Les 10 Meilleurs Outils de Déploiement de Modèles ML en 2026

Meilleurs outils de déploiement de modèles ML - Sélection


Les outils de déploiement de modèles ML vous permettent de transformer des modèles d'apprentissage automatique entraînés en services prêts pour la production, réellement utilisables. Si vous cherchez des moyens de lancer, surveiller et gérer de manière fiable vos applications alimentées par l’IA, le choix de la bonne plateforme de déploiement est essentiel. Sécurité, mise à l’échelle, automatisation et transparence peuvent faire toute la différence dans votre flux de travail. Dans cette liste, je détaille les outils de déploiement ML auxquels je fais le plus confiance et vous montre exactement où chacun s’intègre dans votre stack, afin que vous puissiez choisir la plateforme qui correspond aux besoins de votre projet et aux attentes de votre équipe.
Table of Contents
- Liste des Meilleurs Logiciels
- Pourquoi Nous Faire Confiance
- Comparer les Caractéristiques
- Avis
- Autres Outils de Déploiement de Modèles ML
- Critiques Liées
- Critères de Sélection
- Comment Choisir
- Qu’est-ce qu’un Outil de Déploiement de Modèles ML ?
- Fonctionnalités
- Bénéfices
- Coûts et Tarification
- Questions Fréquemment Posées
Pourquoi faire confiance à nos avis logiciels
Nous testons et analysons des logiciels depuis 2023. En tant que dirigeants technologiques, nous savons à quel point il est crucial et difficile de faire le bon choix lors de la sélection d’un logiciel.
Nous investissons dans des recherches approfondies pour aider notre audience à prendre de meilleures décisions d’achat de logiciels. Nous avons testé plus de 2 000 outils pour différents usages technologiques et rédigé plus de 1 000 avis complets. Découvrez comment nous restons transparents & notre méthodologie d’évaluation des logiciels.
Résumé des meilleurs outils de déploiement de modèles ML
Ce tableau comparatif résume les détails tarifaires de mes meilleurs choix d’outils de déploiement de modèles ML pour vous aider à trouver celui qui convient à votre budget et aux besoins de votre entreprise.
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | Idéal pour l'orchestration de modèles native Kubernetes | Gratuit à vie | Gratuit à vie | Website | |
| 2 | Idéal pour des APIs d'inférence standardisées sur Kubernetes | Gratuit à vie | Gratuit à vie | Website | |
| 3 | Idéal pour emballer des modèles en tant qu’APIs de production | Plan gratuit + démo gratuite disponible | Tarification sur demande | Website | |
| 4 | Idéal pour l'hébergement de modèles transformer à grande échelle | Plan gratuit + démo gratuite disponible | À partir de $9/mois | Website | |
| 5 | Idéal pour le déploiement de fonctions Python serverless | Plan gratuit disponible | À partir de $250 + calcul/mois | Website | |
| 6 | Idéal pour des workflows unifiés de données et d'IA | Crédits gratuits de 300 $ disponibles | Tarifs sur demande | Website | |
| 7 | Idéal pour créer des interfaces web personnalisées pour les modèles | Offre gratuite disponible | Tarification sur demande | Website | |
| 8 | Idéal pour le service distribué avec Python et Ray | Crédit gratuit de 100 $ disponible | Tarification sur demande | Website |
-

TestDevLab
Visit Website -
Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8


Avis sur les meilleurs outils de déploiement de modèles ML
Ci-dessous figurent mes résumés détaillés des meilleurs outils de déploiement de modèles ML qui composent ma sélection. Mes avis offrent un aperçu détaillé des fonctionnalités, des intégrations et des meilleurs cas d’utilisation de chaque plateforme pour vous aider à choisir le plus adapté à vos besoins.
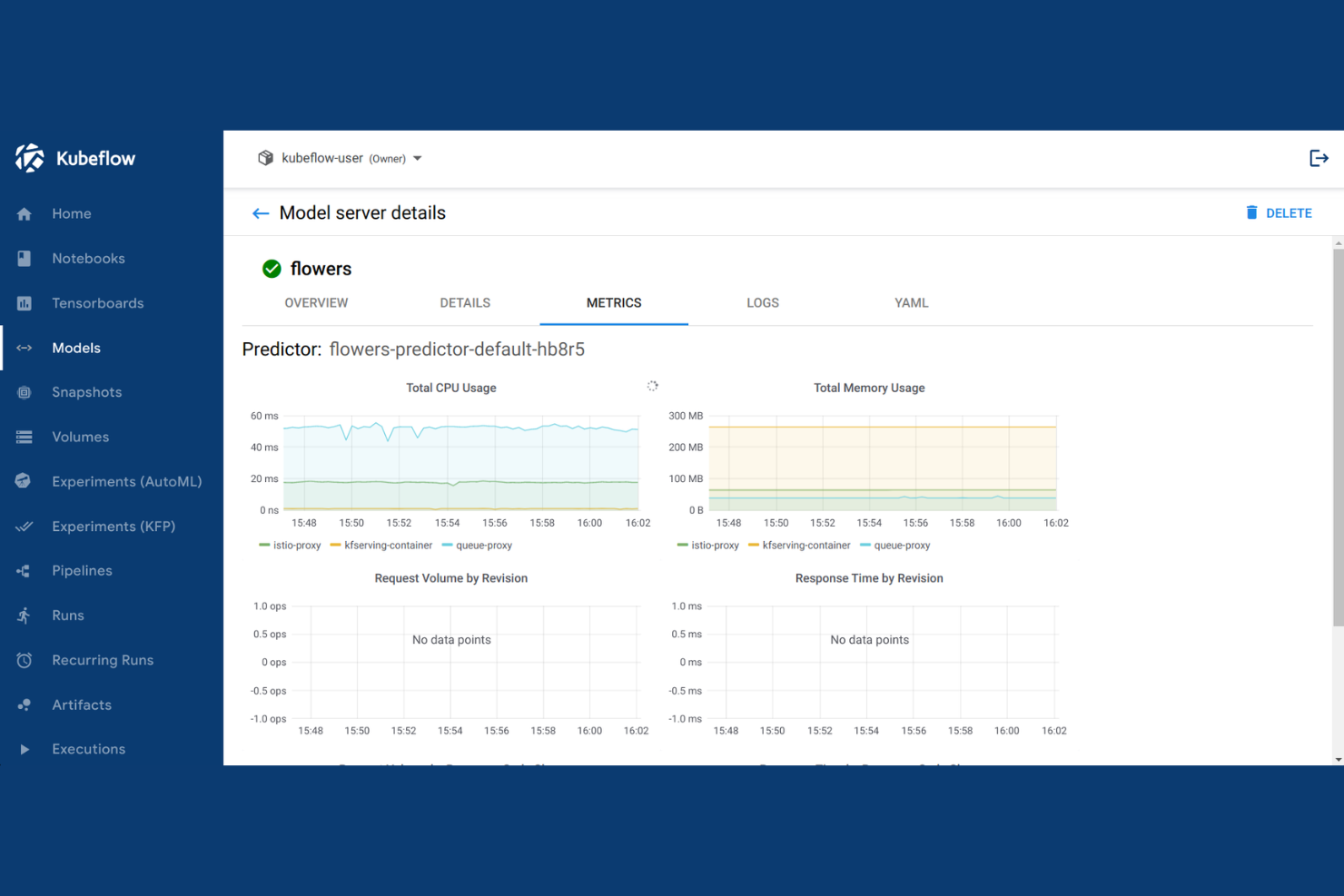
Kubeflow est une plateforme ML open-source construite sur Kubernetes qui couvre l'orchestration des pipelines, l'entraînement des modèles, l'optimisation des hyperparamètres et le service de modèles multi-cadres, que ce soit sur le cloud ou sur une infrastructure sur site.
