Die 10 besten Key-Value-Datenbanken im Test 2026

Beste Key Value Datenbank Shortlist


Die beste Key Value Datenbank hilft Teams dabei, hohe Lese- und Schreibvolumina zu bewältigen, die Latenz zu reduzieren, Echtzeit-Workloads zu unterstützen und eine gleichbleibende Performance im großen Maßstab zu gewährleisten. Mit diesen Tools können Entwickler Daten schnell speichern und abrufen, sodass Anwendungen auch bei unregelmäßiger Last oder schnellem Wachstum schnell reagieren können.
Teams suchen oft nach einer Key Value Datenbank, wenn relationale Systeme unter hohem Verkehr langsamer werden, Caching-Schichten unzuverlässig sind oder Fehlkonfigurationen zu inkonsistentem Abfrageverhalten führen. Probleme wie ungleichmäßige Datenverteilung, langsames Failover und manuelles Sharding können zu Ausfällen, höheren Betriebskosten und Verzögerungen bei Entwicklungs- und Betriebsteams führen.
Mit über 20 Jahren Branchenerfahrung als Chief Technology Officer habe ich Dutzende Key Value Datenbanken in echten Umgebungen getestet und bewertet, um Leistung, Integration und betriebliche Zuverlässigkeit einzuschätzen. Dieser Leitfaden stellt die führenden Key Value Datenbanken vor, die Teams dabei unterstützen, stabile, datengetriebene Anwendungen bereitzustellen. Jede Bewertung behandelt Funktionen, Vor- und Nachteile sowie ideale Anwendungsfälle, damit Sie das passende Tool auswählen können.
Warum Sie unseren Software-Bewertungen vertrauen können
Wir testen und bewerten Software für SaaS-Entwicklung seit 2023. Als Technologieexperten wissen wir, wie kritisch und schwierig die Auswahl der richtigen Softwarelösung ist. Wir investieren viel in gründliche Recherchen, um unserer Zielgruppe bessere Kaufentscheidungen bei Software zu ermöglichen.
Wir haben mehr als 2.000 Tools für verschiedene Anwendungsfälle der SaaS-Entwicklung getestet und über 1.000 umfassende Software-Bewertungen verfasst. Erfahren Sie wie wir Transparenz gewährleisten und sehen Sie sich unsere Software-Bewertungsmethodik an.
Key Value Datenbank Vergleich Zusammenfassung
Diese Vergleichstabelle fasst die Preisinformationen meiner Top Key Value Datenbank Auswahlen zusammen, damit Sie die beste Lösung für Ihr Budget und Ihre Geschäftsanforderungen finden.
| Tool | Best For | Trial Info | Price | ||
|---|---|---|---|---|---|
| 1 | Am besten für die Visualisierung von Datenbankdesigns | Nein | $7.95/Benutzer/Monat (jährliche Abrechnung) | Website | |
| 2 | Am besten geeignet für Graphdatenbank-Funktionalitäten | Nein | $35/user/Monat | Website | |
| 3 | Am besten für Multi-Cloud-Unterstützung | Nein | $31/user/month (jährliche Abrechnung) | Website | |
| 4 | Am besten für Apache-Cassandra-Nutzer | Nein | $30/user/month | Website | |
| 5 | Am besten geeignet für Hochgeschwindigkeits-Transaktionen | Nein | $10/Benutzer/Monat (jährliche Abrechnung) | Website | |
| 6 | Am besten für die Integration ins Oracle-Ökosystem geeignet | Nein | $25/user/month | Website | |
| 7 | Am besten geeignet für die Integration mit Azure-Diensten | Nein | $56.60/user/month | Website | |
| 8 | Am besten geeignet für Speichereffizienz | Nein | Preis auf Anfrage | Website | |
| 9 | Am besten geeignet für In-Memory-Datenspeicherung | Nein | $5/user/month | Website | |
| 10 | Am besten für geringe Latenzzeiten geeignet | Nein | $10/user/month | Website |

-

TestDevLab
Visit Website -
Site24x7
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.7 -
GitHub Actions
Visit WebsiteThis is an aggregated rating for this tool including ratings from Crozdesk users and ratings from other sites.4.8


Key Value Datenbank Bewertungen
Nachfolgend finden Sie meine ausführlichen Zusammenfassungen der besten Key Value Datenbanken aus meiner Shortlist. Meine Bewertungen bieten einen detaillierten Einblick in die wichtigsten Funktionen, Vor- und Nachteile, Integrationen und idealen Anwendungsfälle jedes Tools, um Ihnen bei der Auswahl des besten Tools zu helfen.
Lucid ist ein cloudbasiertes Diagramm-Tool, das speziell für Fachleute und Teams entwickelt wurde, die Datenbanken visualisieren und entwerfen müssen. Es vereinfacht den Prozess der Erstellung, gemeinsamen Nutzung und Zusammenarbeit an Datenbankentwürfen und ist damit ein wertvolles Werkzeug für Entwickler und Ingenieure.
Warum ich Lucid gewählt habe: Lucid überzeugt durch die Visualisierung von Datenbankdesigns und bietet intuitive Werkzeuge, um Ihre Datenbankarchitektur abzubilden. Die Drag-and-Drop-Oberfläche ermöglicht es Ihnen, auch komplexe Diagramme einfach zu erstellen. Die Plattform unterstützt die Zusammenarbeit in Echtzeit, sodass Ihr Team nahtlos zusammenarbeiten kann. Darüber hinaus helfen Vorlagen und Symbolbibliotheken dabei, schnell mit Ihren Projekten zu starten.
