Führung im Test: Servicetest

Redaktioneller Hinweis: Willkommen zur Leadership In Test-Serie vom Softwaretest-Guru & Berater Paul Gerrard. Die Serie soll Testern mit einigen Jahren Erfahrung – insbesondere jenen in agilen Teams – dabei helfen, in ihren Rollen als Testleiter und Manager zu glänzen.
Im vorherigen Artikel haben wir uns die sich wandelnde Rolle von Testern und Möglichkeiten zur besseren Zusammenarbeit mit Kollegen angesehen. In diesem Artikel steigen wir tiefer in die Praxis ein und beleuchten die Tests von Performance, Zuverlässigkeit und Wartbarkeit einer Webanwendung – auch bekannt als Servicetest.
Melde dich für den QA Lead-Newsletter an, um benachrichtigt zu werden, wenn neue Teile der Serie erscheinen. Diese Beiträge sind Auszüge aus Pauls Leadership In Test-Kurs, den wir wärmstens empfehlen, wenn Du tiefer in dieses und andere Themen einsteigen möchtest. Wenn Du dich einschreibst, nutze unseren exklusiven Gutscheincode QALEADOFFER, um $60 auf den regulären Kurspreis zu sparen!
Hallo und willkommen zu einem weiteren Kapitel der Leadership In Test-Serie. Diese Woche widmen wir uns dem Servicetest von Webanwendungen. Wir behandeln folgende Themen:
- Was ist Servicetest?
- Was ist Last- und Performancetest?
- Zuverlässigkeits- und Ausfallsicherheitstest
- Test des Service-Managements
Fangen wir an.
Was ist Servicetest?
Die Servicequalität, die eine Webanwendung bereitstellt, lässt sich als Summe vieler Merkmale definieren: Funktionalität, Performance, Zuverlässigkeit, Bedienbarkeit, Sicherheit und so weiter.
Für unsere Zwecke trennen wir jedoch drei spezifische Service-Ziele aus, die unter "Servicetest" betrachtet werden. Diese Ziele sind:
- Performance: Der Service muss für die Benutzer reaktionsschnell sein und gleichzeitig die auf ihn wirkenden Lasten bewältigen.
- Zuverlässigkeit: Falls auf Ausfallsicherheit ausgelegt, muss der Service zuverlässig sein und/oder auch bei einem Ausfall weiterhin Leistungen erbringen.
- Wartbarkeit: Der Service muss verwaltet, konfiguriert oder geändert werden können, ohne dass für Endnutzer eine spürbare Verschlechterung der Leistung auftritt. Wartbarkeit – oder auch Betriebstest – soll belegen, dass administrative, managementbezogene sowie Backup- und Wiederherstellungsmaßnahmen zuverlässig durchführbar sind.
In allen drei Fällen ist es notwendig, die Nutzerlast zu simulieren, um die Tests effektiv durchführen zu können. Performance-, Zuverlässigkeits- und Wartbarkeitsziele stehen im Kontext realer Kunden, die die Website für Geschäftszwecke nutzen.
Die Reaktionszeit (in diesem Fall die Zeit, die ein Systemknoten benötigt, um auf eine Anfrage eines anderen zu reagieren) einer Website hängt direkt von den verfügbaren Ressourcen innerhalb der technischen Architektur ab.
Je mehr Kunden den Service nutzen, desto weniger technische Ressourcen stehen für die Bearbeitung der einzelnen Anfragen zur Verfügung; die Antwortzeiten verschlechtern sich.
Natürlich schlägt ein nur gering ausgelasteter Service weniger schnell fehl. Viel der Software- und Hardware-Komplexität dient dazu, die Anforderungen an Ressourcen innerhalb der technischen Architektur bei starker Auslastung aufzufangen.
Wenn eine Website stark (oder übermäßig) ausgelastet ist, müssen die konkurrierenden Anforderungen an Ressourcen von verschiedenen Infrastrukturkomponenten wie Server- und Netzwerkbetriebssystemen, Datenbankmanagementsystemen, Webserver-Lösungen, Objektvermittlern, Middleware usw. gehandhabt werden.
