Liderazgo en Pruebas: Pruebas de Servicio

Nota del editor: Bienvenido a la serie Liderazgo en Testing del gurú y consultor de pruebas de software Paul Gerrard. La serie está diseñada para ayudar a testers con algunos años de experiencia—especialmente a quienes trabajan en equipos ágiles—a destacar en sus roles de líder y gestión de pruebas.
En el artículo anterior, vimos el cambio en el rol de los testers y cómo fomentar una mejor colaboración con tus colegas. En este artículo, profundizaremos en los aspectos fundamentales de las pruebas de rendimiento, fiabilidad y gestionabilidad de una aplicación web. Es decir, pruebas de servicio.
Suscríbete al boletín de The QA Lead para enterarte cuando se publiquen nuevas entregas de la serie. Estas publicaciones son extractos del curso Leadership In Test de Paul, que recomendamos para profundizar en este y otros temas. Si te apuntas, usa nuestro cupón exclusivo QALEADOFFER para obtener $60 de descuento sobre el precio completo del curso.
Hola y bienvenido a otro capítulo de la serie Liderazgo en Testing. Esta semana veremos las pruebas de servicio para aplicaciones web. Cubriremos:
- ¿Qué son las pruebas de servicio?
- ¿Qué es la prueba de rendimiento?
- Pruebas de fiabilidad/recuperación ante fallos
- Pruebas de gestión del servicio
Comencemos.
¿Qué son las pruebas de servicio?
La calidad del servicio que provee una aplicación web podría definirse como la suma de todas sus propiedades, como funcionalidad, rendimiento, fiabilidad, usabilidad, seguridad y así sucesivamente.
Sin embargo, para nuestros propósitos aquí, separamos tres objetivos de servicio particulares que se examinan en lo que llamaremos “pruebas de servicio”. Estos objetivos son:
- Rendimiento: el servicio debe ser ágil en sus respuestas a los usuarios mientras soporta las cargas que se le imponen.
- Fiabilidad: si fue diseñado para ser resistente a fallos, el servicio debe ser fiable y/o continuar prestando el servicio incluso cuando suceda un fallo.
- Gestionabilidad: el servicio debe ser gestionable, configurable o modificable sin que los usuarios finales noten una degradación en el servicio. La gestionabilidad, o pruebas de operaciones, busca demostrar que los procedimientos de administración del sistema, gestión, respaldo y recuperación funcionan de forma eficaz.
En los tres casos, es necesario simular una carga de usuarios para realizar las pruebas de manera efectiva. Los objetivos de rendimiento, fiabilidad y gestionabilidad existen en el contexto de clientes reales usando el sitio para hacer negocios.
La capacidad de respuesta (en este caso, el tiempo que tarda un nodo del sistema en responder a la petición de otro) de un sitio está directamente relacionada con los recursos disponibles en la arquitectura técnica.
A medida que más clientes utilizan el servicio, menos recursos técnicos están disponibles para atender las solicitudes de cada usuario y los tiempos de respuesta se degradan.
Obviamente, un servicio con poca carga tiene menos probabilidad de fallar. Gran parte de la complejidad del software y hardware existe para cubrir la demanda de recursos dentro de la arquitectura técnica cuando el sitio recibe mucha carga.
Cuando un sitio está cargado (o sobrecargado), las múltiples solicitudes de recursos deben gestionarse por medio de diversos componentes de la infraestructura, como sistemas operativos de servidores y redes, sistemas de gestión de bases de datos, productos de servidores web, intermediarios de solicitudes de objetos, middleware, etc.
Estos componentes de infraestructura suelen ser más fiables que el código de la aplicación desarrollado a medida que demanda el recurso, pero pueden producirse fallos en cualquiera de los dos:
- Fallo de componentes de infraestructura porque el código de la aplicación (por mal diseño o implementación) exige recursos en exceso.
- Los componentes de la aplicación pueden fallar porque los recursos que requieren no siempre están disponibles (a tiempo).
Simulando cargas de producción típicas y atípicas durante periodos prolongados, los testers pueden revelar errores de diseño o implementación en el sistema. Cuando estos fallos se solucionan, las mismas pruebas demostrarán la resiliencia del sistema. Los QA pueden aprovechar herramientas de pruebas de carga para ejecutar muchos de los procesos definidos a continuación.
En todo servicio, normalmente hay ciertos procesos críticos de gestión que deben realizarse para que el servicio funcione fluidamente. Puede ser posible detener el servicio para mantenimiento rutinario fuera del horario laboral, pero la mayoría de los servicios online operan las 24 horas.