Herausragende Funktionen & Integrationen:
Funktionen beinhalten die Zusammenarbeit in Echtzeit für Teamprojekte, eine große Auswahl an Vorlagen, um den Einstieg in Ihre Entwürfe zu erleichtern, sowie eine intuitive Drag-and-Drop-Oberfläche, die das Erstellen von Diagrammen unkompliziert macht. Diese Funktionen unterstützen Ihr Team dabei, effizient und effektiv zu arbeiten.
Integrationen bieten Anbindungen an Google Drive, Microsoft Teams, Slack, Atlassian Confluence, Atlassian Jira, Microsoft Office, Dropbox, Salesforce, GitHub und AWS.
Pros and Cons
Pros:
- Unterstützt komplexe Datenbankstrukturen
- Umfangreiche Vorlagenbibliothek
- Intuitive Drag-and-Drop-Oberfläche
Cons:
- Erweiterte Funktionen erfordern Einarbeitung
- Kann für Einsteiger überwältigend sein
ArangoDB ist eine Multi-Model-NoSQL-Datenbank für Entwickler und Unternehmen, die flexible Datenspeicherlösungen benötigen. Sie ermöglicht es Benutzern, mit Graphen-, Dokumenten- und Schlüssel-Wert-Datenmodellen zu arbeiten und ist somit für verschiedene Anwendungen vielseitig einsetzbar.
Warum ich ArangoDB ausgewählt habe: ArangoDB überzeugt durch hervorragende Fähigkeiten im Bereich der Graphdatenbanken und bietet Werkzeuge zur Verwaltung komplexer Beziehungen zwischen Datenpunkten. Die leistungsstarke Abfragesprache AQL unterstützt effiziente Operationen über verschiedene Datenmodelle hinweg. Durch den nativen Multi-Model-Ansatz kann Ihr Team unterschiedliche Datentypen ohne mehrere Systeme verwalten. Darüber hinaus sorgt die Skalierbarkeit dafür, dass wachsende Datenanforderungen effektiv bewältigt werden können.
Hervorstechende Funktionen & Integrationen:
Funktionen umfassen eine integrierte Suchmaschine für schnelle Datenabfragen, Unterstützung für georäumliche Daten für ortsbezogene Anwendungen sowie eine webbasierte Benutzeroberfläche für das einfache Datenbankmanagement. Diese Funktionen verbessern Ihre Möglichkeiten, mit Ihren Daten effizient zu interagieren und sie zu verwalten.
Integrationen umfassen Kubernetes, Docker, Apache Kafka, Apache Spark, Prometheus, Grafana, Ansible, Terraform, Amazon Web Services und Microsoft Azure.
Pros and Cons
Pros:
- Geo-räumliche Datenunterstützung
- Skalierbar für große Datenmengen
- Unterstützt mehrere Datenmodelle
Cons:
- Komplexe Konfigurationsoptionen
- Erfordert technisches Fachwissen
Couchbase ist eine cloudbasierte NoSQL-Datenbanklösung für Entwickler und IT-Teams, die flexible und skalierbare Datenspeicherung benötigen. Sie ermöglicht es den Nutzern, Daten effizient über mehrere Cloud-Umgebungen hinweg zu verwalten.
Warum ich Couchbase gewählt habe: Couchbase bietet Multi-Cloud-Unterstützung, sodass Sie problemlos auf verschiedenen Cloud-Plattformen bereitstellen können. Diese Flexibilität wird durch Funktionen wie automatisches Sharding und Echtzeit-Analysen erweitert. Die Architektur der Plattform unterstützt mehrere Datenmodelle und bietet Vielseitigkeit bei der Handhabung verschiedenster Datentypen. Zusätzlich sorgen integrierte Sicherheitsfunktionen dafür, dass Ihre Daten in allen Umgebungen geschützt bleiben.
Herausragende Funktionen & Integrationen:
Funktionen umfassen automatisches Failover zur Sicherstellung der Datenverfügbarkeit, erweiterte Abfragefunktionen mit SQL-ähnlicher Syntax und integrierte Volltextsuche für verbessertes Datenretrieval.
Integrationen umfassen Google Cloud, AWS, Azure, Kubernetes, Docker, HashiCorp Vault, Terraform, Ansible, Prometheus und Grafana.
Pros and Cons
Pros:
- Multi-Cloud-Bereitstellungsoptionen
- Starke Datenkonsistenz
- Flexibles Datenmodell
Cons:
- Kostspielig für groß angelegte Projekte
- Hoher Ressourcenverbrauch
DataStax ist eine cloudbasierte Datenbanklösung, die speziell für Entwickler und Unternehmen entwickelt wurde, die eine skalierbare Datenverwaltung benötigen. Sie zeichnet sich durch die Verarbeitung großer Datenmengen und verteilter Systeme aus und ist daher ideal für Anwender von Apache Cassandra.
Warum ich DataStax ausgewählt habe: DataStax bietet umfassende Unterstützung für Apache-Cassandra-Nutzer und schafft eine vertraute Umgebung für diejenigen, die bereits mit dieser Technologie arbeiten. Zu den Funktionen gehören automatisches Skalieren und integrierte Analysen, die auf großvolumige Datenanforderungen abgestimmt sind. Die Architektur der Datenbank gewährleistet hohe Verfügbarkeit und Fehlertoleranz – entscheidend für Unternehmensanwendungen. Zusätzlich unterstützt die benutzerfreundliche Oberfläche Ihr Team dabei, komplexe Datenoperationen effizient zu verwalten.