Diese Infrastrukturkomponenten sind in der Regel zuverlässiger als der maßgeschneiderte Anwendungscode, der Ressourcen anfordert — aber Fehler können in beiden auftreten:
- Infrastrukturkomponenten fallen aus, wenn der Anwendungscode (aufgrund schlechter Konzeption oder Umsetzung) übermäßig viele Ressourcen fordert.
- Anwendungskomponenten können fehlschlagen, weil die benötigten Ressourcen nicht immer (rechtzeitig) verfügbar sind.
Durch die Simulation typischer und auch ungewöhnlicher Produktionslasten über einen längeren Zeitraum können Tester Schwächen in Design oder Umsetzung der Systeme aufdecken. Werden diese Schwächen behoben, zeigen die gleichen Tests, dass das System robust ist. QAs können Lasttest-Tools nutzen, um viele der unten beschriebenen Prozesse automatisiert durchzuführen.
Bei allen Services gibt es üblicherweise eine Reihe kritischer administrativer Prozesse, die für einen störungsfreien Betrieb regelmäßig ausgeführt werden müssen. Unter Umständen lässt sich ein Service für routinemäßige Wartungsarbeiten außerhalb der Geschäftszeiten herunterfahren, aber viele Online-Services laufen rund um die Uhr.
Der Arbeitstag des Services endet nie. Unvermeidlich ist es daher, administrative Prozesse auszuführen, während der Service in Betrieb ist und Nutzer online sind. Auch diese Prozeduren müssen unter Last getestet werden, um sicherzustellen, dass sie den Live-Betrieb nicht beeinträchtigen – also ein Fall für Performance-Tests.

Was sind Leistungstests?
Leistungstests sind ein wesentlicher Bestandteil von Servicetests. Sie dienen dazu zu überprüfen, wie ein System hinsichtlich Reaktionsgeschwindigkeit und Stabilität unter einer bestimmten Last arbeitet. Hier ein Überblick darüber, wie es funktioniert:
- Leistungstests bestehen aus einer Reihe von Tests mit unterschiedlichen Lasten, bei denen das System einen stabilen Zustand erreicht (Belastungen und Antwortzeiten auf konstantem Niveau).
- Wir messen die Auslastung und Reaktionszeiten für jede simulierte Last über einen Zeitraum von 15-30 Minuten, um eine statistisch signifikante Anzahl von Messungen zu erhalten.
- Wir überwachen und protokollieren die Vitalwerte bei jeder simulierten Last. Das sind die verschiedenen Ressourcen unseres Systems, z. B. CPU- und Speichernutzung, Netzwerkbandbreite, I/O-Raten usw.