El día laboral del servicio nunca termina. Inevitablemente, los procedimientos de gestión deben llevarse a cabo mientras el servicio está activo y los usuarios están en el sistema. Estos procedimientos deben probarse bajo carga del sistema para asegurar que no afectan negativamente al servicio en vivo, es decir, pruebas de rendimiento.

¿Qué es la prueba de rendimiento?
La prueba de rendimiento es un componente clave de las pruebas de servicio. Es una manera de evaluar cómo se comporta un sistema en términos de capacidad de respuesta y estabilidad bajo una carga de trabajo específica. Aquí tienes una visión general de cómo funciona:
- La prueba de rendimiento consiste en una gama de pruebas con diferentes cargas donde el sistema alcanza un estado estable (las cargas y los tiempos de respuesta se mantienen constantes).
- Medimos la carga y los tiempos de respuesta para cada carga, simulados durante un período de 15 a 30 minutos, para obtener una cantidad estadísticamente significativa de mediciones.
- Monitorizamos y registramos los signos vitales para cada carga simulada. Estos son los distintos recursos de nuestro sistema, por ejemplo: uso de CPU y memoria, ancho de banda de red, tasas de entrada/salida, etc.
Trazamos un gráfico de estas cargas variables frente a los tiempos de respuesta experimentados por nuestros usuarios “virtuales”. Al graficarlo, nuestro gráfico se asemeja a la figura de abajo.
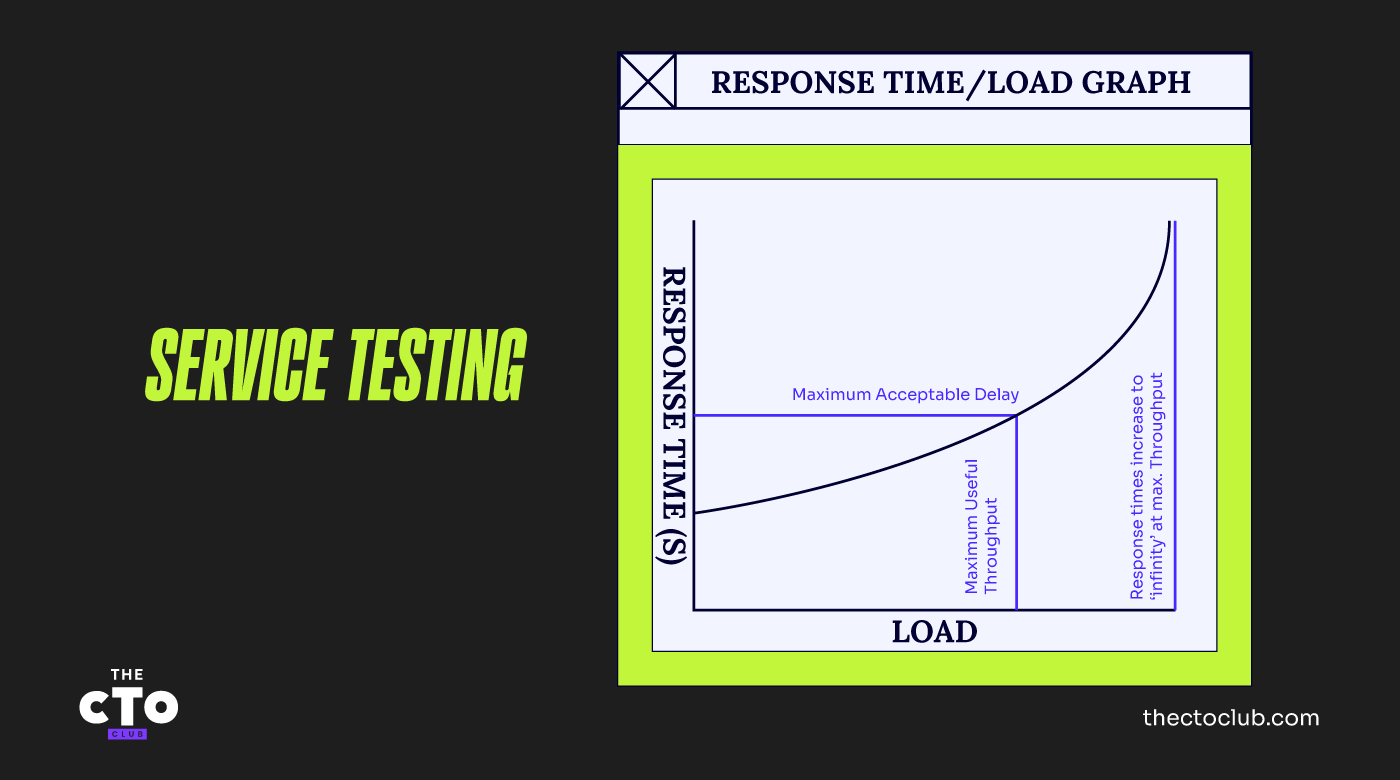
Con carga cero, donde sólo hay un usuario en el sistema, éste tiene todo el recurso para sí y los tiempos de respuesta son rápidos. A medida que introducimos cargas crecientes y medimos los tiempos de respuesta, estos empeoran progresivamente hasta que alcanzamos un punto en el que el sistema funciona a máxima capacidad.