À qui s'adresse Kubeflow ?
Kubeflow convient particulièrement aux équipes d'ingénierie ML qui utilisent déjà Kubernetes et qui doivent gérer des tâches d'entraînement à grande échelle ainsi que le déploiement de modèles en production sur leur propre infrastructure.
Pourquoi j'ai choisi Kubeflow
J'ai choisi Kubeflow comme l'un des meilleurs outils car il est conçu spécifiquement autour de Kubernetes, ce qui signifie que chaque composant fonctionne comme une charge de travail native Kubernetes. J'apprécie le fait que Kubeflow Pipelines me permette de définir des workflows ML de bout en bout sous forme de DAGs conteneurisés, permettant ainsi à chaque étape de s'adapter indépendamment. Kubeflow Trainer prend en charge l'entraînement distribué avec PyTorch, JAX et DeepSpeed sans configuration personnalisée du cluster. Je peux également utiliser Katib pour lancer des balayages automatisés d'hyperparamètres directement sur les tâches d'entraînement exécutées sur le même cluster.
Fonctionnalités clés de Kubeflow
- KServe : Déployez des modèles entraînés comme services d'inférence évolutifs sur Kubernetes à l'aide d'environnements de service prêts à l'emploi pour TensorFlow, PyTorch et scikit-learn.
- Registre de modèles : Stockez, versionnez et suivez les modèles enregistrés à travers les différents entraînements avant de les promouvoir vers les environnements de production.
- Serveurs de notebooks : Lancez des instances Jupyter notebook directement sur le cluster avec des allocations configurables de CPU, GPU et mémoire.
- Isolation multi-utilisateurs : Gérez des espaces de noms séparés et des contrôles d'accès pour différentes équipes ou projets au sein d'un cluster partagé.
Intégrations de Kubeflow
Kubeflow n'offre pas d'intégrations natives traditionnelles au sens SaaS mais, grâce à son architecture native Kubernetes, il se connecte à un large écosystème d'outils ML et d'infrastructure. Kubeflow Trainer prend en charge l'entraînement distribué sur plusieurs frameworks, notamment PyTorch, HuggingFace, DeepSpeed, JAX et XGBoost. KServe est compatible avec le protocole OpenAI, ce qui permet d'utiliser les bibliothèques clientes OpenAI et des outils comme LangChain et LlamaIndex. Kubeflow Pipelines fonctionne avec Argo Workflows ou Tekton comme backend, et la plateforme s'intègre avec des outils de planification Kubernetes tels que Kueue, Volcano et YuniKorn. Metaflow s'intègre également à Kubeflow, vous permettant de déployer des flows Metaflow sous forme de Pipelines Kubeflow. Une intégration expérimentale de MLflow est en cours en tant que sous-projet de Kubeflow.
Pros and Cons
Pros:
- Déploiements sur tous les principaux fournisseurs Kubernetes cloud
- Chaque étape du pipeline fonctionne dans un conteneur isolé
- Excellents résultats en entraînement distribué et orchestration
Cons:
- La configuration initiale complexe requiert une expertise Kubernetes
- Nécessite une équipe dédiée à la plateforme pour la maintenance
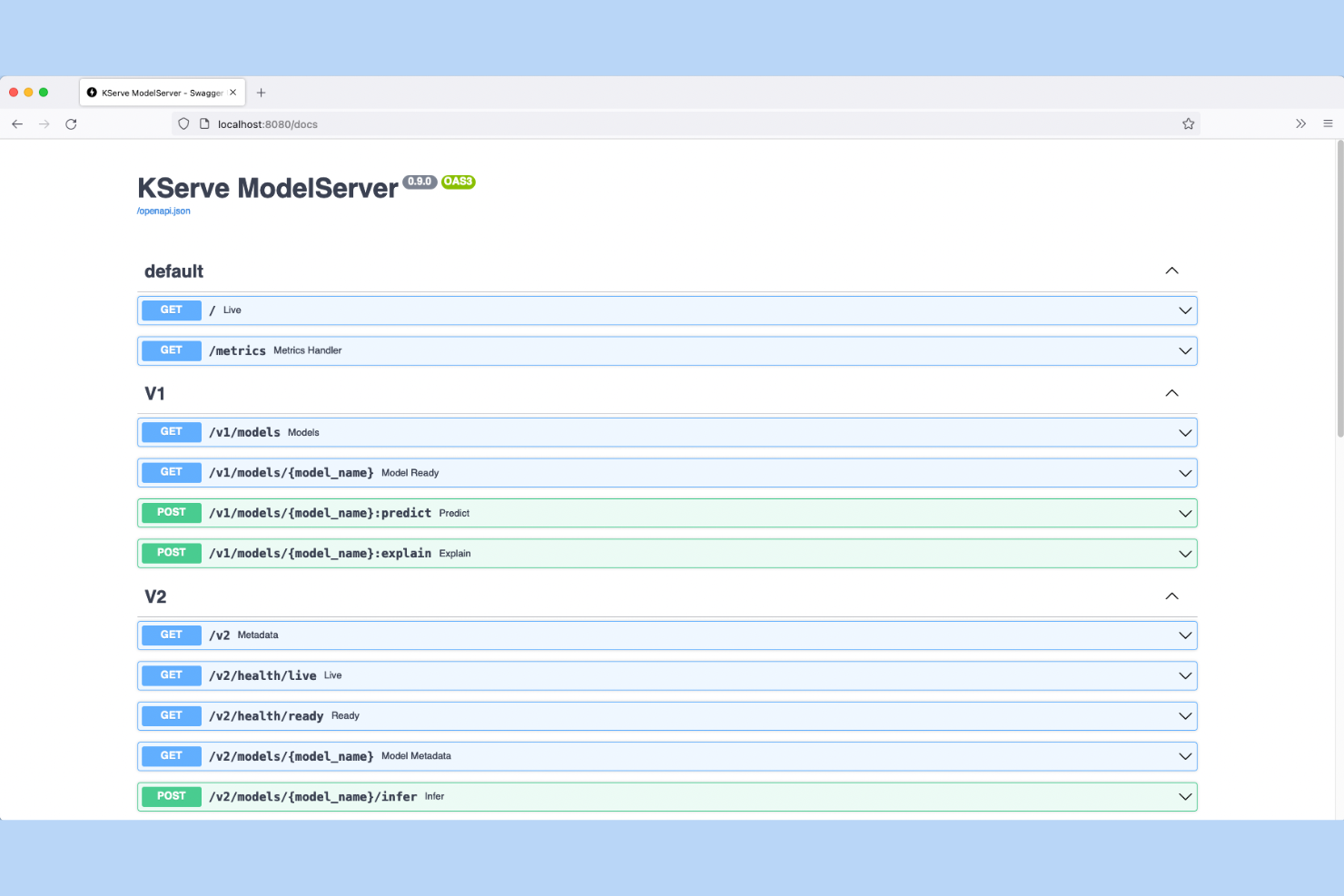
KServe est une plateforme d'inférence de modèles native Kubernetes et open-source qui prend en charge le déploiement multi-cadres de modèles, les déploiements progressifs (canary), l'autoscaling et l'explicabilité des modèles grâce à une couche API d'inférence standardisée.
À qui s'adresse KServe ?
KServe s'adresse particulièrement aux équipes d'ingénierie ML des moyennes et grandes organisations qui opèrent des déploiements de modèles à grande échelle sur Kubernetes et nécessitent une couche d'inférence indépendante du framework.
