare quali servizi o utenti possono inviare richieste di inferenza.
- Monitoraggio dell'utilizzo: Tieni traccia in tempo reale del volume delle richieste, della latenza e dei tassi di errore direttamente dalla dashboard degli endpoint.
Integrazioni di Hugging Face Inference Endpoints
Hugging Face Inference Providers funziona con un ecosistema in crescita di strumenti per sviluppatori, framework e piattaforme, e strumenti senza supporto esplicito risultano spesso comunque compatibili tramite la sua API compatibile con OpenAI. Le integrazioni documentate includono AWS Bedrock e SageMaker, Google Gemini Enterprise Agent Platform e Azure AI Foundry, oltre a framework LLM come LangChain, LlamaIndex, Haystack, CrewAI e PydanticAI. Gli Inference Endpoints possono essere completamente gestiti tramite API, con endpoint documentati tramite Swagger, così puoi costruire integrazioni personalizzate. Il supporto per Zapier non è chiaramente documentato.
Pros and Cons
Pros:
- Un solo clic per il deploy dall'Hugging Face Hub
- Supporta diversi motori di inferenza
- Autoscaling con fatturazione scale-to-zero
Cons:
- Avvii a freddo quando si scala da zero
- I costi del calcolo su GPU aumentano rapidamente su larga scala

Modal è una piattaforma cloud serverless per l'esecuzione di carichi di lavoro ML basati su Python, che copre inferenza accelerata da GPU, processi batch, sessioni di training e attività pianificate senza alcuna gestione di container o infrastruttura.
Per chi è ideale Modal?
È una soluzione naturale per startup e team in crescita che hanno bisogno di distribuire modelli ML rapidamente senza dover assumere ingegneri infrastrutturali dedicati.
Perché ho scelto Modal
Ho incluso Modal tra le mie scelte principali perché elimina il divario tra la scrittura in Python e la sua esecuzione su larga scala su GPU. Posso richiedere hardware specifico, come A100 o H100, direttamente nella definizione della funzione e Modal lo fornisce su richiesta. Non c'è alcun cluster da gestire né file YAML da scrivere. Apprezzo anche che la stessa funzione si comporti in modo identico sia in locale che in produzione, riducendo notevolmente il tempo di debug.
Funzionalità principali di Modal
- Immagini container personalizzate: Definisci dipendenze, variabili di ambiente e pacchetti di sistema direttamente nel codice, garantendo ambienti di runtime consistenti tra le diverse distribuzioni.
- Volumi persistenti: Monta volumi cloud per memorizzare nella cache i pesi dei modelli tra varie esecuzioni, riducendo i tempi di avvio a freddo nei deployment ripetuti.
- Gestione dei segreti: Conserva e inietta in modo sicuro chiavi API e credenziali durante l'esecuzione senza inserirle nel codice sorgente.
- Esecuzione batch parallela: Usa .map() per eseguire inferenze su grandi insiemi di dati in parallelo su più container simultaneamente.
Integrazioni Modal
Modal offre un piccolo insieme di integrazioni documentate focalizzate su osservabilità e notifiche, tra cui Datadog, qualsiasi provider compatibile con OpenTelemetry, Slack e Okta SSO. Supporta inoltre il montaggio di bucket cloud per AWS S3, Google Cloud Storage e Cloudflare R2, oltre a workflow CI/CD tramite GitHub Actions. Il supporto a Zapier non è documentato, ma Modal mette a disposizione un SDK Python e endpoint web che consentono integrazioni personalizzate.
Pros and Cons
Pros:
- Non servono Dockerfile né configurazioni Kubernetes
- Gestisce training, elaborazione batch e inferenza
- Distribuisce carichi di lavoro su più cloud e regioni
Cons:
- Il codice basato su decorator crea lock-in verso il fornitore
- Le funzionalità Enterprise richiedono un piano premium

Amazon SageMaker (noto anche come AWS SageMaker) è una piattaforma ML di AWS che copre l’intero ciclo di vita del modello—dall’addestramento e perfezionamento fino al deployment, al monitoraggio e alla governance—il tutto all’interno di un ambiente di sviluppo unificato basato su architettura lakehouse.
A Chi È Destinato Amazon SageMaker?