Herausragende Funktionen & Integrationen:
Funktionen umfassen erweiterte Sicherheit mit End-to-End-Verschlüsselung, nahtlose Datenreplikation über Regionen hinweg sowie eine benutzerfreundliche Abfragesprache für einfachere Datenverarbeitung.
Integrationen umfassen Apache Kafka, Apache Spark, Kubernetes, AWS, Azure, Google Cloud, Grafana, Prometheus, Terraform und DataStax Studio.
Pros and Cons
Pros:
- Benutzerfreundliche Oberfläche
- Unterstützung für Echtzeitanalysen
- Automatisches Datenskalieren
Cons:
- Erfordert technisches Fachwissen
- Begrenzte Offline-Unterstützung
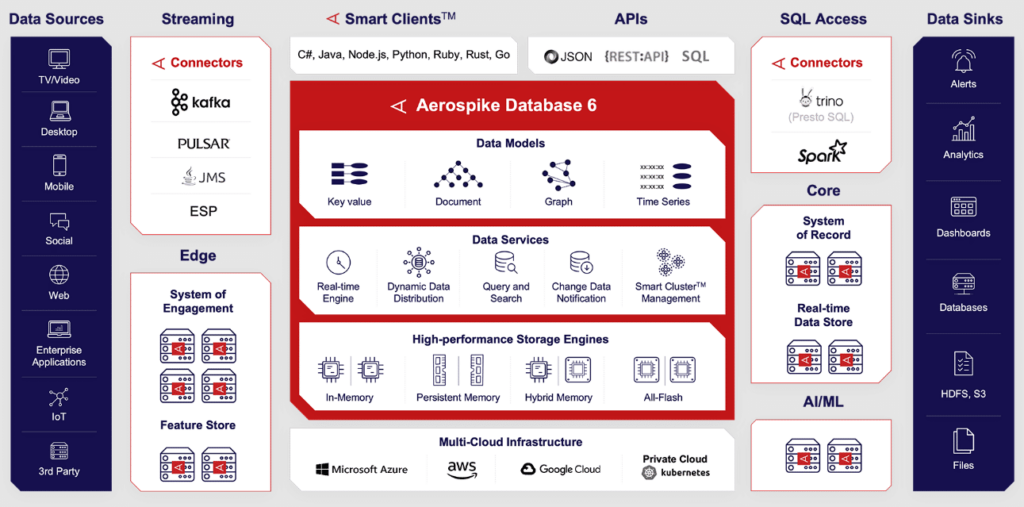
Aerospike ist eine leistungsstarke NoSQL-Datenbank für Unternehmen und Entwickler, die sich auf die Verarbeitung von Echtzeitdaten konzentrieren. Sie richtet sich an Unternehmen, die schnelle und zuverlässige Daten-Transaktionen für Anwendungen wie Betrugserkennung und Empfehlungssysteme benötigen.
Warum ich Aerospike ausgewählt habe: Aerospike glänzt bei der Verarbeitung von Hochgeschwindigkeits-Transaktionen und sorgt dafür, dass Ihre Datenoperationen schnell und effizient ablaufen. Die hybride Speicherarchitektur kombiniert Flash-Speicher mit In-Memory-Verarbeitung und sorgt so für eine geringe Latenz. Das starke Konsistenzmodell der Datenbank garantiert eine präzise Datenverarbeitung auch unter hoher Last. Darüber hinaus unterstützt die automatische Datenverteilung Ihr Team dabei, Daten mühelos über verschiedene Knoten hinweg zu verwalten.
Herausragende Funktionen & Integrationen:
Funktionen umfassen die Replikation über mehrere Rechenzentren hinweg für die globale Datenverteilung, ein flexibles Datenmodell zur Abbildung vielfältiger Anwendungsfälle und einen robusten Sicherheitsrahmen zum Schutz sensibler Informationen. Diese Funktionen verbessern Ihre Möglichkeiten, Daten effizient zu verwalten und abzusichern.
Integrationen beinhalten Apache Kafka, Apache Spark, Kubernetes, Docker, Amazon Web Services, Google Cloud Platform, Microsoft Azure, Prometheus, Grafana und HashiCorp Vault.
Pros and Cons
Pros:
- Automatische Datenverteilung
- Hybride Speicherarchitektur
- Hochgeschwindigkeits-Daten-Transaktionen
Cons:
- Komplexer Einrichtungsprozess
- Erfordert technisches Fachwissen
Am besten für die Integration ins Oracle-Ökosystem geeignet
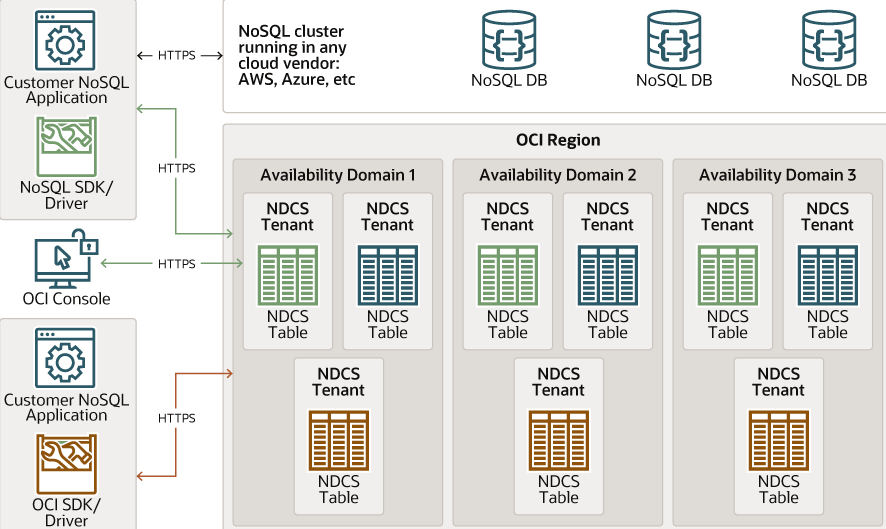
Oracle NoSQL Database Cloud ist eine skalierbare Datenbanklösung, die speziell für Unternehmen und Entwickler entwickelt wurde, die eine zuverlässige Datenverwaltung benötigen. Sie unterstützt verschiedene Datenmodelle und ist darauf ausgelegt, große Mengen an strukturierten und unstrukturierten Daten effizient zu verarbeiten.