Pourquoi j'ai choisi KServe
J'ai choisi KServe parmi les meilleurs car il est conçu autour du protocole Open Inference (V2), une spécification d'API standardisée qui permet à mon équipe d'échanger les backends de déploiement, comme Triton ou vLLM, sans réécrire le code client. Je m'appuie également sur son CRD InferenceService pour définir de façon déclarative les déploiements canary, en redirigeant un pourcentage du trafic en production vers une nouvelle version de modèle avant la promotion complète. Les points de terminaison d'inférence REST et gRPC sont tous deux pris en charge, ce qui permet une flexibilité du protocole de transport.
Fonctionnalités clés de KServe
- Autoscaling jusqu'à zéro : L'autoscaling propulsé par Knative met les pods d'inférence à l'arrêt complet lorsqu'ils sont inactifs et les relance à la demande.
- Transformateurs de requêtes/réponses : La logique de pré- et post-traitement s'exécute dans un conteneur transformateur distinct aux côtés du serveur de modèles.
- Déploiements progressifs (canary) : Fait migrer progressivement le trafic vers une nouvelle version du modèle, ce qui permet de tester des modifications en production sans exposition totale.
- Journalisation des charges utiles : Les requêtes et réponses d'inférence sont journalisées vers des destinations configurables pour l'audit et la surveillance des modèles.
Intégrations de KServe
KServe inclut des intégrations natives avec Knative, Istio et l'API Gateway Kubernetes pour une scalabilité serverless et le routage d'entrée. Il est fourni avec des runtimes de service intégrés pour vLLM, llm-d, NVIDIA Triton Inference Server, Seldon MLServer, TorchServe et Hugging Face, et prend en charge le stockage de modèles depuis Amazon S3, Google Cloud Storage et Azure Blob Storage. Un SDK Python Serving ainsi que des API d'inférence REST/gRPC sont disponibles pour les intégrations personnalisées.
Pros and Cons
Pros:
- L'autoscaling jusqu'à zéro réduit le coût des GPU inactifs
- Déploiement indépendant du framework via un protocole d'inférence standardisé
- Déploiements canary intégrés pour des mises à jour sûres
Cons:
- Nécessite une expertise Kubernetes pour fonctionner
- Le mode serverless limite la personnalisation des montages de volumes

Construit autour du concept d'un artefact 'Bento', BentoML est un framework Python natif pour le déploiement de modèles qui gère la définition des services, la conteneurisation et l'emballage multi-framework des modèles pour le déploiement en production.
Pour qui BentoML est-il le plus adapté ?
BentoML convient particulièrement bien aux équipes ML de sociétés en croissance qui doivent passer rapidement d'un modèle entraîné à une API prête pour la production sans plateforme MLOps dédiée.
Pourquoi j'ai choisi BentoML
J'ai inclus BentoML parmi mes favoris car c'est l'un des rares frameworks à traiter l’artefact du modèle et la couche de service comme une seule unité versionnée. J'apprécie le fait que BentoML génère automatiquement des points de terminaison REST et gRPC à partir de la même définition de service, ce qui évite à mon équipe de maintenir des spécifications API séparées. L'abstraction des runners me permet aussi d'isoler chaque modèle dans son propre processus, ce qui signifie qu'une étape de prétraitement sur CPU n’entrera pas en concurrence pour les ressources avec un runner de modèle GPU.
Fonctionnalités clés de BentoML
- Traitement par lots adaptatif : Regroupe automatiquement les requêtes d'inférence simultanées dans un même lot, réduisant la surcharge GPU par requête sans modifications du code.
- Métriques Prometheus intégrées : Expose un point de terminaison /metrics prêt à l'emploi pour surveiller la latence et le débit des requêtes sans instrumentation personnalisée.
- Passerelle LLM : Fournit une interface API unifiée pour plusieurs fournisseurs de LLM, vous permettant de centraliser le routage et la gestion des coûts.
- Construction d’image conteneurisée : Génère une image Docker prête pour la production directement à partir d’un artefact Bento en une seule commande CLI.
Intégrations de BentoML
BentoML propose des intégrations documentées avec des outils de l’écosystème MLOps, dont Airflow, MLflow, Ray, Spark, Arize AI, Flink et Triton Inference Server. Il s’intègre également à Datadog pour la collecte des métriques des services BentoML. Une API est disponible pour des intégrations personnalisées, et la sortie conteneurisée de BentoML fonctionne nativement avec Kubernetes et Docker pour offrir une flexibilité de déploiement.
Pros and Cons
Pros:
- Versionnement et suivi des retours de modèles intégrés
- Génère des conteneurs Docker à partir d’une configuration YAML
- Gère les requêtes concurrentes par le scaling des workers
Cons:
- Les fichiers de configuration peuvent sembler inutilement complexes
- Les loaders personnalisés nécessitent une configuration supplémentaire
Idéal pour l'hébergement de modèles transformer à grande échelle
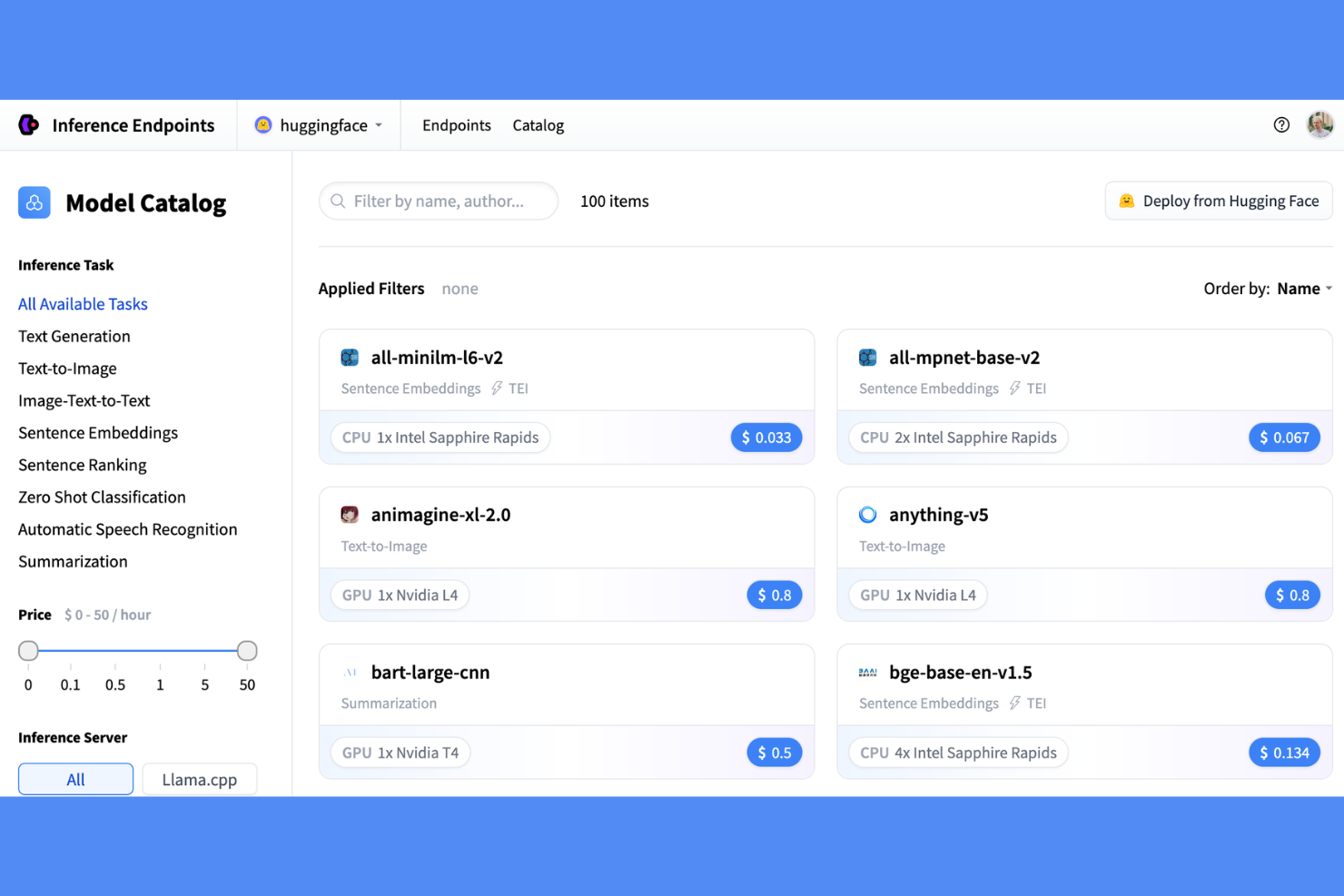
Une plateforme d'inférence gérée construite sur le Hugging Face Hub, Hugging Face Inference Endpoints prend en charge le déploiement cloud dédié, la configuration des points de terminaison et la sélection du matériel pour les modèles ML sur AWS, Azure et Google Cloud.
