Le 4 trappole che impediscono l’aggiornamento dei sistemi legacy—e come liberarsene

Scalabilità fallita, debito tecnico crescente e rischi di conformità – questi sono segnali che il tuo sistema legacy ha bisogno di essere sostituito. I sistemi legacy possono sembrare affidabili cavalli da tiro—affidabili e familiari—ma sotto la superficie, possono accumulare silenziosamente debito tecnico, ostacolare l’innovazione e rappresentare rischi di conformità significativi.
I segnali sono chiari e i rischi aumentano, eppure ti ritrovi a rimandare la decisione trimestre dopo trimestre. Come evidenzia Mohan Sitaram in I fantasmi delle reti passate, "i sistemi legacy possono sembrare innocui fino a quando non iniziano a causare scompiglio." Se questa situazione ti sembra familiare, stai vivendo quello che io chiamo "paralisi da migrazione" – e non sei solo.
In questo articolo, analizzeremo i quattro principali ostacoli alla migrazione—perfezionismo, paura del fallimento, ritardi infiniti e ricerca del consenso—e forniremo strategie pratiche per superarli. Se hai rimandato una migrazione critica, questa guida ti aiuterà a superare l’inerzia e agire in modo deciso prima che i costi diventino insostenibili.
I quattro tranelli della paralisi da migrazione
1. La sindrome del “prossimo trimestre”
Lo conosciamo tutti: "Ce ne occuperemo dopo le vacanze, il prossimo round di finanziamenti, o una release importante." La verità è che non esiste mai un momento perfetto per la migrazione. Aspettare quel fatidico momento ideale crea problemi più grandi di quelli che evitiamo.
Recentemente ho lavorato con un CTO che aveva pianificato di migrare il proprio sistema di elaborazione pagamenti per sei trimestri consecutivi. "Lo faremo subito dopo il Black Friday" è diventato "Aspettiamo dopo le vendite di San Valentino," e poi "Magari dopo la stagione estiva." Nel frattempo, le loro soluzioni "temporanee" stavano diventando architettura permanente, e il loro debito tecnico si accumulava più rapidamente di una bolletta della carta di credito dopo Natale.
Il punto di svolta è arrivato quando hanno iniziato a monitorare il "costo del ritardo" – non solo in termini di denaro, ma anche in morale del team e opportunità perse. Ogni lunedì, esaminavano una semplice dashboard che mostrava le ore dedicate alle correzioni di emergenza, metriche sul degrado delle prestazioni e il tempo perso su nuove funzionalità. Quando si sono resi conto che il team impiegava oltre il 20% del tempo solo per mantenere il funzionamento, il mito del "momento perfetto" è finalmente crollato.
Ecco cosa succede mentre aspettiamo il prossimo trimestre:
- I piccoli problemi si trasformano in problemi sistemici
- Le soluzioni rapide diventano architettura permanente
- Il debito tecnico accumula interessi esponenziali
- Il "momento perfetto" diventa sempre più difficile da trovare
Stabilisci dei trigger non negoziabili per te stesso. Quel CTO ha stabilito una semplice regola: se le correzioni di emergenza superavano il 20% del tempo di sviluppo per due mesi consecutivi, la migrazione sarebbe automaticamente diventata una discussione a livello di consiglio di amministrazione. Basta aspettare il momento perfetto – solo decisioni chiare e guidate dai dati.
2. La fallacia della perfezione
"Se dobbiamo farlo, dobbiamo farlo per bene." Sembra ragionevole, vero? Questo è il perfezionismo mascherato da professionalità. È la voce che ti convince a rimandare l’azione finché non hai il piano perfetto, il team perfetto e le circostanze perfette.
Una volta ho fatto da mentore a un CTO di una società fintech in crescita con il piano di migrazione più dettagliato che avessi mai visto. Conteneva diagrammi architetturali completi, esaurienti valutazioni dei rischi, piani di contingenza perfetti – tutto quello che si possa immaginare. L’unico problema era che stava in Confluence da 18 mesi, ricevendo aggiornamenti regolari ma senza mai vedere la luce.
La svolta è arrivata da una crisi inaspettata: un concorrente ha lanciato una funzionalità che avrebbe dovuto richiedere solo settimane, ma la loro squadra stimava mesi a causa dei vincoli legacy. Fu allora che lei capì che una migrazione "abbastanza buona" eseguita oggi vale più di una migrazione perfetta che non viene mai avviata.