Wir erstellen ein Diagramm dieser unterschiedlichen Lasten gegenüber den Reaktionszeiten, die unsere „virtuellen“ Benutzer erleben. Aufgetragen sieht unser Diagramm in etwa so aus wie in der untenstehenden Abbildung.
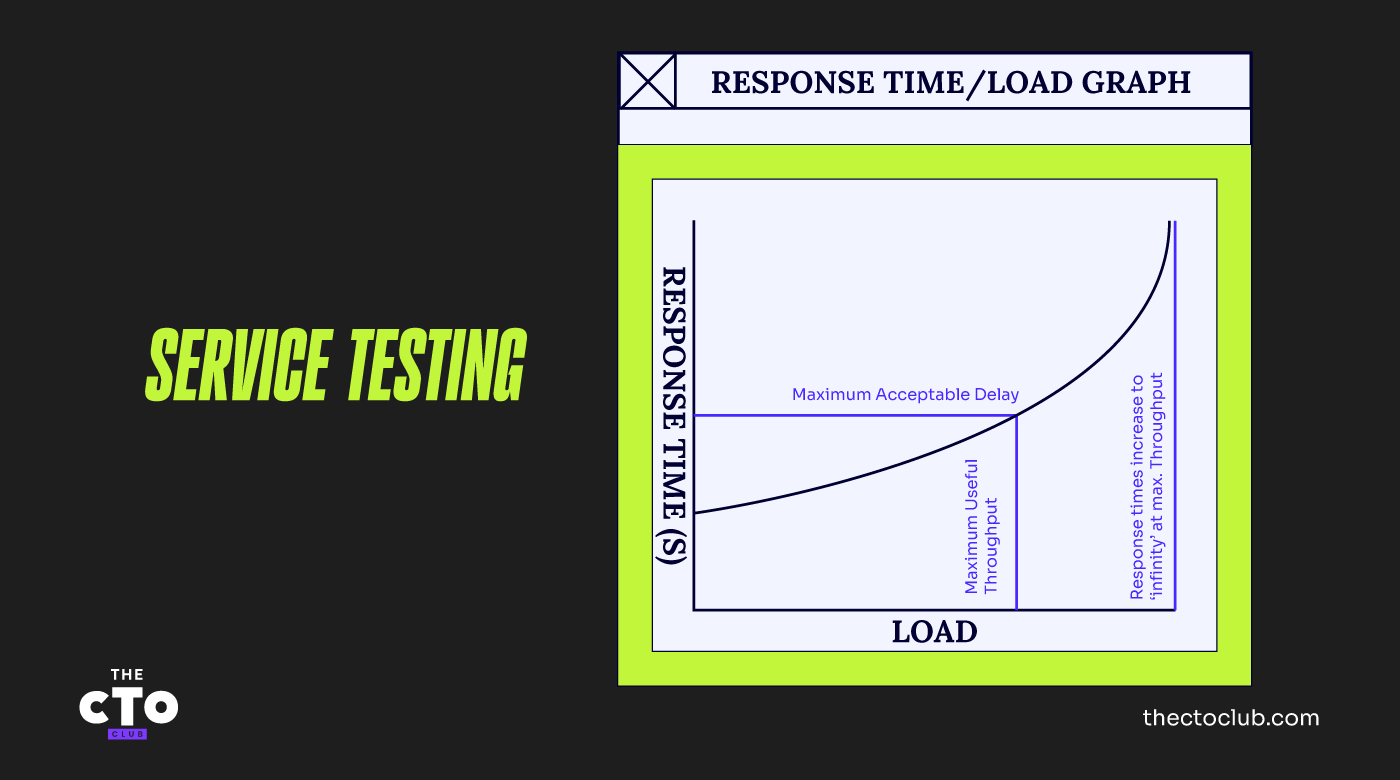
Bei Null-Last, also wenn nur ein einziger Benutzer im System ist, stehen ihm alle Ressourcen zur Verfügung und die Antwortzeiten sind schnell. Steigern wir die Last und messen die Reaktionszeiten, werden diese zunehmend schlechter, bis wir den Punkt erreichen, an dem das System mit maximaler Kapazität läuft.
An diesem Punkt ist die Antwortzeit für unsere Testtransaktionen theoretisch unendlich, weil eine der wichtigsten Ressourcen des Systems vollständig aufgebraucht ist und keine weiteren Transaktionen mehr verarbeitet werden können.
Während wir die Last von Null bis zur Maximalbelastung erhöhen, überwachen wir auch die Nutzung verschiedenster Ressourcentypen, z. B. Auslastung des Serverprozessors, Speichernutzung, Netzwerkbandbreite, Datenbank-Locks und so weiter.
Bei Höchstbelastung ist eine dieser Ressourcen zu 100 % ausgelastet. Diese Ressource ist der begrenzende Faktor, weil sie als erstes erschöpft ist. Natürlich haben sich die Antwortzeiten zu diesem Zeitpunkt so stark verschlechtert, dass sie wahrscheinlich weit unter dem akzeptablen Niveau liegen.
Das nachfolgende Diagramm zeigt die Nutzung/Verfügbarkeit verschiedener Ressourcen in Abhängigkeit von der Last.

Um die Durchsatzkapazität zu erhöhen und/oder die Antwortzeiten eines Systems zu reduzieren, müssen wir Eines der folgenden tun:
- Den Ressourcenbedarf verringern, typischerweise, indem die Software, die die Ressource verwendet, effizienter gestaltet wird (dies ist in der Regel eine Aufgabe der Entwicklung).
- Die Nutzung der Hardware-Ressourcen innerhalb der technischen Architektur optimieren, z. B. indem das DBMS so konfiguriert wird, dass es mehr Daten im Speicher zwischenspeichert, oder indem auf dem Applikationsserver einige Prozesse gegenüber anderen priorisiert werden.
- Mehr Ressourcen verfügbar machen. Dies geschieht in der Regel durch das Hinzufügen von Prozessoren, Speicher, Netzwerkbandbreite usw.