À qui s'adresse Hugging Face Inference Endpoints ?
Il convient particulièrement aux startups axées sur l'IA et aux entreprises technologiques de taille moyenne qui ont besoin d'une solution d'hébergement de modèles prête pour la production sans avoir à construire et maintenir leur propre infrastructure de service.
Pourquoi j'ai choisi Hugging Face Inference Endpoints
Hugging Face Inference Endpoints mérite sa place dans ma sélection car il est spécialement conçu pour l'écosystème des modèles de type transformer, d'une manière qu'aucune autre plateforme de déploiement ne propose. Mon équipe peut prendre n'importe quel modèle du Hub, y compris les grands LLM et les transformers multimodaux, et le mettre en service à l'échelle de la production avec des règles d'autoscaling configurables qui s'adaptent au trafic réel. J'apprécie également la rapidité de mise en service : un modèle qui nécessiterait des jours pour être conteneurisé et déployé manuellement passe en production en quelques minutes.
Fonctionnalités clés de Hugging Face Inference Endpoints
- Déploiement multi-cloud : Choisissez de déployer votre point de terminaison sur AWS, Azure ou Google Cloud sans gérer de comptes cloud séparés.
- Réseau privé : Isolez vos points de terminaison dans un VPC dédié afin que seuls vos systèmes internes puissent accéder à l'API du modèle.
- Authentification par jeton : Sécurisez chaque point de terminaison avec un jeton d'API afin de contrôler quels services ou utilisateurs peuvent envoyer des requêtes d'inférence.
- Suivi de l'utilisation : Suivez le volume des requêtes, la latence et le taux d'erreur directement depuis le tableau de bord du point de terminaison en temps réel.
Intégrations de Hugging Face Inference Endpoints
Hugging Face Inference Endpoints fonctionne avec un écosystème croissant d'outils de développement, de frameworks et de plateformes, et les outils non explicitement pris en charge sont souvent compatibles grâce à son API compatible OpenAI. Les intégrations documentées incluent AWS Bedrock et SageMaker, Google Gemini Enterprise Agent Platform, et Azure AI Foundry, ainsi que des frameworks LLM comme LangChain, LlamaIndex, Haystack, CrewAI et PydanticAI. Inference Endpoints peut être entièrement géré via API, avec des points de terminaison documentés via Swagger, ce qui permet de créer des intégrations personnalisées. La compatibilité avec Zapier n'est pas clairement documentée.
Pros and Cons
Pros:
- Déploiement en un clic depuis le Hugging Face Hub
- Prise en charge de plusieurs moteurs d'inférence
- Autoscaling avec facturation à l'arrêt complet
Cons:
- Temps de démarrage à froid lors de l'activation depuis zéro
- Les coûts de calcul GPU augmentent rapidement à grande échelle
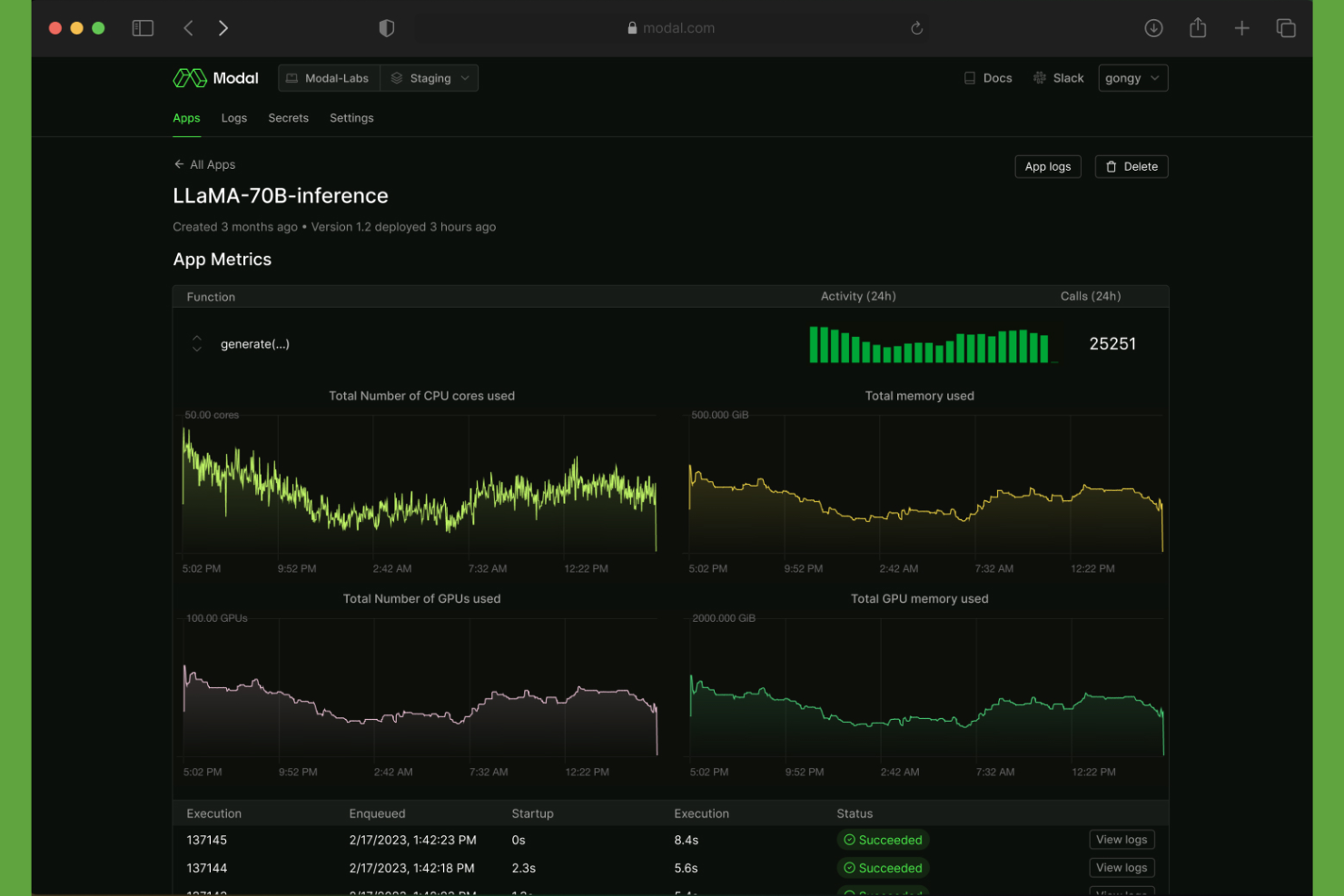
Modal est une plateforme cloud serverless pour exécuter des charges de travail ML basées sur Python, couvrant l'inférence accélérée par GPU, les tâches par lot, les sessions d'entraînement et les tâches planifiées, sans aucune gestion de conteneurs ou d'infrastructures.