Warum ich Oracle NoSQL Database Cloud ausgewählt habe: Oracle NoSQL Database Cloud lässt sich nahtlos in das Oracle-Ökosystem integrieren und bietet eine einheitliche Erfahrung für Nutzer, die bereits in Oracle-Produkte investiert haben. Sie bietet starke Konsistenz und flexible Datenmodelle, sodass Ihr Team mit unterschiedlichen Datentypen arbeiten kann. Die automatische Skalierung der Datenbank gewährleistet, dass Sie steigende Anforderungen ohne manuellen Eingriff bewältigen können. Darüber hinaus sorgen ihre Sicherheitsfunktionen dafür, dass Ihre Daten geschützt und konform mit Branchenstandards bleiben.
Herausragende Funktionen & Integrationen:
Funktionen umfassen automatische Datenpartitionierung für effiziente Speicherverwaltung, Echtzeit-Analysen für sofortige Einblicke und fortschrittliche Sicherheitsprotokolle, um Ihre Daten zu schützen. Diese Funktionen sorgen zusammen dafür, dass Ihre Abläufe sowohl effizient als auch sicher sind.
Integrationen umfassen Oracle Cloud Infrastructure, Oracle Data Integrator, Oracle GoldenGate, Oracle Analytics Cloud, Oracle Autonomous Database, Apache Hadoop, Apache Kafka, Kubernetes, Docker und Terraform.
Pros and Cons
Pros:
- Fortschrittliche Sicherheitsfunktionen
- Automatische Skalierungsfunktionen
- Starke Datenkonsistenz
Cons:
- Kenntnisse des Oracle-Ökosystems erforderlich
- Begrenzter Support außerhalb von Oracle
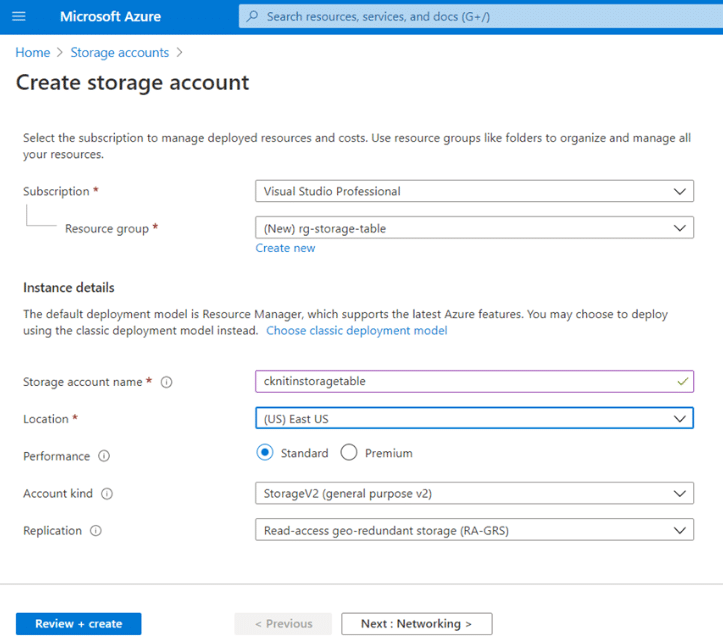
Azure Table Storage ist ein cloudbasierter Key-Value-Datenbankdienst für Entwickler und Unternehmen, die skalierbaren und flexiblen Datenspeicher benötigen. Er eignet sich ideal zum Speichern großer Mengen strukturierter, nicht-relationaler Daten und lässt sich nahtlos mit anderen Azure-Diensten integrieren.
Warum ich Azure Table Storage gewählt habe: Azure Table Storage ist perfekt für Teams, die bereits Azure-Dienste nutzen, und stellt eine praktische Wahl für alle dar, die sich im Microsoft-Ökosystem bewegen. Es bietet hohe Verfügbarkeit und Ausfallsicherheit, sodass Ihre Daten immer zugänglich sind. Das nutzungsbasierte Preismodell hilft Ihnen, die Kosten effektiv zu steuern, wenn Ihr Datenbedarf wächst. Außerdem ermöglicht die Skalierbarkeit die Verarbeitung riesiger Datenmengen ohne Performance-Probleme.
Hervorstechende Funktionen & Integrationen:
Funktionen umfassen automatische Lastverteilung zur Verwaltung des Datenverkehrs, georedundante Speicherung zum Schutz Ihrer Daten und ein flexibles Schema-Design, das sich an verändernde Datenanforderungen anpasst. Diese Funktionen sorgen dafür, dass Ihre Daten sicher und jederzeit verfügbar bleiben.
Integrationen umfassen Azure Functions, Azure Logic Apps, Azure Stream Analytics, Azure Data Factory, Azure Machine Learning, Azure Synapse Analytics, Azure DevOps, Power BI, Microsoft Power Apps und Microsoft Flow.