En este punto, el tiempo de respuesta para nuestras transacciones de prueba es teóricamente infinito porque uno de los recursos clave del sistema está completamente agotado y no pueden procesarse más transacciones.
A medida que incrementamos las cargas desde cero hasta el máximo, también monitorizamos el uso de varios tipos de recursos, por ejemplo: uso del procesador del servidor, uso de memoria, ancho de banda de red, bloqueos de base de datos, y demás.
En la carga máxima, uno de estos recursos está saturado al 100%. Este recurso es el recurso limitante porque es el primero en agotarse. Por supuesto, en este punto los tiempos de respuesta han degradado hasta un nivel probablemente mucho más lento de lo que sería aceptable.
El siguiente gráfico muestra el uso/disponibilidad de varios recursos graficados contra la carga.

Para aumentar la capacidad de procesamiento y/o reducir los tiempos de respuesta de un sistema, debemos hacer una de las siguientes cosas:
- Reducir la demanda del recurso, normalmente haciendo que el software que utiliza el recurso sea más eficiente (esto suele ser responsabilidad del desarrollo).
- Optimizar el uso del recurso de hardware dentro de la arquitectura técnica, por ejemplo configurando el SGBD para cachear más datos en memoria o dando prioridad a ciertos procesos sobre otros en el servidor de aplicaciones.
- Disponer de más cantidad de un recurso. Normalmente añadiendo procesadores, memoria o ancho de banda de red, etc.
Como sin duda ya te estarás dando cuenta, las pruebas de rendimiento necesitan de un equipo de personas para ayudar a los testers. Estos son los arquitectos técnicos, administradores de servidores, administradores de red, desarrolladores y diseñadores/administradores de bases de datos. Estos expertos técnicos están cualificados para analizar las estadísticas generadas por las herramientas de monitorización de recursos y decidir la mejor manera de ajustar la aplicación, o afinar o actualizar el sistema.
Si eres el tester y no eres un experto en estos campos, no te dejes tentar por fingir que puedes interpretar estas estadísticas y tomar decisiones de ajuste y optimización. Necesitarás involucrar a estos expertos desde el principio del proyecto para obtener su asesoramiento e implicación y después, durante las pruebas, para asegurar que los cuellos de botella sean identificados y solucionados.
Espera al próximo artículo, donde profundizaremos en cómo gestionar las pruebas de rendimiento.
Pruebas de fiabilidad y conmutación por error
Asegurar la disponibilidad continua de un servicio probablemente sea un objetivo clave de tu proyecto. Las pruebas de fiabilidad ayudan a detectar fallos poco frecuentes que provocan fallos inesperados. Las pruebas de conmutación por error ayudan a garantizar que las medidas de conmutación diseñadas para fallos anticipados realmente funcionen.
Pruebas de conmutación por error
Cuando se requiere que los sitios sean resilientes y/o fiables, suelen diseñarse con componentes de sistema fiables con redundancia y funciones de conmutación por error incorporadas que entran en juego cuando se producen fallos.
Estos elementos pueden incluir rutas de red alternativas, varios servidores configurados en clústeres, tecnologías de middleware y servicios distribuidos que gestionan el balanceo de carga y el redireccionamiento del tráfico en escenarios de fallo.
Las pruebas de conmutación por error tienen como objetivo explorar el comportamiento del sistema bajo escenarios de fallos seleccionados antes del despliegue y normalmente incluyen lo siguiente:
- Identificación de los componentes que podrían fallar y causar una pérdida de servicio (analizando las fallas desde adentro hacia afuera).
- Identificación de los peligros que podrían provocar una falla y causar una pérdida de servicio (observando las amenazas desde afuera hacia adentro).
- Análisis de los modos o escenarios de fallo que podrían ocurrir donde es necesario tener confianza en que la medida de recuperación funcionará.