À qui s'adresse Modal ?
C'est une solution idéale pour les startups et les équipes en croissance qui doivent déployer rapidement des modèles ML sans recruter d'ingénieurs d'infrastructure dédiés.
Pourquoi j'ai choisi Modal
J'ai inclus Modal dans mes meilleures sélections car il élimine l'écart entre l'écriture du code Python et son exécution à grande échelle sur des GPU. Je peux demander un matériel spécifique, comme un A100 ou un H100, directement dans la définition de ma fonction et Modal le provisionne à la demande. Il n'y a aucun cluster à gérer, ni YAML à rédiger. J'apprécie également que la même fonction s'exécute de façon identique localement et en production, ce qui réduit considérablement le temps de débogage.
Fonctionnalités clés de Modal
- Images de conteneur personnalisées : Définit les dépendances, les variables d'environnement et les paquets systèmes directement dans le code, garantissant des environnements d'exécution cohérents à travers les déploiements.
- Volumes persistants : Monter des volumes cloud pour mettre en cache les poids des modèles entre les exécutions, réduisant ainsi le temps de démarrage à froid lors de déploiements répétés.
- Gestion des secrets : Stocke et injecte de manière sécurisée les clés API et les identifiants d'accès à l'exécution, sans les coder en dur dans la base de code.
- Exécution par lot en parallèle : Utilise .map() pour lancer l'inférence sur de grands ensembles de données en parallèle à travers plusieurs conteneurs simultanément.
Intégrations Modal
Modal propose un petit ensemble d'intégrations documentées axées sur l'observabilité et les notifications, notamment Datadog, tout fournisseur compatible OpenTelemetry, Slack et Okta SSO. Il prend également en charge le montage de buckets cloud pour AWS S3, Google Cloud Storage et Cloudflare R2, ainsi que les flux CI/CD via GitHub Actions. Le support Zapier n'est pas documenté, mais Modal fournit un SDK Python et des endpoints web permettant des intégrations personnalisées.
Pros and Cons
Pros:
- Aucun Dockerfile ou configuration Kubernetes requis
- Gère l'apprentissage, le traitement par lots et l'inférence
- Orchestre les charges de travail entre clouds et régions
Cons:
- Le code basé sur des décorateurs crée une dépendance au fournisseur
- Les fonctionnalités pour entreprises nécessitent un abonnement premium
Idéal pour des workflows unifiés de données et d'IA
La plateforme Gemini Enterprise Agent (anciennement Vertex AI) est la plateforme de ML de bout en bout de Google Cloud qui couvre l'entraînement, l'ajustement, l'évaluation, le déploiement des modèles et le développement d'agents IA, le tout au sein d'un environnement géré unique.
Pour qui la plateforme Gemini Enterprise Agent est-elle idéale ?
La plateforme Gemini Enterprise Agent est un choix naturel pour les équipes d'ingénierie ML et de data science qui exploitent déjà leur infrastructure de données sur Google Cloud Platform.
Pourquoi j'ai choisi la plateforme Gemini Enterprise Agent
J'ai inclus la plateforme Gemini Enterprise Agent dans mes meilleures sélections car elle abolit véritablement l'écart entre la gestion des données et celle des modèles. J'apprécie particulièrement la manière dont les Pipelines de Gemini Enterprise Agent Platform se connectent directement à BigQuery, ce qui permet à mon équipe de construire des pipelines d'entraînement sur des données d'entrepôt en direct sans rien exporter. La Gemini Enterprise Agent Platform Feature Store nous permet également de définir, servir et surveiller les caractéristiques de façon cohérente, à la fois pour l'entraînement et l'inférence, ce qui élimine une source majeure de divergences entre entraînement et mise en production.
Fonctionnalités clés de la plateforme Gemini Enterprise Agent
- Registre de modèles Gemini Enterprise Agent Platform : Un référentiel centralisé pour la gestion des versions, l'organisation et la gestion des modèles tout au long de leur cycle de vie, avant et après le déploiement.
- Points de terminaison de prédiction en ligne : Déployez des modèles vers des points de terminaison dédiés servant des prédictions en temps réel, avec informatique configurable et répartition du trafic entre plusieurs versions de modèle.
- Surveillance des modèles Gemini Enterprise Agent Platform : Détecte les dérives de caractéristiques et de prédictions dans les modèles déployés en comparant le trafic en direct à une base de données d'entraînement de référence.
- Expériences Gemini Enterprise Agent Platform : Suit, compare et visualise les entraînements itératifs, facilitant l'identification par les équipes des configurations de modèles les plus performantes.
Intégrations Gemini Enterprise Agent Platform
Gemini Enterprise Agent Platform s'intègre nativement dans l'écosystème Google Cloud, notamment BigQuery, Cloud Storage, Dataflow et Pub/Sub, et offre la compatibilité avec Kubeflow Pipelines ainsi que des conteneurs préconstruits pour TensorFlow, scikit-learn, XGBoost et PyTorch. Ses magasins de données prennent aussi en charge des connecteurs de données tiers pour des outils comme Jira et Shopify. Elle est disponible sur Zapier, et une API existe pour des intégrations personnalisées.