Wie Sie sicher bereits erkannt haben, benötigt Leistungstesten ein Team von Fachleuten zur Unterstützung der Tester. Dazu gehören technische Architekten, Serveradministratoren, Netzwerkadministratoren, Entwickler und Datenbankdesigner/-administratoren. Diese technischen Experten sind qualifiziert, die von den Monitoring-Tools erstellten Statistiken zu analysieren und zu entscheiden, wie die Anwendung angepasst oder das System optimiert oder erweitert werden kann.
Falls Sie selbst Tester sind und kein Spezialist auf diesen Gebieten sind, sollten Sie nicht versuchen, die Statistiken selbst zu deuten und Entscheidungen zur Optimierung und zum Tuning zu treffen. Sie sollten diese Experten frühzeitig ins Projekt einbeziehen, um ihren Rat und ihre Unterstützung zu gewinnen und später, während des Testens, um sicherzustellen, dass Engpässe identifiziert und gelöst werden.
Freuen Sie sich auf den nächsten Artikel, in dem wir noch tiefer in das Management von Leistungstests einsteigen.
Zuverlässigkeits-/Failover-Tests
Die dauerhafte Verfügbarkeit eines Dienstes sicherzustellen, ist vermutlich ein zentrales Ziel Ihres Projekts. Zuverlässigkeitstests helfen, schwer auffindbare Fehler zu entdecken, die unerwartete Ausfälle verursachen. Failover-Tests stellen sicher, dass die vorgesehenen Failover-Maßnahmen für erwartete Ausfälle tatsächlich funktionieren.
Failover-Tests
In Umgebungen, in denen Ausfallsicherheit und/oder Zuverlässigkeit gefordert sind, setzt man häufig auf zuverlässige Systemkomponenten mit integrierten Redundanzen und Failover-Funktionen, die im Fehlerfall aktiviert werden.
Diese Funktionen können unterschiedliche Netzwerkrouten, mehrere zu Clustern verbundene Server, Middleware und verteilte Servicetechnologien umfassen, die Lastverteilung und die Umleitung des Datenverkehrs im Fehlerfall ermöglichen.
Ziel von Failover-Tests ist es, das Verhalten des Systems unter ausgewählten Ausfallszenarien vor der Inbetriebnahme zu testen, was in der Regel folgendes beinhaltet:
- Identifikation der Komponenten, die ausfallen können und einen Dienstverlust verursachen könnten (Betrachtung von Ausfällen von innen nach außen).
- Identifikation der Gefahren, die einen Ausfall verursachen und einen Dienstverlust hervorrufen könnten (Betrachtung von Bedrohungen von außen nach innen).
- Eine Analyse der Fehlermodi oder Szenarien, in denen sichergestellt werden muss, dass die Wiederherstellungsmaßnahme funktioniert.
- Ein automatisierter Test, der genutzt werden kann, um das System zu belasten und das Verhalten des Systems über einen längeren Zeitraum zu untersuchen.
- Der gleiche automatisierte Test kann auch verwendet werden, um das zu testende System unter Last zu setzen und das Verhalten des Systems unter Fehlerbedingungen zu überwachen.
