Leadership dans les tests : Test des services

Note de la rédaction : Bienvenue dans la série Leadership In Test, proposée par le gourou et consultant en tests logiciels Paul Gerrard. Cette série a pour objectif d’aider les testeurs ayant quelques années d’expérience—en particulier ceux travaillant en équipes agiles—à s’épanouir dans leur rôle de lead test ou de manager.
Dans l’article précédent, nous avons examiné l’évolution du rôle des testeurs ainsi que les moyens de favoriser une meilleure collaboration avec vos collègues. Dans cet article, nous allons aborder les aspects fondamentaux du test de la performance, de la fiabilité et de la gestion d’une application web, autrement dit le test de service.
Abonnez-vous à la newsletter The QA Lead pour être informé de la publication des nouveaux articles de la série. Ces articles sont des extraits du cours Leadership In Test de Paul que nous vous recommandons vivement pour approfondir ce sujet et bien d’autres. Utilisez notre code promo exclusif QALEADOFFER pour bénéficier de 60 $ de réduction sur le prix total du cours !
Bonjour et bienvenue dans un nouveau chapitre de la série Leadership In Test. Cette semaine, nous nous penchons sur le test de service pour les applications web. Nous aborderons :
- Qu’est-ce que le test de service ?
- Qu’est-ce que le test de performance ?
- Tests de fiabilité/basculement
- Tests de gestion du service
Commençons.
Qu’est-ce que le test de service ?
La qualité de service qu’une application web fournit pourrait être définie comme l’ensemble de ses caractéristiques, telles que la fonctionnalité, la performance, la fiabilité, l’utilisabilité, la sécurité, etc.
Toutefois, dans notre contexte, nous allons nous concentrer sur trois objectifs spécifiques qui relèvent du domaine que nous appelons le « test de service ». Ces objectifs sont :
- Performance : le service doit être réactif auprès des utilisateurs tout en supportant les charges qui lui sont imposées.
- Fiabilité : s’il a été conçu pour être résilient face aux défaillances, le service doit être fiable et/ou continuer à fonctionner même en cas de panne.
- Gestion : le service doit pouvoir être administré, configuré ou modifié sans qu’une dégradation du service ne soit perceptible pour les utilisateurs finaux. La gestion, ou le « test des opérations », vise à démontrer que les procédures d’administration, de gestion, de sauvegarde et de restauration du système fonctionnent efficacement.
Dans les trois cas, il est nécessaire de simuler une charge utilisateur afin d’effectuer les tests de façon efficace. Les objectifs de performance, de fiabilité et de gestion s’inscrivent dans le contexte d’utilisateurs réels exploitant le site pour leurs activités.
La réactivité (dans ce cas, le temps nécessaire pour qu’un élément du système réponde à la demande d’un autre) d’un site est directement liée aux ressources disponibles au sein de l’architecture technique.
À mesure que de plus en plus de clients utilisent le service, il reste moins de ressources techniques disponibles pour répondre à chaque demande utilisateur et les temps de réponse se détériorent.
Évidemment, un service soumis à une faible charge a moins de risques de dysfonctionnement. Une grande partie de la complexité logicielle et matérielle vise à répondre à la demande de ressources dans l’architecture technique lorsque le site est fortement sollicité.
Lorsqu’un site est en charge (ou surcharge), les demandes concurrentes de ressources doivent être gérées par divers composants d’infrastructure, tels que les systèmes d’exploitation serveurs ou réseaux, les systèmes de gestion de bases de données, les produits de serveurs web, les brokers de demandes d’objets, les middlewares, etc.
Ces composants d’infrastructure sont généralement plus fiables que le code applicatif conçu sur mesure qui sollicite ces ressources, mais des pannes peuvent survenir d’un côté comme de l’autre :
- Les composants d’infrastructure peuvent tomber en panne parce que le code applicatif (en raison d’une conception ou d’une implémentation de mauvaise qualité) impose une demande excessive sur les ressources.
- Les composants applicatifs peuvent échouer car les ressources dont ils dépendent ne sont pas toujours disponibles (à temps).
En simulant des charges de production typiques ou inhabituelles sur une période prolongée, les testeurs peuvent mettre en lumière des failles de conception ou d’implémentation du système. Une fois corrigées, les mêmes tests permettront de démontrer la résilience du système. Les QAs peuvent utiliser des outils de test de charge pour exécuter de nombreux processus définis ci-dessous.
Sur tous les services, on retrouve généralement un certain nombre de processus de gestion critiques qui doivent être menés pour assurer la continuité du service. Il peut être possible d’arrêter un service pour effectuer une maintenance de routine en dehors des heures ouvrées, mais la plupart des services en ligne fonctionnent 24 heures sur 24.