Accantonarono il piano mastodontico e partirono da una domanda semplice: "Qual è la parte più piccola che possiamo migrare che farebbe davvero la differenza?" Individuarono il loro servizio di notifiche – un componente gestibile e con confini chiari.
Il piano di migrazione era perfetto? No. Hanno incontrato degli ostacoli? Sì. Ma tre mesi dopo avevano il loro primo servizio funzionante su infrastruttura moderna e, ancora più importante, avevano creato slancio.
3. La trappola dell'autoconservazione professionale
Siamo onesti: delle migrazioni fallite hanno causato la fine di carriere. Questa paura spinge molti CTO a scegliere il male che già conoscono piuttosto che l’ignoto. In fondo, nessuno è mai stato licenziato per aver mantenuto lo status quo... fino a quando non è successo.
Un mio collega l’ha imparato a sue spese. Era CTO di una piattaforma e-commerce di successo che girava su un sistema da lui stesso progettato anni prima. "È stabile," diceva nei nostri incontri. "Perché rischiare di agitare le acque?" Era rispettato in azienda e lodato per mantenere tutto in funzione senza problemi.
Poi arrivò il Black Friday. Il loro sistema di gestione degli ordini, che era stato "stabile" per anni, non riuscì a gestire i nuovi modelli di carico. Il blackout durò sei ore – un’eternità nel mondo dell’e-commerce. La prima domanda del consiglio non riguardò il guasto, ma perché non erano stati avvertiti in anticipo dei limiti del sistema.
L'ironia? Evitando il rischio professionale di una migrazione fallita, spesso ci assicuriamo proprio l’esito che vogliamo evitare. I sistemi non invecchiano come il vino buono.
4. La Paralisi da Consenso
"Dobbiamo essere tutti d’accordo prima di procedere." Sebbene il coinvolgimento degli stakeholder sia importante, attendere l’unanimità è una ricetta per l’inazione. I vari team hanno priorità diverse e qualcuno avrà sempre un motivo per rimandare.
Ricordo il CTO di un’azienda di software medico determinato a fare le cose "nel modo giusto" – ottenere l’approvazione di tutti i responsabili di reparto prima di iniziare la migrazione. La Finanza era preoccupata per i costi, le Vendite volevano la garanzia di zero interruzioni, le Operation volevano aspettare dopo il picco stagionale e l’ufficio Legale temeva questioni di conformità durante la transizione.
Dopo sei mesi di riunioni, erano ancora al punto di partenza. Il punto di svolta arrivò quando cambiò approccio: invece di cercare l’approvazione unanime, costruì una coalizione di "volenterosi". Individuò i team più penalizzati dai limiti del sistema legacy – in questo caso i dipartimenti di pianificazione dei pazienti e di fatturazione – e li rese i campioni della migrazione.
Invece di affrontare subito i problemi di tutti, fecero una migrazione pilota solo con questi due reparti. Questo approccio mirato ebbe successo dove mesi di riunioni avevano fallito: mostrò benefici concreti che convinsero altri stakeholder ad aderire.
Sbloccare il Passo: Il Decision Framework
Qui è dove teoria e pratica si incontrano. Avendo visto innumerevoli CTO affrontare queste sfide, ho sviluppato un modello decisionale che taglia le barriere psicologiche e porta all’azione. Vediamo insieme, con esempi concreti, come leader tecnologici di successo l’hanno applicato.
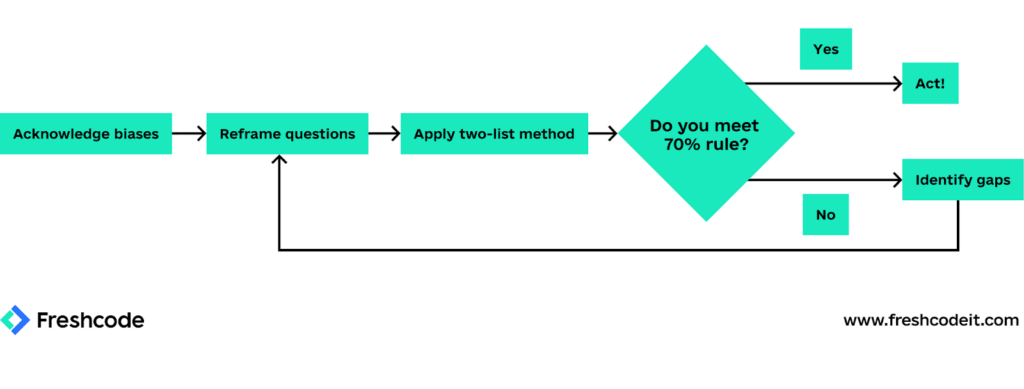

Passo 1: Riconosci i Tuoi Bias
Inizia riconoscendo quali dei pattern descritti sopra stanno influenzando le tue decisioni. Non si tratta di una CTO di successo che una volta mi disse: “La parte più difficile non era individuare le sfide tecniche – era ammettere che le mie paure erano il vero ostacolo principale.” Rimandava una migrazione critica a causa di un precedente fallimento in un’altra azienda. Solo riconoscendo apertamente questo bias è riuscita a valutare la situazione attuale in modo obiettivo.