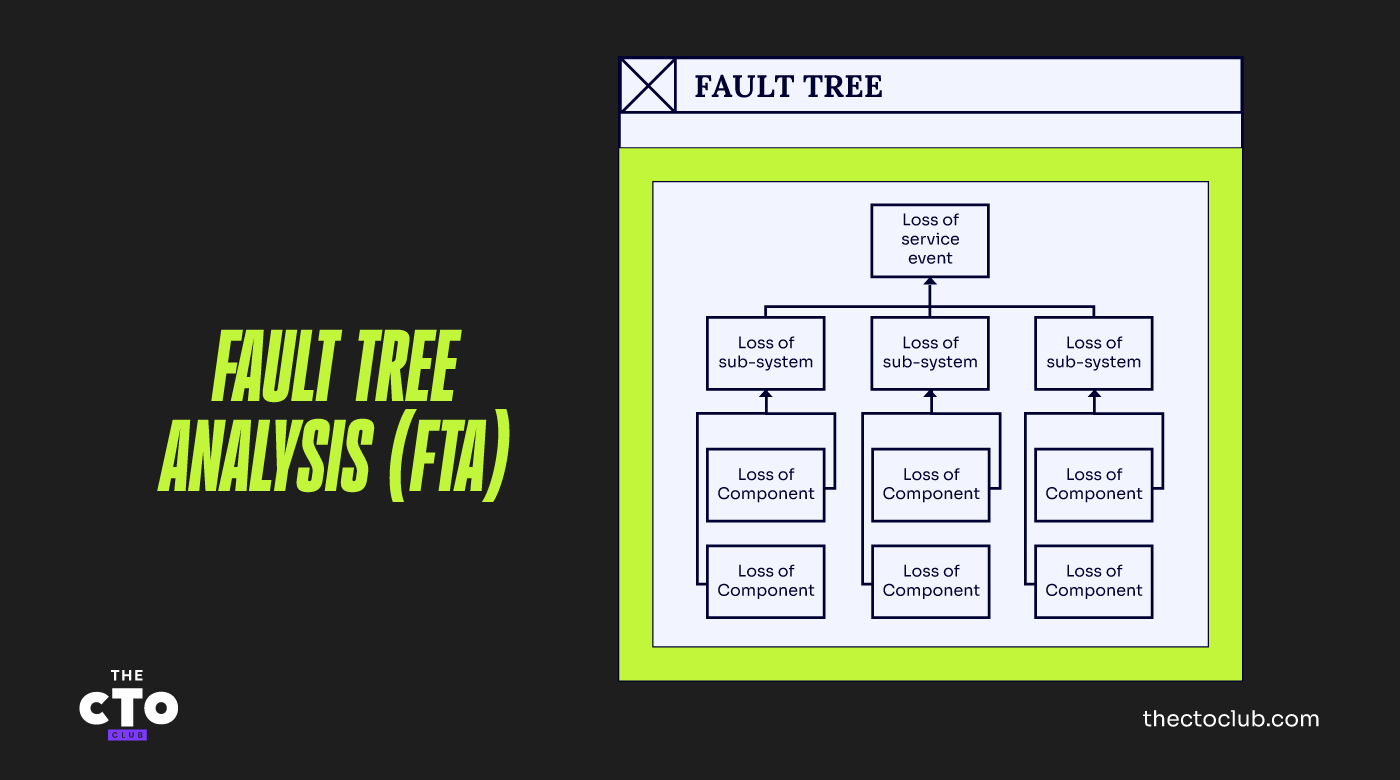
Eine Technik namens Fehlerbaumanalyse (FTA) kann dabei helfen, die Abhängigkeiten eines Dienstes von seinen zugrundeliegenden Komponenten zu verstehen. Fehlerbaumanalyse und Fehlerbaumdiagramme stellen eine logische Repräsentation eines Systems oder Dienstes sowie der Arten dar, auf die dieses ausfallen kann.
Das untenstehende einfache Schaubild zeigt die Beziehung zwischen grundlegenden Komponenten-Ausfallereignissen, zwischengeordneten Teilsystem-Ausfallereignissen und dem obersten Service-Ausfallereignis. Natürlich ist es möglich, mehr als drei Ebenen von Ausfallereignissen zu identifizieren.
Diese Tests müssen mit einer automatisierten Last ausgeführt werden, um das Verhalten des Systems in Produktsituationen zu untersuchen und Vertrauen in die eingebauten Wiederherstellungsmaßnahmen zu gewinnen. Besonders möchte man wissen:
- Wie verhält sich die Architektur in Ausfallsituationen?
- Funktionieren die Lastverteilungsmechanismen korrekt?
- Können Ausfallsicherheitsmechanismen die Last abfangen, wenn eine Komponente ausfällt?
- Funktioniert die automatische Wiederherstellung? "Holen" nachgestartete Systeme wieder auf?
Letztlich konzentrieren sich die Tests darauf, herauszufinden, ob der Service für Endnutzer aufrechterhalten wird und ob die Nutzer den Ausfall tatsächlich bemerken.
Zuverlässigkeitstests (oder Soak-Tests)
Zuverlässigkeitstests zielen darauf ab, zu prüfen, dass unter Last keine Fehler auftreten.
Die meisten Hardware-Komponenten sind so zuverlässig, dass ihre mittlere Zeit zwischen Ausfällen in Jahren gemessen werden kann. Zuverlässigkeitstests erfordern die Nutzung (oder Wiederverwendung) automatisierter Tests auf zwei Arten zur Simulation von:
- Extremen Lasten auf spezifische Komponenten oder Ressourcen der technischen Architektur.