La journée de travail du service ne connaît jamais de fin. Ainsi, certaines procédures de gestion doivent inévitablement être réalisées alors que le service est actif et que des utilisateurs sont connectés. Ces procédures doivent être testées lorsque le système est sous charge afin de s’assurer qu’elles n’entraînent pas de dégradation du service en ligne, autrement dit lors du test de performance.

Qu'est-ce que le test de performance ?
Le test de performance est une composante clé du test de service. Il s'agit d'une méthode visant à évaluer la façon dont un système se comporte en termes de réactivité et de stabilité sous une charge particulière. Voici un aperçu de son fonctionnement :
- Le test de performance consiste en une série de tests sous différentes charges, où le système atteint un état stable (charges et temps de réponse à des niveaux constants).
- Nous mesurons la charge et les temps de réponse pour chaque charge, simulée sur une période de 15 à 30 minutes, afin d'obtenir un nombre statistiquement significatif de mesures.
- Nous surveillons et enregistrons les indicateurs vitaux pour chaque charge simulée. Ce sont les différentes ressources de notre système, par exemple l'utilisation du processeur et de la mémoire, la bande passante réseau, les taux d'E/S, etc.
Nous traçons un graphique de ces différentes charges par rapport aux temps de réponse rencontrés par nos « utilisateurs virtuels ». Une fois tracé, notre graphique ressemble à la figure ci-dessous.
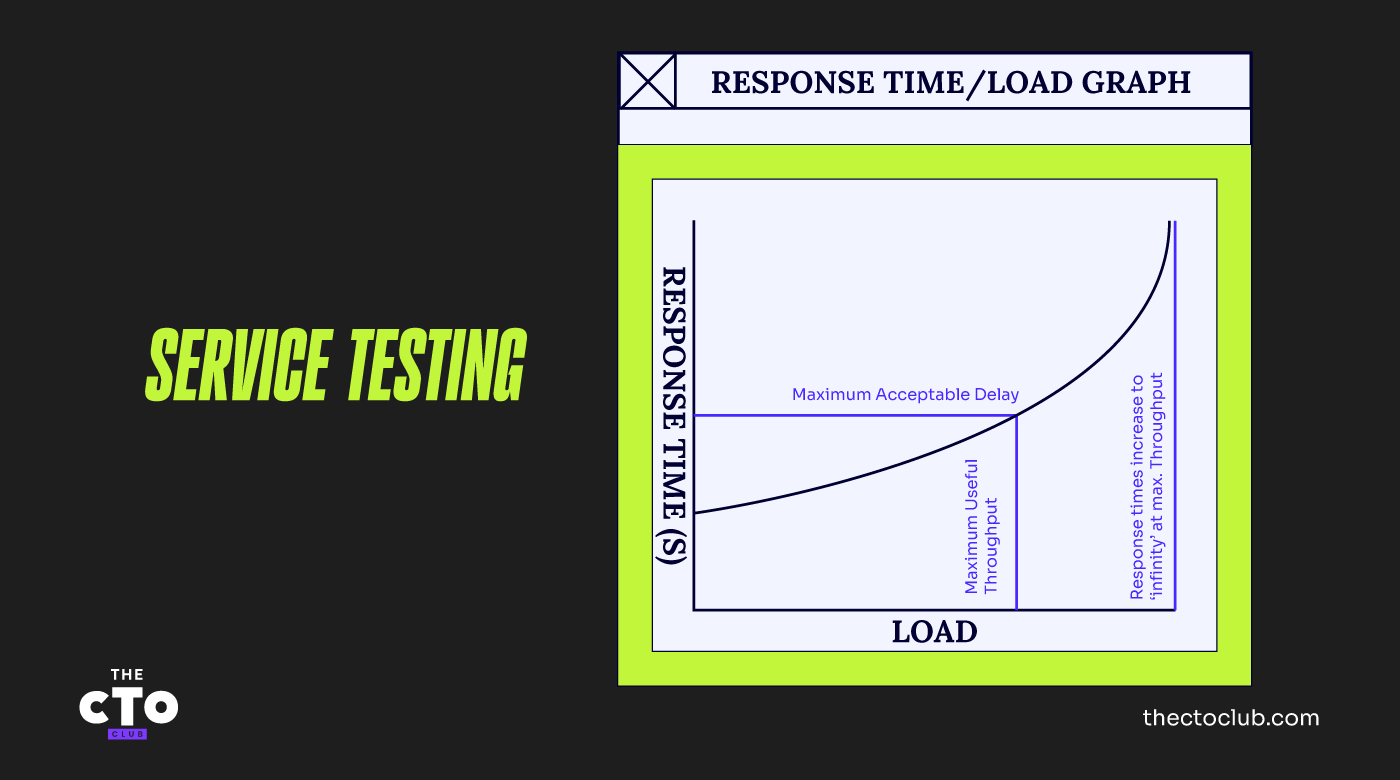
À charge nulle, lorsqu'il n'y a qu'un seul utilisateur sur le système, il dispose de l'ensemble des ressources et les temps de réponse sont rapides. Lorsque nous augmentons les charges et mesurons les temps de réponse, ceux-ci se détériorent progressivement jusqu'à atteindre un point où le système fonctionne à pleine capacité.