Amazon SageMaker è particolarmente adatto a team di data science e ingegneria ML che già lavorano all’interno dell’ecosistema AWS.
Perché Ho Scelto Amazon SageMaker
Amazon SageMaker si guadagna un posto tra i migliori nella mia lista perché gestisce in modo completamente automatizzato e integrato la gestione dei modelli, senza dover collegare strumenti separati. Apprezzo in particolare SageMaker MLOps, che si occupa di orchestrazione delle pipeline, registro dei modelli e tracciamento dei deployment in un’unica interfaccia. Mi affido anche alle capacità integrate di inferenza, AI ops e osservabilità di SageMaker AI per monitorare i modelli post-deployment e rilevare derive prima che diventino un problema in produzione.
Funzionalità Principali di Amazon SageMaker
- SageMaker JumpStart: Accedi a oltre 1.000 modelli AI predefiniti dai principali fornitori e distribuiscili o personalizzali direttamente all’interno di SageMaker.
- SageMaker HyperPod: Scala lavori di addestramento e ottimizzazione su cluster composti da centinaia o migliaia di acceleratori AI con gestione automatizzata del cluster.
- Inferenza multi-modale: Distribuisci modelli usando inferenza in tempo reale, serverless, asincrona o batch su oltre 70 tipi di istanze.
- MLflow gestito: Monitora, organizza e confronta esperimenti iterativi senza bisogno di provisioning di infrastruttura o gestione di server.
Integrazioni Amazon SageMaker
Amazon SageMaker si integra nativamente con l’ecosistema AWS, incluso Amazon S3, Amazon Redshift, Amazon Athena, Amazon EMR e AWS Glue, oltre ad Amazon Bedrock e Amazon Q Developer. Funziona anche con strumenti di terze parti come Datadog, Hugging Face, MLflow e Pinecone. È disponibile un’API per integrazioni personalizzate.
Pros and Cons
Pros:
- Modalità di inferenza multiple per diversi carichi di lavoro
- AutoML integrato e ottimizzazione degli iperparametri
- Shadow testing per rollout sicuri dei modelli
Cons:
- Strettamente legato all’ecosistema AWS
- Difficile il debug dei job di addestramento falliti

Gemini Enterprise Agent Platform (precedentemente Vertex AI) è la piattaforma ML end-to-end di Google Cloud che copre l'addestramento dei modelli, la personalizzazione, la valutazione, il deployment e lo sviluppo di agenti AI in un unico ambiente gestito.
A chi è rivolto Gemini Enterprise Agent Platform?
Gemini Enterprise Agent Platform è la scelta naturale per i team di ingegneria ML e data science che già gestiscono l'infrastruttura dati su Google Cloud Platform.
Perché ho scelto Gemini Enterprise Agent Platform
Ho incluso Gemini Enterprise Agent Platform tra le mie scelte principali perché riduce realmente il divario tra la gestione dei dati e quella dei modelli. In particolare, apprezzo il modo in cui Gemini Enterprise Agent Platform Pipelines si collega direttamente a BigQuery, consentendo al mio team di costruire pipeline di addestramento direttamente sui dati di magazzino senza dover esportare nulla. Il Feature Store di Gemini Enterprise Agent Platform permette inoltre di definire, gestire e monitorare le feature in modo coerente sia in fase di training che di inferenza, eliminando così una delle principali fonti di divergenza tra allenamento e produzione.
Funzionalità principali di Gemini Enterprise Agent Platform
- Model Registry di Gemini Enterprise Agent Platform: Un repository centralizzato per versionare, organizzare e gestire i modelli durante tutto il loro ciclo di vita, sia prima sia dopo il deployment.
- Endpoint di previsione online: Consente di distribuire modelli su endpoint dedicati che erogano previsioni in tempo reale con risorse di calcolo configurabili e suddivisione del traffico tra diverse versioni del modello.
- Model Monitoring di Gemini Enterprise Agent Platform: Rileva divergenze nelle feature e variazioni nelle previsioni nei modelli distribuiti confrontando il traffico live con una baseline dei dati di addestramento.
- Experiments di Gemini Enterprise Agent Platform: Tiene traccia, confronta e visualizza le iterazioni degli allenamenti per aiutare i team a individuare le configurazioni di modello migliori.