- Längeren Zeiträumen mit normalen (oder extremen) Lasten auf dem Gesamtsystem.
Wenn man sich auf einzelne Komponenten fokussiert, will man die Komponente durch eine unangemessen hohe Anzahl von Anfragen zu ihrer Hauptfunktion belasten. Oft ist es einfacher, kritische Komponenten zunächst isoliert mit einer großen Anzahl einfacher Anfragen zu stresstesten, bevor man deutlich komplexere Tests auf die gesamte Infrastruktur anwendet. Es gibt auch speziell entwickelte Stresstest-Tools, mit denen QAs den Prozess leichter durchführen können.
Soak-Tests sind Tests, die ein System über einen längeren Zeitraum, etwa 24, 48 Stunden oder länger, einer Last aussetzen, um (meist) schwer erkennbare Probleme zu entdecken. Solche Fehler treten häufig erst nach längerem Betrieb auf.
Der automatisierte Test muss dabei nicht unbedingt auf Extrembelastung hochgefahren werden (dafür gibt es Stresstests). Besonders interessiert uns aber die Fähigkeit des Systems, einem kontinuierlichen Betrieb mit einer großen Vielzahl von Testtransaktionen standzuhalten, um festzustellen, ob es versteckte Speicherlecks, Verriegelungen oder Race Conditions gibt.
Service-Management-Tests
Abschließend ein Wort zu Service-Management-Tests.
Wenn der Service produktiv eingesetzt wird, muss er verwaltet werden. Ein Dienst muss überwacht, aktualisiert, gesichert und bei Problemen schnell wiederhergestellt werden, um dauerhaft verfügbar zu bleiben.
Die Verfahren, die Service-Manager verwenden, um Upgrades, Backups, Releases und die Wiederherstellung nach Ausfällen durchzuführen, sind entscheidend für einen zuverlässigen Service und müssen getestet werden, besonders wenn der Service nach der Einführung häufig geändert wird.
Die zu behebenden speziellen Probleme sind:
- Verfahren erreichen nicht die gewünschte Wirkung.
- Verfahren sind nicht umsetzbar oder nicht praktikabel.
- Verfahren beeinträchtigen den laufenden Service.
Die Tests sollten so realistisch wie möglich durchgeführt werden.
Ein Denkanstoß
Einige Systeme sind anfällig für extreme Lasten, wenn bestimmte Ereignisse eintreten. Ein Online-Unternehmen etwa rechnet mit Spitzenlasten direkt nachdem Angebote im Fernsehen beworben werden, oder eine nationale Nachrichten-Website kann nach einer großen Nachrichtenmeldung überlastet werden.
Denk an ein System, das du gut kennst, das von ungeplanten Störungen in deinem Unternehmen oder durch eine nationale Meldung betroffen war.
Welche Zwischenfälle oder Ereignisse könnten Spitzenlasten in Ihrem System auslösen?
Können (oder könnten) Sie Daten aus Systemprotokollen erfassen, die Aufschluss über die Anzahl der ausgeführten Transaktionen geben? Können Sie dieses Ereignis skalieren, um ein einmaliges kritisches Ereignis in 100 oder sogar 1.000 Jahren vorherzusagen?
Welche Maßnahmen könnten Sie ergreifen (oder haben Sie bereits ergriffen), um entweder die Wahrscheinlichkeit von Spitzen, das Ausmaß der Spitzen zu reduzieren oder sie ganz zu vermeiden?
Melden Sie sich für den Newsletter von The QA Lead an, um benachrichtigt zu werden, wenn neue Teile dieser Serie erscheinen. Diese Beiträge sind Auszüge aus Pauls Leadership-In-Test-Kurs, den wir Ihnen wärmstens empfehlen, wenn Sie noch tiefer in dieses und andere Themen eintauchen möchten. Falls Sie sich anmelden, verwenden Sie unseren exklusiven Gutscheincode QALEADOFFER, um $60 Rabatt auf den vollen Kurspreis zu erhalten!
Empfohlene Lektüre: 10 BESTE OPEN-SOURCE-TESTMANAGEMENT-TOOLS

{kind=link}