Pros and Cons
Pros:
- Nutzungsbasierte Preisgestaltung
- Flexibles Schema-Design
- Einfache Integration in das Azure-Ökosystem
Cons:
- Einfache Indizierungsoptionen
- Erfordert Azure-Kenntnisse
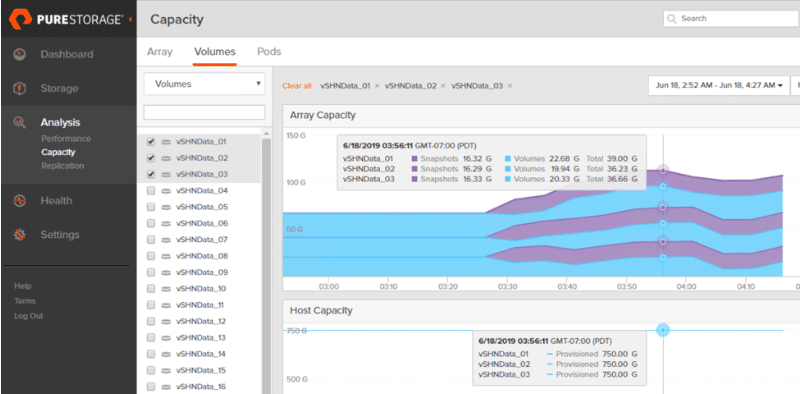
Pure Storage ist eine Datenspeicherlösung, die sich an Unternehmen und IT-Profis richtet, die effiziente und leistungsstarke Speicherkapazitäten suchen. Der Fokus liegt auf schnellem Datenzugriff und der Reduzierung von Speicherkosten durch innovative Technologie.
Warum ich Pure Storage gewählt habe: Pure Storage ist auf Speichereffizienz ausgelegt und bietet schnellen Zugriff und optimierte Speichernutzung. Die All-Flash-Architektur sorgt für rasche Datenbereitstellung, was für leistungsintensive Anwendungen entscheidend ist. Die Funktionen zur Datenreduzierung helfen Ihrem Team, Speicherkosten einzusparen, ohne Abstriche bei der Leistung machen zu müssen. Zudem sorgen unterbrechungsfreie Upgrades dafür, dass Ihre Systeme ohne Ausfallzeiten reibungslos weiterlaufen.
Hervorstechende Funktionen & Integrationen:
Funktionen umfassen eine permanente Datenkomprimierung zur Maximierung der Speicherkapazität, Verschlüsselung ruhender Daten für erhöhte Sicherheit und unterbrechungsfreie Upgrades zur Sicherstellung der Systemverfügbarkeit. Diese Features sorgen dafür, dass Ihre Daten sicher, zugänglich und kosteneffizient bleiben.
Integrationen sind unter anderem VMware, Microsoft SQL Server, Oracle Database, SAP, Docker, Kubernetes, OpenStack, Ansible, Splunk und Veeam.
Pros and Cons
Pros:
- Unterbrechungsfreie Upgrades
- Effiziente Speichernutzung
- Schneller Datenzugriff
Cons:
- Erfordert spezielles Fachwissen
- Hohe Anfangsinvestition
Redis Enterprise ist eine In-Memory-Schlüssel-Wert-Datenbank für Entwickler und Unternehmen, die schnellen Datenzugriff und schnelle Datenverarbeitung benötigen. Sie zeichnet sich durch höchste Leistung und niedrige Latenz aus und ist damit ideal für Echtzeitanwendungen.
Warum ich Redis Enterprise ausgewählt habe: Redis Enterprise ist bekannt für seine leistungsfähige In-Memory-Datenspeicherung, die einen schnellen Datenzugriff und eine schnelle Datenverarbeitung ermöglicht. Es unterstützt verschiedene Datenstrukturen, was seine Flexibilität für vielfältige Anwendungen erhöht. Die Datenbank bietet Funktionen wie automatische Übernahme bei Ausfällen und Datenpersistenz, um sicherzustellen, dass Ihre Daten zugänglich und sicher bleiben. Dank der Skalierbarkeit können Sie steigende Arbeitslasten bewältigen, ohne die Performance einzubüßen.
Herausragende Funktionen & Integrationen:
Funktionen umfassen Multi-Model-Unterstützung für unterschiedliche Datentypen, integrierte Replikation zur Datensicherheit sowie fortschrittliche Speicheroptimierungstechniken. Diese Funktionen sorgen dafür, dass Ihre Datenoperationen reibungslos und effizient ablaufen.
Integrationen umfassen Apache Kafka, Apache Spark, Kubernetes, Docker, Amazon Web Services, Microsoft Azure, Google Cloud Platform, Grafana, Prometheus und HashiCorp Vault.
Pros and Cons
Pros:
- Unterstützt mehrere Datenstrukturen
- Schneller Datenzugriff
- Niedrige Latenzzeiten
Cons:
- Begrenzte Optionen für Festplattenspeicherung
- Erfordert Speicherverwaltung

ScyllaDB ist eine Hochleistungs-NoSQL-Datenbank, die speziell für Entwickler und Unternehmen entwickelt wurde, die schnellen Datenzugriff und zügige Datenverarbeitung benötigen. Sie ist darauf ausgelegt, große Datenmengen mit niedriger Latenz zu verarbeiten und eignet sich ideal für Echtzeitanwendungen.