Pros and Cons
Pros:
- Model Garden propose plus de 200 modèles déployables
- Le déploiement via des points de terminaison depuis Model Garden est simple
- Intégration native avec BigQuery pour les workflows de données
Cons:
- Des points de terminaison dédiés inactifs génèrent malgré tout des frais
- Les erreurs dues à des incohérences de régions sont peu explicites
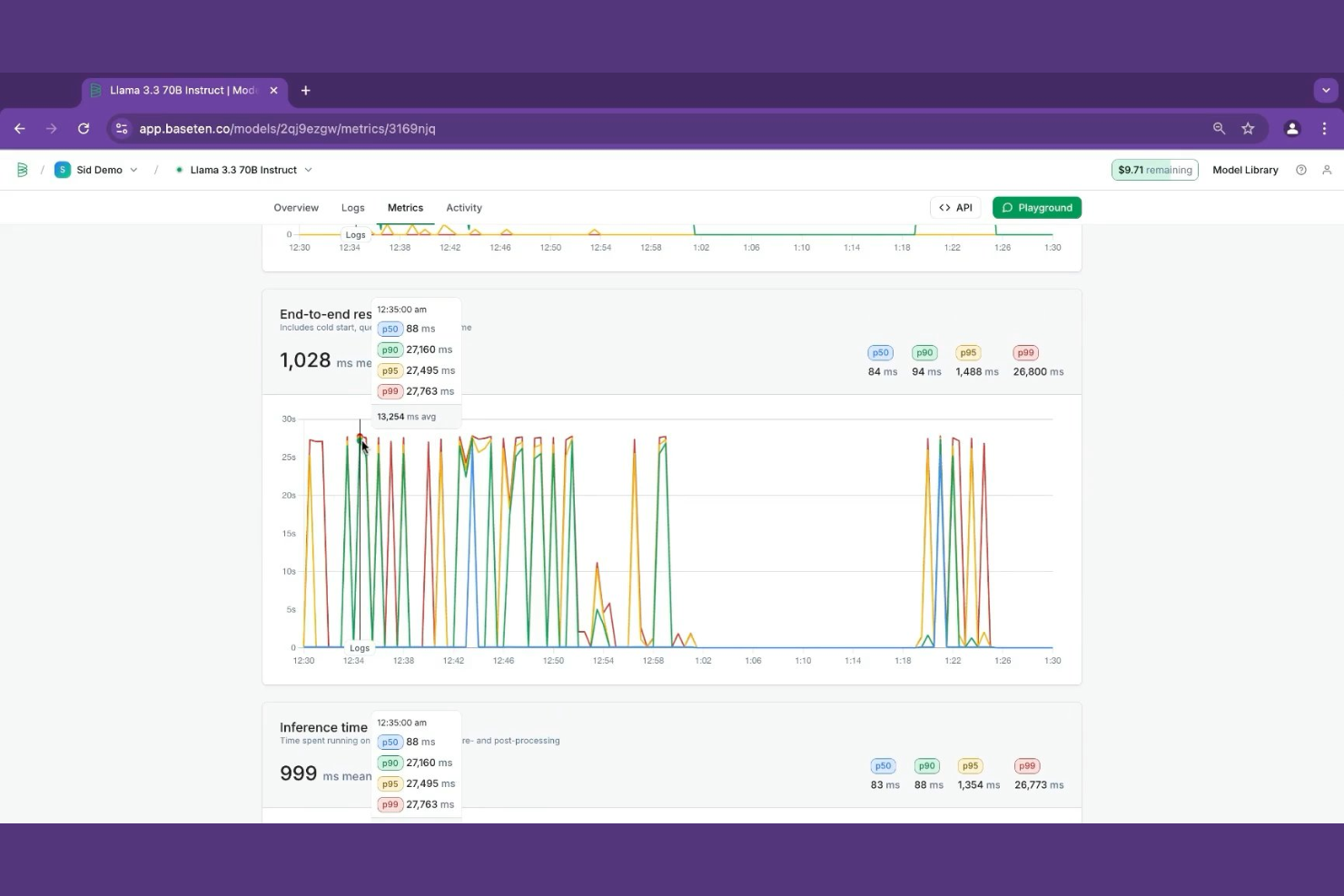
Baseten est une plateforme d'inférence de modèles qui permet aux équipes ML de déployer des modèles personnalisés, open source et ajustés, avec une distribution accélérée par GPU, une mise à l'échelle automatique et des outils d'optimisation des performances intégrés directement à la plateforme.
À qui s'adresse Baseten ?
Baseten convient aux équipes de produits IA dans les entreprises en croissance qui ont besoin d'un contrôle total sur les performances d'inférence pour des déploiements de modèles sensibles à la latence ou à haut volume.
Pourquoi j'ai choisi Baseten
Baseten trouve sa place sur ma liste restreinte car il vous permet de créer et de déployer des interfaces web personnalisées sur vos modèles au sein de la même plateforme, sans nécessiter une pile frontend distincte. J'utilise le concepteur d'applications de Baseten pour créer des interfaces interactives qui appellent directement les points de terminaison du modèle, ce qui est utile pour les outils internes ou les démonstrations aux parties prenantes. Le modèle et son interface restent versionnés et déployés ensemble.
Fonctionnalités clés de Baseten
- Emballage de modèles Truss : Emballez tout modèle personnalisé ou ajusté sous la forme d'un artefact Python reproductible avec gestion des dépendances intégrée et rechargement en direct pour les tests locaux.
- Baseten Chains : Construisez des workflows d'IA composés de plusieurs étapes où chacune s'exécute sur du matériel configuré indépendamment avec sa propre politique de mise à l'échelle automatique.
- Gestion des secrets : Stockez et injectez les clés d'API et les identifiants d'environnement directement dans les déploiements de modèles sans les coder en dur dans votre code de service.
- Répartition de trafic A/B : Dirigez le trafic d'inférence en direct entre plusieurs versions de modèles simultanément pour comparer les performances avant de passer entièrement à un nouveau déploiement.
Intégrations Baseten
Baseten prend en charge l'exportation des métriques vers Prometheus, Datadog, Grafana Cloud et New Relic via son point de terminaison de métriques basé sur OpenTelemetry. Il est entièrement compatible avec OpenAI, vous pouvez donc le connecter à tout client ou passerelle utilisant le SDK OpenAI, y compris LiteLLM, LlamaIndex et Cloudflare AI Gateway. Une API est disponible pour des intégrations personnalisées.
Pros and Cons
Pros:
- L'emballage open source Truss simplifie le déploiement des modèles
- Déploiement en un clic à partir des checkpoints d'entraînement
- Démarrages à froid sous la seconde sur les instances GPU
Cons:
- La tarification basée sur l'utilisation peut augmenter de façon imprévisible
- Nécessite une expertise en ingénierie ML pour fonctionner
{kind=link}
Construit sur le framework open source Ray, Anyscale est une plateforme de gestion et de déploiement de modèles ML qui gère l'inférence distribuée, l'autoscaling et le déploiement multi-modèles sur les clusters GPU et CPU.
À qui s'adresse Anyscale ?
Anyscale est idéal pour les ingénieurs en apprentissage automatique et les équipes data science travaillant dans des organisations de taille moyenne à grande qui exécutent des charges de travail Python à grande échelle et souhaitent gérer des clusters GPU sans la complexité de gestion manuelle de l'infrastructure.
Pourquoi j'ai choisi Anyscale
J'ai choisi Anyscale comme l'une des meilleures plateformes car c'est la seule plateforme managée conçue directement sur Ray, ce qui signifie que mon équipe peut écrire du code Python standard pour définir la logique de service distribué sans avoir à apprendre un langage d'orchestration séparé. J'apprécie particulièrement l'API de graphe de déploiement Ray Serve, qui me permet de composer plusieurs modèles dans un même pipeline d'inférence avec un routage explicite des requêtes. L'allocation fractionnaire de GPU est une autre fonctionnalité que j'utilise régulièrement pour regrouper des modèles légers sur la même machine sans avoir à lancer des instances dédiées.
Fonctionnalités clés d'Anyscale
- Autoscaling : Met automatiquement à l'échelle le nombre de réplicas en fonction du débit des requêtes en temps réel et de la profondeur de la file d’attente.
- Répartition du trafic : Permet de router un pourcentage configurable du trafic vers de nouvelles versions de modèles pour un déploiement progressif sans interruption.
- Regroupement des requêtes : Regroupe les requêtes d’inférence entrantes par lots pour maximiser l'utilisation du GPU lors des appels concurrents.
- Service de modèles multi-nœuds : Répartit un modèle volumineux sur plusieurs nœuds lorsqu’il dépasse la mémoire disponible sur un seul GPU.
Intégrations d'Anyscale
Anyscale s'intègre avec les principales bibliothèques et frameworks IA/ML, avec plus de 50 intégrations couvrant les plateformes de données, l'orchestration, les frameworks ML, l'observabilité et les frameworks applicatifs pour LLM. Cela inclut MLflow, Weights & Biases, MongoDB, Snowflake, Databricks, Hugging Face, PyTorch et TensorFlow, ainsi qu'Airflow, Prefect, Dagster, Datadog, LangChain et LlamaIndex. Une API est disponible pour les intégrations personnalisées, et la plateforme peut également être déployée en tant que service natif sur Amazon EKS, Google GKE, Azure AKS et OCI Kubernetes Engine.