À ce stade, le temps de réponse de nos transactions de test est théoriquement infini, car l'une des ressources clés du système est totalement épuisée et aucune transaction supplémentaire ne peut être traitée.
En augmentant progressivement les charges de zéro jusqu'au maximum, nous surveillons également l'utilisation de différents types de ressources, par exemple l'utilisation du processeur serveur, l'utilisation de la mémoire, la bande passante réseau, les verrous de base de données, etc.
À la charge maximale, l'une de ces ressources est utilisée à 100 %. Cette ressource est la ressource limitante car elle s'épuise en premier. Bien entendu, à ce stade, les temps de réponse se sont tellement dégradés qu'ils sont probablement beaucoup plus lents que ce qui serait acceptable.
Le graphique ci-dessous montre l'utilisation/la disponibilité de plusieurs ressources tracée en fonction de la charge.

Pour augmenter la capacité de traitement et/ou réduire les temps de réponse d'un système, nous devons faire l'une des choses suivantes :
- Réduire la demande pour la ressource, typiquement en rendant le logiciel qui utilise la ressource plus efficace (c'est généralement la responsabilité du développement).
- Optimiser l'utilisation de la ressource matérielle au sein de l'architecture technique, par exemple en configurant le SGBD pour mettre plus de données en cache mémoire ou en priorisant certains processus sur le serveur applicatif.
- Rendre plus de ressources disponibles. Habituellement en ajoutant des processeurs, de la mémoire ou de la bande passante réseau, etc.
Comme vous commencez sans doute à le comprendre, le test de performance nécessite une équipe pour accompagner les testeurs. Il s'agit des architectes techniques, administrateurs de serveurs, administrateurs réseau, développeurs, et concepteurs/administrateurs de bases de données. Ces experts techniques sont qualifiés pour analyser les statistiques produites par les outils de surveillance des ressources et juger de la meilleure façon d'ajuster l'application, ou d'optimiser ou de mettre à niveau le système.
Si vous êtes testeur, sauf si vous avez une expertise particulière dans ces domaines, ne cédez pas à la tentation de croire que vous pouvez interpréter ces statistiques et prendre des décisions d'optimisation ou d'amélioration. Vous devrez impliquer ces experts dès le début du projet pour obtenir leurs conseils et leur adhésion, puis plus tard, pendant les tests, pour garantir que les goulets d'étranglement sont identifiés et résolus.
Rendez-vous dans le prochain article pour un examen approfondi de la gestion des tests de performance.
Test de fiabilité/de basculement
Garantir la disponibilité continue d’un service est sans doute un objectif clé de votre projet. Les tests de fiabilité aident à mettre en évidence des défauts subtils provoquant des pannes inattendues. Les tests de basculement permettent de s'assurer que les mesures de basculement prévues pour les pannes anticipées fonctionnent réellement.
Test de basculement
Lorsque des sites doivent être résilients et/ou fiables, ils sont généralement conçus avec des composants systèmes fiables, disposant de redondances intégrées et de fonctionnalités de basculement qui interviennent en cas de panne.
Ces fonctionnalités peuvent inclure des routages réseau multiples, plusieurs serveurs configurés en clusters, des technologies de services distribués et de middleware qui gèrent la répartition de charge et la réorientation du trafic lors de scénarios de défaillance.
Le test de basculement vise à explorer le comportement du système sous différents scénarios de panne sélectionnés avant la mise en production et implique normalement les éléments suivants :
- Identification des composants qui pourraient échouer et entraîner une perte de service (en examinant les défaillances de l'intérieur vers l'extérieur).
- Identification des dangers pouvant provoquer une défaillance et une perte de service (en examinant les menaces de l'extérieur vers l'intérieur).