Warum ich ScyllaDB gewählt habe: ScyllaDB bietet geringe Latenzzeiten, was für Anwendungen mit hohen Anforderungen an schnelle Datenabfragen entscheidend ist. Die Architektur setzt auf einen Shared-Nothing-Ansatz, um die Ressourcenauslastung zu optimieren. Dank automatischer Sharding-Funktionalität kann Ihr Team große Datenmengen ohne manuelle Konfiguration bewältigen. Darüber hinaus gewährleistet die Kompatibilität mit Apache Cassandra einen reibungslosen Umstieg für Nutzer, die bereits mit diesem System vertraut sind.
Herausragende Funktionen & Integrationen:
Funktionen umfassen die Echtzeitdatenreplikation zur Sicherung von Konsistenz, integrierte Monitoring-Tools zur Überwachung der Leistung und eine benutzerfreundliche Oberfläche, die das Datenbankmanagement vereinfacht. Diese Funktionen stellen sicher, dass Ihre Datenprozesse effizient und wirkungsvoll sind.
Integrationen umfassen Apache Kafka, Apache Spark, Prometheus, Grafana, Kubernetes, Docker, Ansible, Terraform, Amazon Web Services und Google Cloud Platform.
Pros and Cons
Pros:
- Kompatibel mit Apache Cassandra
- Automatische Datenaufteilung (Sharding)
- Niedrig-latenzdatenverarbeitung
Cons:
- Höherer Ressourcenverbrauch
- Komplexe Ersteinrichtung
Weitere Key Value Datenbanken
Hier sind weitere Key Value Datenbanken, die es nicht auf meine Shortlist geschafft haben, aber trotzdem einen Blick wert sind:
- Memcached
Am besten geeignet zum Zwischenspeichern häufig abgerufener Daten
- BoltDB
Am besten für eingebettete Datenbanklösungen
- Azure Redis Cache
Am besten für die Integration in das Azure-Ökosystem geeignet


{kind=link}
Auswahlkriterien für Key Value Datenbanken
Bei der Auswahl der besten Key Value Datenbanken für diese Liste habe ich übliche Anforderungen und Problemstellungen wie Skalierbarkeit und Datenkonsistenz berücksichtigt. Außerdem habe ich das folgende Rahmenwerk verwendet, um meine Bewertung strukturiert und fair zu gestalten:
Kernfunktionalität (25 % der Gesamtbewertung)
Um in diese Liste aufgenommen zu werden, musste jede Lösung diese Standardanwendungsfälle erfüllen:
- Speicherung von Key Value Paaren
- Unterstützung von Hochgeschwindigkeits-Datenabrufen
- Verarbeiten großer Datenmengen
- Bereitstellung von Datenkonsistenz
- Einfache Datenreplikation ermöglichen
Weitere herausragende Funktionen (25 % der Gesamtbewertung)
Zur weiteren Eingrenzung habe ich auch auf besondere Merkmale geachtet, wie:
- Unterstützung mehrerer Datenmodelle
- Integration von Echtzeit-Analysen
- Eingebaute Datenverschlüsselung
- Automatisches Data-Sharding
- Erweiterte Abfragefunktionen
Benutzerfreundlichkeit (10 % der Gesamtbewertung)
Um einen Eindruck von der Benutzerfreundlichkeit jedes Systems zu erhalten, habe ich Folgendes berücksichtigt:
- Intuitives Oberflächendesign
- Einfache Navigation
- Minimale Lernkurve
- Verfügbarkeit von Benutzerhandbüchern
- Anpassbare Dashboard-Einstellungen
Onboarding (10 % der Gesamtbewertung)
Zur Bewertung der Onboarding-Erfahrung jeder Plattform habe ich Folgendes berücksichtigt:
- Verfügbarkeit von Schulungsvideos
- Interaktive Produkttouren
- Zugang zu Vorlagen und Anleitungen
- Unterstützung durch Chatbots oder Live-Chat
- Webinare für neue Nutzer
Kundensupport (10 % der Gesamtbewertung)
Um die Kundendienstleistungen jedes Softwareanbieters zu bewerten, habe ich Folgendes berücksichtigt:
- 24/7-Kundensupport
- Zugang zu einer Wissensdatenbank
- Reaktionsschnelles Support-Team
- Verfügbarkeit von Live-Chat oder Telefonsupport
- Unterstützung durch einen dedizierten Account-Manager
Preis-Leistungs-Verhältnis (10 % der Gesamtbewertung)
Zur Bewertung des Preis-Leistungs-Verhältnisses jeder Plattform habe ich Folgendes berücksichtigt:
- Konkurrenzfähige Preismodelle
- Transparente Preisstruktur
- Kosten im Verhältnis zu den angebotenen Funktionen
- Rabatte bei jährlichen Abonnements
- Verfügbarkeit von Test- oder Demoversionen
Kundenbewertungen (10 % der Gesamtbewertung)
Um einen Eindruck der allgemeinen Kundenzufriedenheit zu erhalten, habe ich beim Lesen von Kundenbewertungen Folgendes beachtet:
- Gesamtbewertung und Feedback
- Häufig gelobte Funktionen
- Gemeldete Probleme oder Beschwerden
- Empfehlungen von Nutzern
- Zufriedenheit mit dem Kundensupport
Wie wählt man eine Key-Value-Datenbank aus?