Integrazioni Gemini Enterprise Agent Platform
Gemini Enterprise Agent Platform si integra nativamente con l'ecosistema Google Cloud, tra cui BigQuery, Cloud Storage, Dataflow e Pub/Sub, e supporta anche Kubeflow Pipelines e container preconfigurati per TensorFlow, scikit-learn, XGBoost e PyTorch. I suoi data store supportano inoltre connettori di terze parti per strumenti come Jira e Shopify. È disponibile su Zapier ed è possibile integrarla tramite API personalizzate.
Pros and Cons
Pros:
- Model Garden offre oltre 200 modelli pronti alla distribuzione
- Deployment tramite endpoint direttamente da Model Garden molto semplice
- Integrazione nativa con BigQuery per workflow dati
Cons:
- Anche gli endpoint dedicati inattivi generano costi
- Incongruenze tra regioni generano messaggi di errore poco chiari
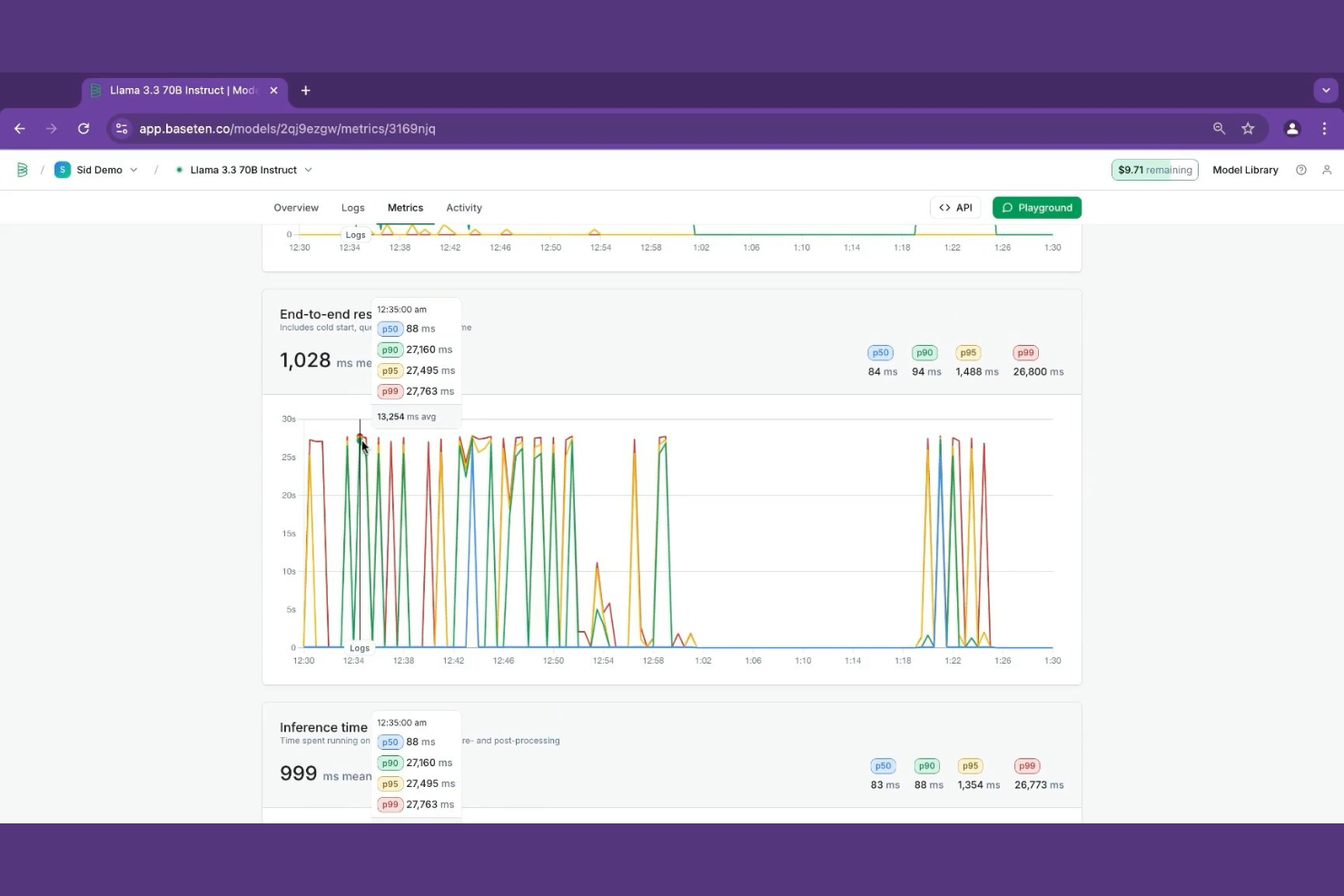
Baseten è una piattaforma di inferenza di modelli che consente ai team ML di distribuire modelli personalizzati, open-source e ottimizzati con servizio accelerato tramite GPU, autoscaling e strumenti di ottimizzazione delle prestazioni integrati direttamente nella piattaforma.