Pros and Cons
Pros:
- Mise à l'échelle du code Python sur des clusters GPU distribués
- Service de modèles indépendant des frameworks via Ray Serve
- Prise en charge des instances spot avec tolérance aux pannes automatique
Cons:
- Étroitement lié à l'écosystème Ray
- Nécessite une solide expertise des systèmes distribués
Come Valuto gli Strumenti di Deploy dei Modelli ML
Valuto ogni strumento su due livelli: il livello di base per pubblicare un modello PyTorch su un endpoint REST con autoscaling e monitoraggio del drift, e i fattori differenzianti che contano per i team MLOps.
Funzionalità Principali (Requisiti Fondamentali per Questa Lista)
Quando seleziono gli strumenti per la mia lista, valuto ciascuno su una scala da 0 (non offre la funzionalità) a 5 (eccelle in quest'area) per ciascuna delle funzionalità principali elencate di seguito. Poi calcolo il punteggio totale dello strumento in percentuale. Ogni strumento deve raggiungere un punteggio totale minimo del 65% per essere considerato idoneo all'inclusione.
- Servizio del Modello & Inferenza: Valuto se uno strumento può ospitare modelli dietro endpoint REST o gRPC per predizioni in tempo reale, e se gestisce anche l'inferenza batch per lavori di scoring offline.
- Supporto Multi-Framework: Controllo quali framework ML sono supportati nativamente—come TensorFlow, PyTorch, XGBoost e ONNX—e se sono disponibili container personalizzati per runtime meno comuni.
- Versionamento del Modello & Registry: Un buon registro permette di tracciare gli artefatti dei modelli, i metadati e la loro provenienza, così da poter annullare un deploy problematico in pochi minuti invece di cercare disperatamente l'artefatto giusto.
- Scalabilità & Gestione delle Risorse: Valuto come funziona l'autoscaling sotto carico, se l'allocazione di GPU e CPU è configurabile e se lo strumento supporta il "scale-to-zero" per ridurre i costi nei periodi di inattività.
- Monitoraggio & Osservabilità: I modelli in produzione degradano silenziosamente, quindi cerco la rilevazione del drift dei dati, il monitoraggio della latenza delle predizioni e un sistema di allerta che segnali problemi di performance prima che impattino gli utenti finali.
- CI/CD & Automazione del Deploy: Considero se lo strumento supporta pipeline automatizzate con strategie di rollout progressive come canary o A/B test, oltre a trigger basati su Git per la ridistribuzione dei modelli.
Una volta che ho una lista di strumenti che soddisfano questi criteri, considero ciò che rende ogni piattaforma unica.
Fattori Differenzianti (Cosa Distingue i Vendor)
Ecco come confronto e metto a contrasto diversi vendor:
Funzionalità Distintive
I deploy canary e shadow rendono alcuni strumenti unici. Cerco la capacità di indirizzare una parte del traffico live verso una nuova versione del modello mentre quella attuale continua a servire—questo permette di individuare regressioni di accuratezza prima che raggiungano tutti gli utenti. L'ottimizzazione GPU è un altro elemento distintivo: il batching dinamico e il supporto alla quantizzazione tramite acceleratori come NVIDIA Triton o TensorRT possono ridurre drasticamente i costi per predizione ad alto volume. Lo scale-to-zero è altrettanto importante, poiché endpoint inattivi che consumano ore GPU fanno lievitare subito i costi in carichi di lavoro ad alta inferenza.
Oltre le Funzionalità
La capacità di integrarsi nell'ecosistema MLOps è fondamentale—controllo se uno strumento si collega a tracker di esperimenti come MLflow o Weights & Biases, orchestratori come Airflow e sistemi CI/CD come GitHub Actions. La flessibilità dell'infrastruttura è altrettanto importante: i team nei settori regolamentati spesso necessitano di soluzioni self-hosted Kubernetes o opzioni BYOC invece di SaaS puro. Valuto anche la governance e la conformità, in particolare RBAC, audit logging e certificazioni come SOC 2 o HIPAA, che i team di sicurezza aziendale richiederanno durante la fase di acquisto.
Comment choisir un outil de déploiement de modèles ML
Il est facile de se perdre dans des listes de fonctionnalités interminables et des structures tarifaires complexes. Pour vous aider à rester concentré lors de votre propre processus de sélection logicielle, voici une liste de points à avoir à l'esprit :
| Critère | À prendre en compte |
|---|---|
| Mise à l'échelle | L’outil peut-il gérer une augmentation soudaine du trafic d’inférence sans intervention manuelle ? Vérifiez s'il prend en charge à la fois les pics et les périodes de faible charge. |
| Intégrations | La plateforme se connecte-t-elle nativement à vos systèmes de suivi des expériences, outils CI/CD ou entrepôts de données, ou devrez-vous développer et maintenir du code personnalisé ? |
| Personnalisation | Pouvez-vous adapter les workflows de déploiement, les contrôles d’accès aux modèles et la gestion des ressources à vos politiques et structures d’équipe ? |
| Facilité d’utilisation | Quelle est la courbe d’apprentissage pour votre équipe ? Pensez à la complexité de l'interface, la qualité de la documentation et l'impact de l'intégration sur vos autres projets. |
| Mise en œuvre et intégration | Combien de temps d’ingénierie êtes-vous prêt à investir pour passer de l’essai à la production ? Attention aux étapes d'installation cachées, prérequis réseau ou formations obligatoires. |
| Coût | Les modèles de tarification sont-ils transparents et prévisibles à mesure que la consommation augmente ? Comparez les méthodes de facturation : par prédiction, heure de calcul ou point d'accès, selon vos charges de travail. |
| Mesures de sécurité | Quels mécanismes de chiffrement, de contrôle d'accès et d’audit sont prévus ? Vérifiez si la solution répond à vos standards internes de sécurité et aux exigences de vos clients. |
| Exigences de conformité | Avez-vous besoin de la conformité HIPAA, RGPD ou SOC 2 Type II ? Assurez-vous que le fournisseur fournit les attestations nécessaires et supporte la traçabilité requise pour votre secteur. |
Qu’est-ce qu’un outil de déploiement de modèles ML ?
Les outils de déploiement de modèles ML sont des plateformes qui vous aident à opérationnaliser les modèles de machine learning entraînés, en les rendant disponibles via des API ou des points de terminaison batch pour des usages réels. Ces outils gèrent des tâches telles que la mise en service des modèles, la montée en charge, la surveillance et la gestion des versions afin que vous puissiez fournir des prédictions fiables et maintenir la fiabilité alors que les charges de travail évoluent.
Fonctionnalités des outils de déploiement de modèles ML
Lors du choix d'un outil de déploiement de modèles ML, veillez à prendre en compte les caractéristiques clés suivantes :
- Compatibilité multi-cadres : Déployez des modèles créés avec TensorFlow, PyTorch, scikit-learn, XGBoost, et ONNX sans devoir réécrire le code du modèle ou effectuer des étapes de conversion.
- Inférence à mise à l’échelle automatique : Alloue automatiquement les ressources de calcul selon les flux de trafic, gérant les pics soudains ou les périodes calmes pour garantir à la fois performance et optimisation des coûts.
- Gestion des versions de modèle : Suit les différentes versions des modèles, facilitant les retours en arrière, les comparaisons ou la promotion de versions dans le pipeline de production avec un minimum d’interruptions.
- Déploiements canari et shadow : Permet des déploiements progressifs ou le clonage du trafic réel, afin de valider de nouveaux modèles de manière sécurisée sur des données réelles avant un déploiement complet.
- Service batch et temps réel : Prend en charge à la fois l’API temps réel et le traitement batch asynchrone pour plus de flexibilité selon les applications métiers ou les workflows data science.
- Gestion des ressources : Permet d’allouer et de surveiller l’utilisation CPU, GPU et mémoire pour chaque modèle, optimisant ainsi les coûts et la santé des services en production.