- Une analyse des modes de défaillance ou scénarios pouvant se produire, pour lesquels vous devez avoir confiance dans l'efficacité de la mesure de récupération.
- Un test automatisé pouvant être utilisé pour charger le système et explorer le comportement du système sur une longue période.
- Le même test automatisé peut également être utilisé pour charger le système testé et surveiller son comportement en conditions de défaillance.
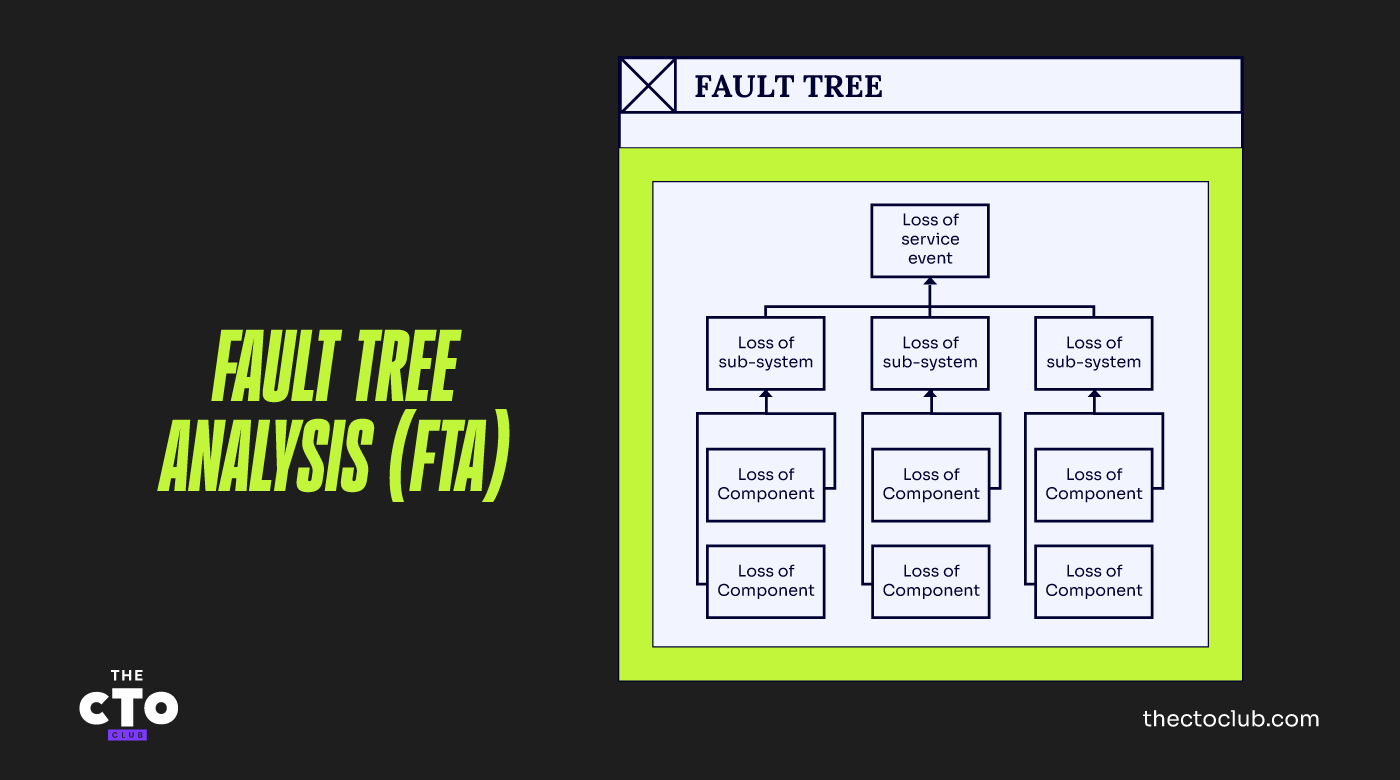
Une technique appelée analyse des arbres de défaillance (FTA) peut vous aider à comprendre les dépendances du service sur ses composants sous-jacents. L'analyse des arbres de défaillance et les diagrammes correspondants sont une représentation logique d'un système ou d'un service et des différentes manières dont il peut échouer.
Le schéma simple ci-dessous montre la relation entre les événements de défaillance des composants de base, les événements de défaillance intermédiaires au niveau des sous-systèmes, et l'événement de défaillance général du service. Il est bien sûr possible d’identifier plus de trois niveaux d’événements de défaillance.
Ces tests doivent être exécutés avec une charge automatisée afin d'explorer le comportement du système dans des situations de production et d’acquérir une confiance dans les mesures de récupération intégrées. En particulier, il faut savoir :
- Comment l'architecture se comporte-t-elle en situation de défaillance ?