Per chi è Baseten?
Baseten è adatto ai team di prodotto AI nelle aziende in fase di crescita che necessitano di pieno controllo sulle prestazioni di inferenza per distribuzioni di modelli a bassa latenza o ad alto throughput.
Perché ho scelto Baseten
Baseten si è guadagnato un posto nella mia shortlist perché consente di costruire e distribuire interfacce web personalizzate sopra i modelli all'interno della stessa piattaforma, senza bisogno di uno stack frontend separato. Utilizzo il costruttore di applicazioni di Baseten per creare interfacce interattive che chiamano direttamente gli endpoint dei modelli, il che è utile per strumenti interni o demo per stakeholder. Il modello e la sua UI rimangono versionati e distribuiti insieme.
Funzionalità chiave di Baseten
- Packaging modelli Truss: Impacchetta qualsiasi modello personalizzato o ottimizzato come artefatto Python riproducibile con gestione delle dipendenze integrata e reload live per i test locali.
- Baseten Chains: Costruisci workflow AI composti multi-step dove ogni passaggio gira su hardware configurato in modo indipendente con la propria policy di autoscaling.
- Gestione segreti: Archivia e inserisci chiavi API e credenziali d'ambiente direttamente nelle distribuzioni dei modelli senza scriverle hardcoded nel codice di servizio.
- Suddivisione traffico A/B: Instrada traffico di inferenza live su più versioni di modelli contemporaneamente per confrontarne le prestazioni prima di promuovere completamente una nuova distribuzione.
Integrazioni Baseten
Baseten supporta l'esportazione di metriche verso Prometheus, Datadog, Grafana Cloud e New Relic tramite il suo endpoint metriche basato su OpenTelemetry. È pienamente compatibile con OpenAI, quindi puoi collegarlo a qualsiasi client o gateway che utilizzi l'SDK OpenAI, inclusi LiteLLM, LlamaIndex e Cloudflare AI Gateway. È disponibile un'API per integrazioni personalizzate.
Pros and Cons
Pros:
- Il packaging open-source Truss semplifica il deployment dei modelli
- Distribuzione one-click dai checkpoint di training
- Avvio a freddo inferiore al secondo su istanze GPU
Cons:
- La tariffazione basata sull'uso può variare in modo imprevedibile
- Richiede competenze di ingegneria ML per l'operatività

Basato sul framework open-source Ray, Anyscale è una piattaforma gestita per il serving di modelli ML che gestisce l'inferenza distribuita, l'autoscaling e il deployment di modelli multipli su cluster GPU e CPU.
A chi è rivolto Anyscale?
Anyscale è particolarmente adatto a ingegneri ML e team di data science di organizzazioni medie e grandi che eseguono carichi di lavoro basati su Python su larga scala e necessitano di gestione di cluster GPU senza complicazioni manuali dell'infrastruttura.
Perché ho scelto Anyscale
Ho scelto Anyscale tra i migliori perché è l'unica piattaforma gestita costruita direttamente su Ray; ciò significa che il mio team può scrivere Python standard per definire la logica di serving distribuito senza dover imparare un diverso DSL di orchestrazione. In particolare apprezzo l'API di graph di deploy di Ray Serve, che permette di comporre più modelli in una singola pipeline di inferenza con un routing esplicito delle richieste. L'allocazione frazionata delle GPU è un'altra funzione che uso spesso per raggruppare modelli leggeri su hardware condiviso senza dover avviare istanze dedicate.