Inizia ponendoti queste domande:
- Sto evitando questa migrazione a causa di esperienze passate?
- Ho “venduto” troppo la stabilità dell’attuale sistema agli stakeholder?
- Sto lasciando che il perfetto sia nemico del buono?
Non si tratta di dare colpe – si tratta di rimuovere ostacoli mentali.
La parte più difficile di una migrazione non è la sfida tecnica—è decidere di iniziare.
Passo 2: Riformula la Domanda
"Dovremmo migrare?" è la domanda sbagliata. Ti mette in una mentalità da sì/no in cui la posta in gioco sembra insormontabile. Ho imparato questa lezione dal CTO di una piattaforma retail che faticava a decidere—fino a che non cambiò completamente l’approccio.
Invece della schiacciante domanda "Dovremmo migrare?", iniziarono a porsi interrogativi più mirati, che richiedevano risposte specifiche:
“Qual è il vero costo di aspettare ancora un trimestre?”
Calcolarono non solo i costi di hosting, ma anche le ore di sviluppo spese per workaround, le funzionalità che non potevano essere lanciate e le opportunità di mercato perse. Quando videro che stavano pagando 50.000 $ al mese solo per mantenere lo status quo, la chiarezza decisionale emerse in modo naturale.
“Se venissi assunto oggi, cosa farei?”
Questo esercizio mentale li liberò dal peso delle decisioni passate. “È stato liberatorio,” mi raccontarono. “Quando ho guardato il nostro stack come lo vedrebbe un nuovo arrivato, il percorso da seguire era lampante. Nessuno sceglierebbe mai di costruire ciò che stavamo mantenendo.”
“Sto preservando la stabilità o sto preservando i problemi?”
Questa domanda ha rivelato che il loro sistema "stabile" era in realtà un castello di carte che richiedeva sforzi sempre più eroici. Quella che chiamavano stabilità era solo un caos familiare.
Passo 3: Il metodo delle due liste
Un CTO fintech con cui ho lavorato era bloccato nell'analisi paralizzante finché non abbiamo provato questo esercizio semplice ma potente. Abbiamo preso una lavagna e l'abbiamo divisa in due colonne:
"Problemi che peggioreranno aspettando:"
- I loro sviluppatori più esperti erano sempre più frustrati e lasciavano intendere di voler andare via
- Il debito tecnico si aggravava ogni mese
- Le patch di sicurezza diventavano sempre più complesse da applicare
- Ogni nuova funzionalità richiedeva più tempo della precedente per essere implementata
- Le lamentele dei clienti sulla velocità del sistema aumentavano
"Problemi che miglioreranno aspettando:"
- Gli strumenti di migrazione potrebbero maturare ulteriormente
- Il team potrebbe acquisire più esperienza con le nuove tecnologie
- Sarebbe possibile risparmiare un budget maggiore per il progetto
Guardando queste liste fianco a fianco, la decisione improvvisamente è diventata chiara. La colonna dell'attesa era composta soprattutto da benefici ipotetici, mentre la colonna dell'agire subito era piena di problemi concreti e in peggioramento.
Prendi la decisione: un approccio basato sulla realtà
La regola del 70%
Non serve essere certi al 100% – una lezione che ho imparato da una CTO di software sanitario che ha aspettato troppo a lungo la "chiarezza completa". Dopo il terzo trimestre di rinvii, un concorrente ha lanciato le stesse funzionalità in metà tempo perché aveva capito qualcosa di cruciale: non servono tutte le risposte; servono risposte sufficienti.