Man kann sich leicht in langen Feature-Listen und komplexen Preisstrukturen verlieren. Damit Sie fokussiert bleiben, während Sie Ihren individuellen Auswahlprozess für Software durchlaufen, finden Sie hier eine Checkliste mit Faktoren, die Sie im Blick behalten sollten:
| Faktor | Was ist zu beachten? |
| Skalierbarkeit | Wie gut bewältigt die Datenbank Wachstum? Achten Sie auf Möglichkeiten, die horizontal skaliert werden können, um zunehmende Datenmengen ohne Performanceverlust zu verarbeiten. |
| Integrationen | Lässt sie sich mit Ihren existierenden Tools verbinden? Prüfen Sie, ob native Integrationen mit Ihrem aktuellen Software-Stack zur Verfügung stehen, um einen reibungslosen Datenfluss zwischen den Plattformen zu gewährleisten. |
| Anpassbarkeit | Können Sie das System an Ihre Bedürfnisse anpassen? Stellen Sie sicher, dass die Datenbank die Anpassung von Datenstrukturen und Workflows zulässt, damit sie zu Ihren individuellen Geschäftsprozessen passt. |
| Benutzerfreundlichkeit | Ist sie einfach für Ihr Team zu bedienen? Eine übersichtliche Oberfläche und intuitive Navigation verringern die Einarbeitungszeit und fördern die Akzeptanz. |
| Implementierung und Onboarding | Wie lange dauert die Einrichtung? Berücksichtigen Sie Zeit- und Ressourcenaufwand sowie, ob der Anbieter Unterstützung oder Tools für ein einfaches Onboarding bereitstellt. |
| Kosten | Liegt sie in Ihrem Budget? Vergleichen Sie Preismodelle, inklusive Preisstufen und versteckten Gebühren, um sicherzustellen, dass es zu Ihren finanziellen Rahmenbedingungen passt. |
| Sicherheitsmaßnahmen | Werden Ihre Anforderungen an den Datenschutz erfüllt? Achten Sie auf Funktionen wie Verschlüsselung, Zugangskontrollen und die Einhaltung von Branchenstandards, um Ihre Daten zu sichern. |
| Verfügbarkeit von Support | Erhalten Sie bei Bedarf Unterstützung? Prüfen Sie, ob der Anbieter 24/7-Support, Live-Chat oder einen festen Ansprechpartner bietet, der Ihr Team unterstützt. |
Was ist eine Key-Value-Datenbank?
Eine Key-Value-Datenbank ist eine Art von NoSQL-Datenbank, die Daten als Sammlung von Schlüssel-Wert-Paaren speichert. IT-Fachleute, Entwickler und Dateningenieure nutzen diese Tools typischerweise, um große Datenmengen effizient und schnell zu verwalten.
Merkmale wie horizontale Skalierbarkeit, flexible Datenmodelle und schnelle Datenabfragen helfen dabei, unterschiedlichste Datenanforderungen zu bewältigen und die Anwendungsleistung zu optimieren. Insgesamt bieten diese Tools eine einfache und effektive Möglichkeit, Daten in Echtzeit zu speichern und abzurufen.
Funktionen von Key Value-Datenbanken
Wenn Sie eine Key Value-Datenbank auswählen, achten Sie auf die folgenden wichtigen Funktionen:
- Horizontale Skalierbarkeit: Ermöglicht das Wachstum der Datenbank durch das Hinzufügen weiterer Server, sodass sie erhöhte Datenmengen bewältigen kann, ohne dass die Leistung abnimmt.
- Flexible Datenmodelle: Unterstützt verschiedene Datentypen und -strukturen, wodurch individuelle Anpassungen für spezifische Anwendungsanforderungen möglich sind.
- Schnelle Datenabfrage: Bietet schnellen Zugriff auf Daten, was für Echtzeitanwendungen und leistungsintensive Aufgaben essenziell ist.
- Automatische Datenaufteilung (Sharding): Verteilt Daten automatisch auf mehrere Knoten, optimiert die Ressourcennutzung und verbessert die Zugriffsgeschwindigkeit.
- Datenkonsistenz: Sichert eine korrekte Datenverarbeitung und -abfrage, sogar unter hoher Belastung, und garantiert so Zuverlässigkeit in allen Anwendungen.
- Echtzeit-Analyseintegration: Ermöglicht nahtlose Verbindung mit Analyse-Tools, um sofortige Einblicke in gespeicherte Daten zu erhalten.
- Integrierte Datenverschlüsselung: Schützt sensible Daten durch Verschlüsselung und sorgt für die Einhaltung von Sicherheitsstandards und gesetzlichen Vorgaben.
- Replikation über mehrere Rechenzentren: Ermöglicht die Verteilung von Daten über verschiedene Standorte hinweg – für Redundanz und globale Zugänglichkeit.
- Benutzerfreundliche Oberfläche: Vereinfacht das Datenbankmanagement mit einer intuitiven Bedienung und verkürzt die Einarbeitungszeit für neue Nutzer.
- Rund-um-die-Uhr-Kundensupport: Bietet kontinuierliche Unterstützung, um Probleme schnell zu lösen und Unterbrechungen des Betriebs auf ein Minimum zu reduzieren.
Vorteile von Key Value-Datenbanken
Die Implementierung einer Key Value-Datenbank bietet zahlreiche Vorteile für Ihr Team und Ihr Unternehmen. Hier sind einige positive Effekte, auf die Sie sich freuen können:
- Verbesserte Leistung: Schneller Datenzugriff und effiziente Datenverarbeitung führen zu kürzeren Antwortzeiten der Anwendungen und besseren Nutzererlebnissen.
- Skalierbarkeit: Horizontale Erweiterbarkeit ermöglicht, dass Ihr System mit den wachsenden Datenanforderungen Schritt hält und dauerhaft leistungsfähig bleibt – ohne teure Umstrukturierungen.
- Flexibilität: Flexible Datenmodelle ermöglichen die individuelle Anpassung der Datenbank an spezielle Anwendungen und sich wandelnde Geschäftsanforderungen.