Caratteristiche principali di Anyscale
- Autoscaling: Scala automaticamente il numero di repliche in base al throughput delle richieste in tempo reale e alla profondità della coda.
- Suddivisione del traffico: Instrada una percentuale configurabile di traffico live verso nuove versioni dei modelli per rollout graduali senza tempi di inattività.
- Batching delle richieste: Raggruppa le richieste di inferenza in arrivo in batch per massimizzare l'utilizzo della GPU tra chiamate concorrenti.
- Serving multi-nodo di modelli: Distribuisce un singolo modello di grandi dimensioni su più nodi quando supera i limiti di memoria di una singola GPU.
Integrazioni di Anyscale
Anyscale si integra con le principali librerie e framework AI/ML, con oltre 50 integrazioni che coprono piattaforme dati, orchestrazione, framework ML, osservabilità e framework per applicazioni LLM. Tra queste: MLflow, Weights & Biases, MongoDB, Snowflake, Databricks, Hugging Face, PyTorch e TensorFlow, oltre ad Airflow, Prefect, Dagster, Datadog, LangChain e LlamaIndex. È disponibile un'API per integrazioni personalizzate e la piattaforma può essere distribuita anche come servizio di prima parte su Amazon EKS, Google GKE, Azure AKS e OCI Kubernetes Engine.
Pros and Cons
Pros:
- Scala il codice Python su cluster GPU distribuiti
- Serving di modelli agnostico rispetto al framework tramite Ray Serve
- Supporto per spot instance con tolleranza ai guasti automatica
Cons:
- Fortemente integrato nell'ecosistema Ray
- Richiede una conoscenza approfondita dei sistemi distribuiti

Altri strumenti per il deployment di modelli ML
Ecco alcune opzioni aggiuntive di strumenti per il deployment di modelli ML che non sono entrate nella mia shortlist, ma che comunque meritano di essere prese in considerazione:


{kind=link}
Come valuto gli strumenti di Deployment dei Modelli ML
Divido la mia valutazione in due livelli: criteri di base che una piattaforma di serving in produzione deve soddisfare e fattori differenzianti che contano su larga scala tra cluster GPU e flussi di lavoro MLOps.
Funzionalità core (Requisiti minimi per questa lista)
Quando seleziono gli strumenti per la mia lista, valuto ciascuno su una scala da 0 (non offre la funzionalità) a 5 (eccelle in questo ambito) per ogni funzionalità core elencata di seguito. Poi, calcolo il punteggio totale dello strumento come percentuale. Ogni strumento deve raggiungere un punteggio minimo totale del 65% per essere considerato per l'inclusione.
- Model serving: Verifico se uno strumento supporta sia endpoint REST/gRPC in tempo reale sia inferenza batch, poiché la maggior parte dei carichi in produzione necessita di entrambi i pattern.
- Supporto multi-framework: I team spesso eseguono PyTorch per modelli di visione assieme a XGBoost per dati tabellari, quindi cerco il supporto nativo per i principali framework.
- Versioning del modello: Valuto come ogni strumento traccia artefatti e metadata dei modelli, soprattutto la possibilità di effettuare rollback di un deployment se una nuova versione performa peggio.
- Scalabilità e risorse: Il traffico in produzione è imprevedibile, quindi cerco autoscaling sia su GPU che CPU con bilanciamento del carico per gestire i picchi di inferenza.
- Monitoraggio: Intercettare una deriva dei dati prima che degradi le previsioni è importante, dunque valuto rilevamento integrato delle derive, monitoraggio della latenza e capacità di alerting.
- Automazione del deployment: Cerco supporto per pipeline CI/CD con opzioni di rollout canary o A/B, poiché aggiornare un modello in sicurezza richiede più di un deploy manuale.
Una volta che ho una lista di strumenti che soddisfano questi criteri, considero cosa distingue ogni piattaforma.