- Una prueba automatizada que se puede usar para cargar el sistema y explorar el comportamiento del sistema durante un periodo prolongado.
- La misma prueba automatizada también puede utilizarse para someter a carga el sistema bajo prueba y monitorizar el comportamiento del sistema bajo condiciones de fallo.
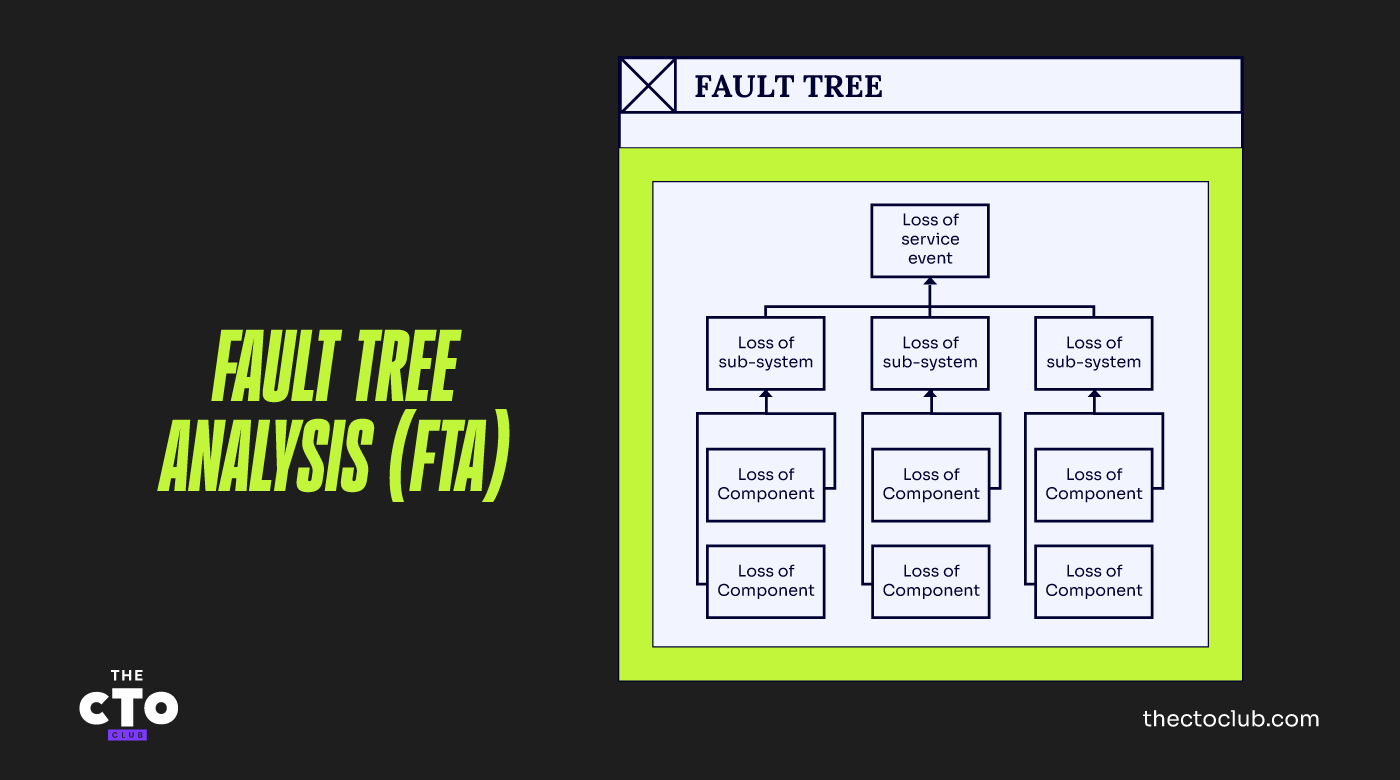
Una técnica llamada Análisis de Árbol de Fallas (FTA, por sus siglas en inglés) puede ayudarte a entender las dependencias del servicio sobre sus componentes subyacentes. El análisis de árbol de fallas y los diagramas de árbol de fallas son una representación lógica de un sistema o servicio y de las formas en que pueden fallar.
El esquema simple que aparece a continuación muestra la relación entre los eventos básicos de fallo de componentes, los eventos intermedios de fallo de subsistemas y el evento superior de fallo del servicio. Por supuesto, podría ser posible identificar más de tres niveles de eventos de fallo.
Estas pruebas necesitan ejecutarse con una carga automatizada para poder explorar el comportamiento del sistema en situaciones de producción y ganar confianza en las medidas de recuperación incorporadas en el diseño. En particular, deseas saber:
- ¿Cómo se comporta la arquitectura en situaciones de fallo?