- Hohe Datenzuverlässigkeit: Konsistente Datenverarbeitung gewährleistet korrekten und verlässlichen Datenzugriff – wesentlich für Vertrauen und Integrität im Geschäftsbetrieb.
- Kosteneffizienz: Automatische Datenaufteilung und effiziente Ressourcennutzung senken Betriebskosten, während die Leistung erhalten bleibt.
- Erhöhte Sicherheit: Eingebaute Datenverschlüsselung und Compliance-Funktionen schützen sensible Informationen und bewahren Ihr Unternehmen vor Datenpannen.
- Globale Zugänglichkeit: Replikation über verschiedene Rechenzentren hinweg stellt den weltweiten Datenzugriff sicher und unterstützt verteilte Teams sowie globale Geschäftsabläufe.
Kosten und Preisgestaltung von Key Value-Datenbanken
Bei der Auswahl einer Key Value-Datenbank ist es wichtig, die verschiedenen Preismodelle und Tarife zu kennen. Die Kosten variieren je nach Funktionen, Teamgröße, Zusatzoptionen und mehr. Die folgende Tabelle fasst die gängigen Tarife, deren Durchschnittspreise und typische Leistungsmerkmale von Key Value-Datenbanklösungen zusammen:
Tarifvergleichstabelle für Key Value-Datenbanken
| Tariftyp | Durchschnittlicher Preis | Typische Merkmale |
| Gratis-Tarif | $0 | Basisdatenspeicherung, eingeschränkter Support und Community-Zugang. |
| Persönlicher Tarif | $5-$25 /Benutzer /Monat | Erweiterte Speicherkapazität, grundlegende Analysen und E-Mail-Support. |
| Geschäfts-Tarif | $30-$100 /Benutzer /Monat | Erweiterte Analysen, priorisierte Unterstützung und Integrationsmöglichkeiten. |
| Enterprise-Tarif | $150-$500 /Benutzer /Monat | Individuell anpassbare Lösungen, dediziertes Account-Management und erweiterte Sicherheitsfunktionen. |
Key Value Datenbank FAQs
Hier finden Sie Antworten auf häufig gestellte Fragen zur Key-Value-Datenbank:
Was sind die Einschränkungen einer Key-Value-Datenbank?
Key-Value-Datenbanken unterstützen keine komplexen Abfragen, was ihre Verwendung in Anwendungen mit umfangreichen Datenoperationen einschränken kann. Typischerweise verwenden Sie einfache Befehle wie get, put und delete. Filter- und Sortiermöglichkeiten sind begrenzt. Berücksichtigen Sie dies, wenn Ihre Anwendung erweiterte Abfragen benötigt.
Wann sollte man keine Key-Value-Datenbank verwenden?
Vermeiden Sie den Einsatz von Key-Value-Datenbanken, wenn Ihre Anwendung komplexe Abfragen oder viele-zu-viele-Beziehungen verarbeiten muss. In solchen Fällen ist ein relationales Datenbankmanagementsystem (RDBMS) besser geeignet, da es die notwendigen Abfragefunktionen und den Umgang mit relationalen Daten bereitstellt.
Was sind die Nachteile des Key-Value-Stores?
Key-Value-Stores verfügen nicht über fortschrittliche Abfragefunktionen, wodurch sie weniger geeignet für komplexe Analyse- und Abfrage-Szenarien sind, die mehrere Joins und Beziehungen erfordern. Falls Ihre Anwendung detaillierte Datenanalysen benötigt, sollten Sie prüfen, ob diese Einschränkungen Ihre Abläufe beeinträchtigen könnten.
Wie geht eine Key-Value-Datenbank mit großen Datenmengen um?
Key-Value-Datenbanken verwalten große Datenmengen effizient mit minimaler Latenz. Sie sind besonders leistungsfähig in Szenarien, die schnelle Datenspeicherung und -abfrage erfordern und eignen sich für Anwendungen mit hohem Lese- und Schreibaufkommen. Stellen Sie jedoch sicher, dass die Skalierbarkeit der Datenbank zu Ihrem langfristigen Datenwachstum passt.
Können Key-Value-Datenbanken Echtzeit-Datenverarbeitung?
Ja, Key-Value-Datenbanken sind für die Echtzeit-Datenverarbeitung geeignet und ermöglichen einen schnellen Datenzugriff und schnelle Aktualisierungen. Diese Fähigkeit unterstützt Anwendungen wie Caching und Sitzungsverwaltung, bei denen sofortige Datenverfügbarkeit entscheidend ist. Überprüfen Sie die Echtzeitanforderungen Ihrer Anwendung, um sicherzustellen, dass eine Key-Value-Datenbank passt.
Sind Key-Value-Datenbanken für verteilte Systeme geeignet?
Key-Value-Datenbanken eignen sich sehr gut für verteilte Systeme und bieten Funktionen wie Datenreplikation über mehrere Knoten hinweg. Dies erhöht die Datenverfügbarkeit und Redundanz. Wenn Ihr System globalen Datenzugriff erfordert, wählen Sie eine Key-Value-Datenbank, die Replikation und Verteilung über mehrere Rechenzentren unterstützt.
Wie geht es weiter?
Steigern Sie das Wachstum Ihrer SaaS und Ihre Führungsqualitäten. Abonnieren Sie unseren Newsletter für die neuesten Einblicke von CTOs und angehenden Tech-Führungskräften. Wir unterstützen Sie dabei, intelligenter zu skalieren und stärker zu führen – mit Anleitungen, Ressourcen und Strategien von Top-Expert:innen!