Ecco come si presenta "sufficiente":
70% di fiducia nella tua valutazione
"Avevo un foglio di calcolo complesso che teneva traccia di ogni rischio possibile," mi ha detto, "ma il mio mentore mi ha fatto una domanda semplice: 'Se dovessi prendere questa decisione in base a ciò che sai ora, ti sentiresti più nel giusto che nel torto?' È lì che ho capito che mi stavo nascondendo dietro l'analisi."
70% degli stakeholder chiave coinvolti
Nota che non si tratta di tutti – ma del numero sufficiente per creare slancio. Un CTO nel settore retail ha condiviso la sua strategia: "Ho mappato le preoccupazioni degli stakeholder su una semplice matrice: alto impatto/basso impatto, favorevole/resistente. Quando avevo il gruppo ad alto impatto favorevole allineato, bastava per iniziare. Gli altri si sono aggiunti quando hanno visto i primi successi."
70% delle domande cruciali risolte
Le domande a cui non si può rispondere adesso saranno più chiare man mano che si va avanti. Un team ha creato tre gruppi di domande:
- Da risolvere prima di iniziare
- Possiamo risolverle strada facendo
- Bello averle, ma non bloccanti
Arrivare al 100% spesso è più costoso che gestire il 30% di incertezza durante l’esecuzione. Il tuo compito non è eliminare tutti i rischi – è renderli gestibili.
Il test della reversibilità
Un CTO di un'azienda di videogiochi mi ha insegnato questo approccio. Per ogni punto decisionale importante, poni tre domande:
Questa decisione può essere annullata se necessario?
Hanno creato "vie di fuga" – percorsi chiaramente documentati per tornare allo stato precedente ad ogni fase della migrazione. "Avere una via di ritorno ci ha reso più coraggiosi nell'andare avanti," mi ha spiegato.
Qual è la nostra posizione di riserva?
Hanno mantenuto il loro sistema legacy in modalità sola lettura per il doppio del tempo che pensavano necessario. Costoso? Sì, ma gli ha permesso di dormire sonni tranquilli.
Qual è il costo effettivo dell’errore?
Non lo scenario catastrofico in cui tutto fallisce che l’ansia immagina, ma il peggior caso realistico. Di solito è molto più gestibile di quanto si tema.
I primi 30 giorni
Settimana 1: Decision Sprint
- Lunedì: Raccogliere i dati critici
- Martedì: Interviste agli stakeholder
- Mercoledì: Analisi dei rischi
- Giovedì: Bozza del piano iniziale
- Venerdì: Punto decisionale
Settimane 2-3: Costruire slancio
- Annuncia la decisione con chiarezza
- Configura un centro di comando per la migrazione
- Inizia con azioni piccole e concrete
- Festeggia i primi successi
Settimana 4: Avvio dell'esecuzione
- Lancia il progetto pilota
- Stabilisci cicli di feedback
- Imposta metriche di avanzamento
- Programma checkpoint regolari
In sintesi
La parte più difficile della migrazione non è la sfida tecnica, ma decidere di iniziare. Le barriere psicologiche spesso pesano più di quelle tecniche. La paura del fallimento, il perfezionismo, la ricerca del consenso e il richiamo del "prossimo trimestre" possono paralizzare anche i leader tecnologici più esperti.
Abbiamo anche visto come i CTO di successo riescano a superare questi ostacoli. Non lo fanno eliminando tutti i rischi o raggiungendo un consenso perfetto, ma piuttosto:
- Trasformando paure vaghe in metriche misurabili
- Scomponendo decisioni apparentemente monolitiche in passaggi più piccoli e reversibili
- Costruendo alleanze invece di aspettare l'accordo unanime
- Utilizzando la regola del 70% per andare avanti con "abbastanza" invece che "tutto"
Forse la cosa più importante che abbiamo imparato è che le decisioni di migrazione non avvengono in un solo momento drammatico. Sono il risultato di schemi sistematici, chiari fattori scatenanti e oneste autocritiche.
Le migrazioni di maggior successo che ho visto non sono state quelle con piani perfetti, ma quelle in cui i leader hanno capito e gestito la propria psicologia con la stessa cura dedicata ai sistemi.
Iscriviti alla newsletter di The CTO Club per ulteriori approfondimenti sulla migrazione del software.



{kind=link}