Fattori differenzianti (Cosa distingue i fornitori)
Ecco come confronto i diversi fornitori:
Funzionalità distinguibili
L'inferenza con scale-to-zero è un elemento fortemente distintivo. Alcune piattaforme mantengono gli endpoint sempre attivi, mentre altre scalano automaticamente a zero quando sono inattivi. Questa differenza impatta direttamente la spesa GPU per carichi con traffico imprevedibile. Il supporto a deployment canary e shadow differenzia anch'esso i fornitori. Instradare traffico reale verso una nuova versione del modello prima del passaggio definitivo è il modo più sicuro per intercettare regressioni di accuratezza. Ottimizzazioni a livello GPU come batching dinamico e quantizzazione sono importanti, soprattutto per casi d'uso sensibili alla latenza come la rilevazione frodi in tempo reale.
Oltre le funzionalità
L'integrazione con l'ecosistema MLOps è un elemento chiave che valuto. Uno strumento di deployment che si connette a tracker degli esperimenti come MLflow o Weights & Biases e ad orchestratori come Airflow evita al team di sviluppare codice custom per collegarli. Anche la flessibilità infrastrutturale è importante. Guardo se il fornitore offre opzioni cloud gestite, Kubernetes self-hosted o BYOC, poiché i team soggetti a regolamentazione spesso necessitano che i dati restino nel proprio VPC. Governance e compliance completano il quadro. La certificazione SOC 2 Type II, RBAC e audit logging sono prerequisiti per team che distribuiscono modelli in ambito sanitario o finanziario.
Come scegliere gli strumenti per il deployment di modelli ML
È facile perdersi in lunghe liste di funzionalità e strutture di prezzo complesse. Per aiutarti a mantenere la concentrazione mentre attraversi il tuo personale processo di selezione del software, ecco una checklist di fattori da tenere a mente:
| Fattore | Cosa considerare |
|---|---|
| Scalabilità | Lo strumento gestisce aumenti improvvisi di traffico di inferenza senza intervento manuale? Verifica la presenza di supporto sia per scenari di picco che di bassa attività. |
| Integrazioni | La piattaforma si collega nativamente ai tuoi tracker di esperimenti, strumenti CI/CD o data warehouse, oppure sarà necessario sviluppare e mantenere codice personalizzato? |
| Personalizzazione | È possibile adattare i workflow di deployment, i controlli di accesso ai modelli e la gestione delle risorse alle tue politiche e strutture di team? |
| Facilità d’uso | Quanto è ripida la curva di apprendimento per il tuo team? Considera la complessità dell’interfaccia, la qualità della documentazione e se l'onboarding rallenterà altri progetti. |
| Implementazione e onboarding | Quanto tempo di ingegneria occorre per passare dalla prova alla produzione? Fai attenzione a eventuali passaggi nascosti di setup, prerequisiti di rete o formazione obbligatoria. |
| Costo | I modelli di prezzo sono trasparenti e prevedibili man mano che l’utilizzo cresce? Confronta i metodi di fatturazione—per predizione, ora di calcolo o endpoint—per i tuoi carichi di lavoro. |
| Salvaguardie di sicurezza | Quali meccanismi di crittografia, controllo degli accessi e audit sono disponibili? Valuta se l’offerta soddisfa i tuoi standard interni di sicurezza e le esigenze dei clienti. |
| Requisiti di conformità | Hai bisogno di HIPAA, GDPR, o SOC 2 Type II? Conferma che il fornitore offra le attestazioni necessarie e supporti i trail di audit indispensabili per il tuo settore. |
Cosa sono gli strumenti per il deployment di modelli ML?
Gli strumenti di deployment dei modelli ML sono piattaforme che ti aiutano a rendere operativi i modelli di machine learning addestrati, rendendoli disponibili tramite API o endpoint batch per l'uso nel mondo reale. Questi strumenti gestiscono attività come la pubblicazione del modello, la scalabilità, il monitoraggio e la gestione delle versioni, così puoi fornire previsioni accurate e mantenere l’affidabilità man mano che i carichi di lavoro evolvono.
Caratteristiche degli strumenti di deployment dei modelli ML
Quando scegli gli strumenti per il deployment dei modelli ML, presta attenzione alle seguenti caratteristiche chiave:
- Supporto multi-framework: Permette di distribuire modelli sviluppati con TensorFlow, PyTorch, scikit-learn, XGBoost e ONNX senza dover riscrivere il codice del modello o eseguire passaggi di conversione.