- ¿Funcionan correctamente las facilidades de balanceo de carga?
- ¿Las capacidades de conmutación por error absorben la carga cuando falla un componente?
- ¿Opera la recuperación automática? ¿Los sistemas reiniciados “se ponen al día”?
En última instancia, las pruebas se enfocan en determinar si el servicio para los usuarios finales se mantiene y si los usuarios realmente notan o no que ha ocurrido una falla.
Pruebas de confiabilidad (o de resistencia prolongada)
Las pruebas de confiabilidad tienen como objetivo comprobar que no ocurran fallos bajo carga.
La mayoría de los componentes de hardware son confiables al grado de que su tiempo medio entre fallos puede ser medido en años. Las pruebas de confiabilidad requieren el uso (o reutilización) de pruebas automatizadas de dos maneras para simular:
- Cargas extremas sobre componentes o recursos específicos en la arquitectura técnica.
- Períodos prolongados de cargas normales (o extremas) en el sistema completo.
Al centrarnos en componentes específicos, buscamos estresar el componente sometiéndolo a una cantidad irrazonablemente grande de solicitudes para realizar su función diseñada. A menudo resulta más sencillo poner a prueba los componentes críticos en aislamiento con grandes cantidades de solicitudes simples antes de aplicar una prueba más compleja a toda la infraestructura. También existen herramientas especialmente diseñadas para pruebas de estrés que facilitan la ejecución para los equipos de QA.
Las pruebas de resistencia prolongada (soak tests) son pruebas que someten a un sistema a una carga durante un periodo extendido, quizá de 24, 48 horas o más, para encontrar problemas (que usualmente) son difíciles de detectar. Los fallos poco comunes a menudo sólo se manifiestan después de un periodo prolongado de uso.
La prueba automatizada no requiere necesariamente aumentar la carga a máximos extremos (ya que esa es la función de las pruebas de estrés). Pero nos interesa particularmente la capacidad del sistema para resistir la ejecución continua de una amplia variedad de transacciones de prueba y descubrir si existen pérdidas de memoria difíciles de encontrar, bloqueos o condiciones de carrera.
Pruebas de Gestión de Servicios
Por último, unas palabras sobre las pruebas de gestión de servicios.
Cuando el servicio se despliega en producción, debe ser gestionado. Mantener un servicio funcionando requiere que sea monitorizado, actualizado, respaldado y reparado rápidamente cuando algo falla.
Los procedimientos que utilizan los responsables del servicio para realizar actualizaciones, copias de seguridad, despliegues y restauraciones tras fallas son críticos para ofrecer un servicio fiable, por eso necesitan pruebas, especialmente si el servicio sufrirá cambios rápidos después del despliegue.
Los problemas concretos a abordar son:
- Los procedimientos no logran el efecto deseado.
- Los procedimientos son inviables o inutilizables.
- Los procedimientos interrumpen el servicio en curso.
Las pruebas deben, en la medida de lo posible, realizarse de la manera más realista posible.
Para Reflexionar
Algunos sistemas son propensos a cargas extremas cuando ocurre un cierto evento. Por ejemplo, un negocio en línea esperaría picos de tráfico justo después de anunciar una oferta en televisión, o un portal de noticias nacional podría verse saturado cuando estalla una gran noticia.
Piensa en un sistema que conozcas bien y que se haya visto afectado por incidentes imprevistos en tu empresa o en las noticias nacionales.
¿Qué incidentes o eventos podrían provocar cargas excesivas en su sistema?
¿Puede (o podría) capturar datos de los registros del sistema que le indiquen el número de transacciones ejecutadas? ¿Puede escalar este evento para predecir un evento crítico que ocurra una vez cada 100 años o una vez cada 1,000 años?
¿Qué medidas podría aplicar (o ha aplicado) para reducir la probabilidad de picos, la magnitud de los picos, o eliminarlos por completo?
Suscríbase al boletín de The QA Lead para recibir notificaciones cuando se publiquen nuevas partes de la serie. Estas publicaciones son extractos del curso Liderazgo en Pruebas de Paul, que le recomendamos mucho para profundizar en este y otros temas. Si decide inscribirse, ¡use nuestro código de cupón exclusivo QALEADOFFER para obtener $60 de descuento en el precio total del curso!
Lectura sugerida: LAS 10 MEJORES HERRAMIENTAS DE GESTIÓN DE PRUEBAS OPEN SOURCE



{kind=link}