- Garanties de sécurité : Offre le contrôle d’accès, le chiffrement, et l’isolement réseau pour protéger les artefacts des modèles et les données d’inférence sensibles.
- Support d’intégration : Se connecte nativement ou via API aux outils MLOps, pipelines CI/CD et aux infrastructures de données pour faciliter le déploiement et la surveillance continus.
- Journalisation et supervision : Donne de la visibilité sur les journaux de requêtes, les métriques de latence et les taux d’erreurs pour un dépannage proactif et une exploitation fiable.
- Conformité et auditabilité : Propose des fonctions telles que la traçabilité des opérations et le support à la conformité réglementaire, aidant à répondre aux exigences des secteurs réglementés comme la santé, la finance ou d’autres domaines soumis à la conformité.
Fonctionnalités courantes d’IA dans les outils de déploiement de modèles ML
Au-delà des fonctionnalités de base citées ci-dessus, nombre de ces solutions intègrent aujourd’hui l’IA avec des fonctions telles que :
- Détection automatique des dérives : Utilise l’IA pour surveiller les données entrantes et les prédictions pour détecter des changements de distribution, alertant les équipes lorsqu'un ré-entraînement ou une enquête est nécessaire pour maintenir la justesse du modèle.
- Allocation intelligente des ressources : Applique des algorithmes IA pour prédire les profils de charges et ajuster dynamiquement les ressources de calcul, réduisant ainsi les coûts et la latence sans intervention manuelle.
- Déploiements auto-restaurés : Exploite l’IA pour détecter les points de terminaison de modèles défaillants ou dégradés et rediriger le trafic ou déclencher automatiquement un redéploiement, minimisant ainsi les interruptions et l’intervention humaine.
- Dimensionnement prédictif : Utilise l’IA pour anticiper les pics ou baisses de trafic à partir de l’historique d’utilisation, adaptant proactivement l’infrastructure pour garantir des performances constantes et maîtriser les coûts.
- Détection d’anomalies lors de l’inférence : Recourt à l’IA pour signaler en temps réel les requêtes de prédiction inhabituelles ou suspectes, aidant les équipes à identifier d’éventuels problèmes de qualité de données ou menaces à la sécurité.
- Analyse automatisée de la cause racine : Utilise l’IA pour analyser les journaux et métriques, identifiant la source d’une dégradation des performances ou d’erreurs afin que les équipes puissent résoudre rapidement les problèmes sans tâtonner.
Bénéfices des outils de déploiement de modèles ML
L'adoption d'outils de déploiement de modèles ML apporte plusieurs avantages pour votre équipe et votre entreprise. Voici quelques bénéfices auxquels vous pouvez vous attendre :
- Cycles de déploiement accélérés : Les processus automatisés d’empaquetage, de gestion de versions et l’intégration avec les pipelines CI/CD permettent aux équipes de passer rapidement des modèles du développement à la production.
- Extensibilité cohérente : L’auto-scalabilité et la gestion dynamique des ressources garantissent que vos déploiements restent stables et réactifs face à l’évolution de la demande.
- Renforcement de la posture de sécurité : Le contrôle d’accès intégré, le chiffrement et la journalisation des audits contribuent à protéger les modèles et les données sensibles conformément aux exigences réglementaires et organisationnelles.
- Réduction de la charge opérationnelle : La surveillance, les alertes et la journalisation centralisées réduisent le dépannage manuel et libèrent les ressources d’ingénierie pour se concentrer sur des tâches à plus forte valeur ajoutée.
- Gouvernance fiable des modèles : La gestion des versions et la journalisation des déploiements facilitent le suivi des modèles, le retour en arrière des modifications et la démonstration de conformité lors des audits.
- Intégration flexible des flux de travail : La prise en charge de plusieurs frameworks, stratégies de déploiement et configurations d’environnement permet aux équipes d’adapter les outils à leurs besoins métiers.
- Meilleure préparation à la conformité : Des pistes d’audit complètes et des fonctionnalités dédiées à la conformité facilitent le respect de la législation comme HIPAA, RGPD ou des exigences sectorielles spécifiques, réduisant ainsi les risques pour les entreprises réglementées.
Coûts et tarification des outils de déploiement de modèles ML
Choisir des outils de déploiement de modèles ML nécessite de bien comprendre les différents modèles et formules de tarification proposés. Les coûts varient selon les fonctionnalités, la taille de l’équipe, les modules complémentaires, et d’autres facteurs. Le tableau ci-dessous résume les formules courantes, leurs prix moyens et les fonctionnalités typiquement incluses dans les solutions de déploiement de modèles ML :
Tableau comparatif des formules pour les outils de déploiement de modèles ML
| Type de formule | Prix moyen | Fonctionnalités courantes |
|---|---|---|
| Formule gratuite | $0 | Déploiements limités, surveillance de base, accès utilisateur unique et support communautaire. |
| Formule personnelle | $10-$30/user/month | Usage individuel, gestion standard des versions de modèle, allocation de ressources modérée et support par email. |
| Formule entreprise | $40-$100/user/month | Collaboration en équipe, auto-scalabilité, support à l’intégration, sécurité avancée et contrôles d’accès par rôle. |
| Formule grande entreprise | $150-$500+/user/month | Conformité avancée, support premium, infrastructure dédiée, SLA personnalisés et outils étendus d’audit et de sécurité. |
FAQ sur les outils de déploiement de modèles ML
Voici quelques réponses aux questions fréquentes concernant les outils de déploiement de modèles ML :
En quoi les outils de déploiement de modèles ML diffèrent-ils des outils de déploiement d’applications traditionnels ?
Les outils de déploiement de modèles ML sont conçus pour relever les défis spécifiques liés à la mise en service, à la surveillance et à la mise à jour des modèles de machine learning, notamment la gestion des versions de modèles, le suivi des journaux d’inférence, la prise en charge de l’auto-scalabilité pour le trafic de modèles et l’intégration avec les pipelines de données. Les outils traditionnels de déploiement d’applications ne couvrent généralement pas ce type de besoins.
Puis-je déployer des modèles créés avec différents frameworks via le même outil de déploiement ?
Oui, la plupart des outils de déploiement de modèles ML proposent une compatibilité multi-frameworks, ce qui vous permet de déployer des modèles issus de TensorFlow, PyTorch, XGBoost, et plus encore, sans conversions ni réécritures manuelles. Cela facilite la collaboration des équipes avec différentes technologies et la standardisation des processus de mise en production.
Quelles sont les fonctionnalités de sécurité à privilégier dans ces outils ?
Recherchez des fonctionnalités comme le contrôle d’accès, le chiffrement des points de terminaison, les pistes d’audit et l’isolation réseau. Elles permettent de s’assurer que seuls les utilisateurs autorisés peuvent déployer ou mettre à jour les modèles et protègent les modèles et les prédictions de données.
Ces outils prennent-ils en charge l’inférence temps réel et l’inférence par lots ?
Oui, les principaux outils de déploiement de modèles ML prennent en charge à la fois l’inférence temps réel via API et les modes de traitement par lots. Cela offre à votre équipe la flexibilité de gérer différents cas d’usage, des applications orientées utilisateurs aux grands traitements hors ligne.
Comment ces outils facilitent-ils la surveillance et la maintenance des modèles ?
Ils proposent des tableaux de bord de surveillance intégrés, des alertes, de la journalisation et la détection automatisée de dérive. Ces fonctionnalités permettent de détecter rapidement toute dégradation de performance, problème de données ou erreur opérationnelle – souvent avant que cela n’impacte les utilisateurs finaux ou les résultats business.