- Inferenza con auto-scalabilità: Assegna automaticamente le risorse di calcolo in base ai pattern di traffico, gestendo improvvisi picchi o periodi di bassa attività per mantenere sia le prestazioni sia l'efficienza dei costi.
- Gestione delle versioni dei modelli: Tiene traccia delle diverse versioni di un modello, facilitando rollback, confronti o promozione dei modelli nelle pipeline di produzione con minime interruzioni.
- Deployment canary e shadow: Consente rilasci graduali o la replica del traffico reale, così puoi validare nuovi modelli in sicurezza con dati reali prima di un deployment completo.
- Pubblicazione batch e in tempo reale: Supporta casi d'uso sia tramite API real-time sia con elaborazione batch asincrona, garantendo flessibilità per applicazioni aziendali o flussi di lavoro di data science.
- Gestione delle risorse: Permette di assegnare e monitorare l’utilizzo di CPU, GPU e memoria per ogni modello, aiutando a ottimizzare i costi e mantenere la salute del servizio in produzione.
- Sicurezza e protezione: Include controllo degli accessi, crittografia e isolamento di rete per proteggere gli artefatti dei modelli e i dati sensibili di inferenza.
- Supporto all’integrazione: Si connette nativamente o tramite API a strumenti MLOps, pipeline CI/CD e infrastrutture dati per semplificare la delivery continua e il monitoraggio.
- Logging e monitoraggio: Offre visibilità su log delle richieste, metriche di latenza e tassi di errore per una risoluzione proattiva dei problemi e affidabilità operativa.
- Conformità e auditabilità: Dispone di funzioni come audit log e supporto alla conformità normativa, aiutandoti a soddisfare i requisiti di settore in ambito sanitario, finanziario o in altri settori regolamentati.
Tipiche funzionalità AI degli strumenti di deployment dei modelli ML
Oltre alle funzionalità standard sopra elencate, molte di queste soluzioni stanno integrando l’AI grazie a funzioni come:
- Rilevamento automatico del drift: Utilizza l’intelligenza artificiale per monitorare i dati in ingresso e le previsioni alla ricerca di variazioni nella distribuzione, avvisando i team quando serve un retraining o un’indagine per mantenere la precisione del modello.
- Allocazione intelligente delle risorse: Applica algoritmi di AI per prevedere i pattern di carico di lavoro e allocare dinamicamente le risorse di calcolo, riducendo i costi e minimizzando la latenza senza bisogno di intervento manuale.
- Deployment auto-riparanti: Sfrutta l’AI per rilevare endpoint di modelli guasti o degradati e reindirizzare automaticamente il traffico o avviare un nuovo deployment, riducendo i tempi di inattività e la necessità di interventi manuali.
- Scalabilità predittiva: Utilizza l’AI per prevedere picchi o cali di traffico in base allo storico d’uso, scalando proattivamente l’infrastruttura per garantire prestazioni costanti e controllo dei costi.
- Rilevamento anomalie nell’inferenza: Impiega l’AI per segnalare richieste di previsione insolite o sospette in tempo reale, aiutando a identificare potenziali problemi di qualità dei dati o minacce alla sicurezza.
- Analisi automatica della causa principale: Sfrutta l’AI per analizzare log e metriche, identificando la fonte di cali nelle prestazioni o errori così che i team possano risolvere rapidamente e con meno tentativi.
Vantaggi degli strumenti di deployment dei modelli ML
L’implementazione di strumenti per il deployment dei modelli ML offre numerosi vantaggi al tuo team e alla tua azienda. Ecco alcuni dei benefici a cui puoi ambire:
- Cicli di distribuzione accelerati: Automatizzazione di packaging, versionamento e integrazione con pipeline CI/CD permettono ai team di spostare rapidamente i modelli dallo sviluppo alla produzione.
- Scalabilità coerente: L'auto-scalabilità e la gestione dinamica delle risorse assicurano che le tue distribuzioni rimangano stabili e reattive al variare della domanda.
- Posizionamento di sicurezza rafforzato: Controlli di accesso integrati, crittografia e registrazione degli audit aiutano a proteggere modelli e dati sensibili in linea con i requisiti organizzativi e normativi.
- Riduzione dei costi operativi: Monitoraggio centralizzato, avvisi e registrazione riducono al minimo il troubleshooting manuale e liberano risorse ingegneristiche per attività di maggior valore.