- Les mécanismes d'équilibrage de charge fonctionnent-ils correctement ?
- Les capacités de basculement absorbent-elles la charge lorsqu’un composant tombe en panne ?
- La récupération automatique fonctionne-t-elle ? Les systèmes redémarrés "rattrapent-ils" ?
Ultimement, les tests visent à déterminer si le service pour les utilisateurs finaux est maintenu et si les utilisateurs remarquent réellement que la défaillance se produit.
Test de fiabilité (ou test d’endurance)
Le test de fiabilité vise à vérifier que les défaillances ne se produisent pas lorsque le système est sous charge.
La plupart des composants matériels sont suffisamment fiables pour que leur durée moyenne entre pannes puisse se mesurer en années. Les tests de fiabilité exigent l’utilisation (ou la réutilisation) de tests automatisés de deux manières afin de simuler :
- Des charges extrêmes sur des composants ou ressources spécifiques de l'architecture technique.
- Des périodes prolongées de charges normales (ou extrêmes) sur l’ensemble du système.
En se concentrant sur des composants spécifiques, l'objectif est de les solliciter en les soumettant à un nombre déraisonnablement élevé de requêtes pour exécuter leur fonction prévue. Il est souvent plus simple de soumettre d’abord les composants critiques à des tests de charge isolés avec de nombreuses requêtes simples, avant de réaliser un test beaucoup plus complexe sur toute l’infrastructure. Il existe aussi des outils de tests de résistance conçus spécialement pour faciliter le travail des QA.
Les tests d’endurance soumettent un système à une charge pendant une longue période (24, 48 heures ou plus) afin de repérer des problèmes (souvent) obscurs. Les défauts rares ne se manifestent parfois qu’après une utilisation prolongée.
Le test automatisé n’a pas forcément à générer une charge extrême (les tests de stress couvrent ce cas). Néanmoins, nous sommes particulièrement attentifs à la capacité du système à résister à l'exécution continue d'une large variété de transactions de test afin de détecter d’éventuelles fuites mémoire, des blocages ou des conditions de compétition.
Tests de gestion de service
Enfin, un mot sur les tests de gestion de service.
Lorsque le service est déployé en production, il doit être géré. Maintenir un service en fonctionnement nécessite de le surveiller, de l’améliorer, de le sauvegarder et de le réparer rapidement en cas de problème.
Les procédures qu’utilisent les gestionnaires de service pour réaliser des mises à niveau, des sauvegardes, des déploiements et des restaurations après panne sont essentielles pour garantir un service fiable et doivent donc être testées, en particulier si le service subira des évolutions rapides après son déploiement.
Les problèmes particuliers à traiter sont les suivants :
- Les procédures n’atteignent pas l’effet souhaité.
- Les procédures sont inapplicables ou inutilisables.
- Les procédures perturbent le service en production.
Les tests doivent, dans la mesure du possible, être réalisés de la façon la plus réaliste possible.
Quelques pistes de réflexion
Certains systèmes sont susceptibles de faire face à des charges extrêmes lorsqu’un événement particulier survient. Par exemple, une entreprise en ligne peut s’attendre à des pics de charge juste après la diffusion de ses offres à la télévision, ou un site d’actualité nationale peut être submergé lorsqu’une information majeure éclate.
Pensez à un système que vous connaissez bien et qui a été affecté par des incidents imprévus dans votre entreprise ou dans l’actualité nationale.
Quels incidents ou événements pourraient déclencher des charges excessives dans votre système ?
Pouvez-vous (ou pourriez-vous) recueillir des données à partir des journaux système qui indiquent le nombre de transactions exécutées ? Pouvez-vous extrapoler cet événement afin de prédire un événement critique se produisant une fois tous les 100 ans, ou une fois tous les 1000 ans ?
Quelles mesures pourriez-vous appliquer (ou avez-vous déjà appliquées) pour réduire la probabilité des pics, l’ampleur des pics ou les éliminer totalement ?
Inscrivez-vous à la newsletter The QA Lead pour être prévenu(e) lorsque de nouveaux volets de la série seront publiés. Ces articles sont des extraits du cours Leadership In Test de Paul, que nous recommandons vivement pour approfondir ce sujet et bien d’autres. Si vous vous inscrivez, utilisez notre code promo exclusif QALEADOFFER pour bénéficier de 60 $ de réduction sur le prix total du cours !
Lecture suggérée : 10 MEILLEURS OUTILS DE GESTION DES TESTS OPEN SOURCE

{kind=link}