- Governance affidabile dei modelli: Gestione delle versioni e registrazione delle distribuzioni facilitano il tracciamento dei modelli, l'annullamento delle modifiche e la dimostrazione della conformità durante gli audit.
- Integrazione dei workflow flessibile: Supporto per più framework, strategie di distribuzione e configurazioni ambientali permettono ai team di adattare le capacità degli strumenti alle esigenze di business.
- Migliore preparazione alla conformità: Complete tracce di audit e funzionalità di compliance semplificano il rispetto di requisiti HIPAA, GDPR o settoriali, riducendo i rischi per le aziende regolamentate.
Costi e prezzi degli strumenti di distribuzione di modelli ML
La selezione degli strumenti per la distribuzione di modelli ML richiede la comprensione dei vari modelli di prezzo e piani disponibili. I costi variano in base alle funzionalità, alla dimensione del team, agli add-on e altro ancora. La tabella seguente riassume i piani comuni, i loro prezzi medi e le tipiche funzionalità incluse nelle soluzioni di strumenti per la distribuzione di modelli ML:
Tabella comparativa dei piani per strumenti di distribuzione di modelli ML
| Tipo di piano | Prezzo medio | Funzionalità comuni |
|---|---|---|
| Piano gratuito | $0 | Distribuzioni limitate, monitoraggio di base, accesso singolo utente e supporto dalla community. |
| Piano personale | $10-$30/user/month | Utilizzo individuale, versionamento standard dei modelli, allocazione moderata di risorse e supporto via email. |
| Piano business | $40-$100/user/month | Collaborazione in team, auto-scaling, supporto alle integrazioni, sicurezza avanzata e controlli di accesso basati sui ruoli. |
| Piano enterprise | $150-$500+/user/month | Compliance avanzata, supporto premium, infrastruttura dedicata, SLA personalizzati ed estese funzionalità di audit e sicurezza. |
FAQ sugli strumenti di distribuzione di modelli ML
Ecco alcune risposte alle domande più comuni sugli strumenti di distribuzione di modelli ML:
In cosa differiscono gli strumenti di distribuzione di modelli ML dagli strumenti di distribuzione di applicazioni tradizionali?
Gli strumenti di distribuzione di modelli ML sono progettati per gestire le sfide uniche della pubblicazione, del monitoraggio e dell’aggiornamento dei modelli di machine learning, come la gestione delle versioni dei modelli, la raccolta di log di inferenze, il supporto all’auto-scalabilità del traffico modello e l’integrazione con le pipeline di dati. Gli strumenti di distribuzione di applicazioni tradizionali solitamente non supportano questi requisiti specifici.
Posso distribuire modelli costruiti in framework diversi con lo stesso strumento di distribuzione?
Sì, la maggior parte degli strumenti di distribuzione di modelli ML offre compatibilità multi-framework permettendo la distribuzione di modelli da TensorFlow, PyTorch, XGBoost e altri senza conversioni o riscritture manuali. Questo semplifica il lavoro di team che utilizzano tecnologie diverse e permette di standardizzare i processi di produzione.
Quali funzionalità di sicurezza devo cercare in questi strumenti?
Cerca funzionalità come controlli di accesso, endpoint crittografati, audit trail e isolamento di rete. Queste assicurano che solo utenti autorizzati possano distribuire o aggiornare modelli e proteggono i tuoi asset modello e i dati sulle predizioni.
Questi strumenti supportano sia inferenze in tempo reale sia batch?
Sì, i principali strumenti di distribuzione di modelli ML supportano sia la pubblicazione di predizioni in tempo reale tramite API sia modalità di elaborazione batch. Questo dà flessibilità per gestire casi d’uso diversi, da applicazioni rivolte agli utenti a grandi job di scoring offline.
In che modo questi strumenti aiutano nel monitoraggio e nella manutenzione dei modelli?
Offrono dashboard di monitoraggio integrate, avvisi, registrazione dei log e rilevamento automatico del drift. Queste funzionalità permettono di intercettare tempestivamente degradi delle prestazioni, problematiche sui dati o errori operativi—spesso prima che impattino sugli utenti finali o sugli esiti di business.